 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTSI: an Ad Text Strength Indicator using Text-to-CTR and Semantic-Ad-Similarity
Aug 18, 2021
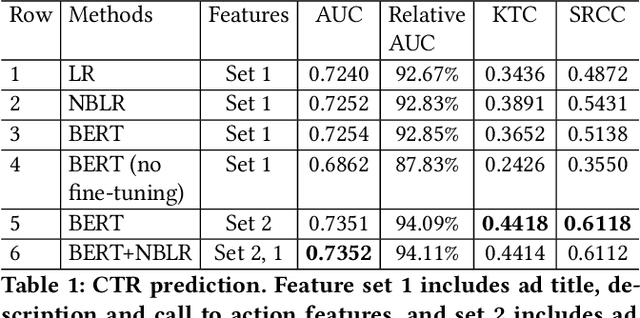

Coming up with effective ad text is a time consuming process, and particularly challenging for small businesses with limited advertising experience. When an inexperienced advertiser onboards with a poorly written ad text, the ad platform has the opportunity to detect low performing ad text, and provide improvement suggestions. To realize this opportunity, we propose an ad text strength indicator (TSI) which: (i) predicts the click-through-rate (CTR) for an input ad text, (ii) fetches similar existing ads to create a neighborhood around the input ad, (iii) and compares the predicted CTRs in the neighborhood to declare whether the input ad is strong or weak. In addition, as suggestions for ad text improvement, TSI shows anonymized versions of superior ads (higher predicted CTR) in the neighborhood. For (i), we propose a BERT based text-to-CTR model trained on impressions and clicks associated with an ad text. For (ii), we propose a sentence-BERT based semantic-ad-similarity model trained using weak labels from ad campaign setup data. Offline experiments demonstrate that our BERT based text-to-CTR model achieves a significant lift in CTR prediction AUC for cold start (new) advertisers compared to bag-of-words based baselines. In addition, our semantic-textual-similarity model for similar ads retrieval achieves a precision@1 of 0.93 (for retrieving ads from the same product category); this is significantly higher compared to unsupervised TF-IDF, word2vec, and sentence-BERT baselines. Finally, we share promising online results from advertisers in the Yahoo (Verizon Media) ad platform where a variant of TSI was implemented with sub-second end-to-end latency.
Powering COVID-19 community Q&A with Curated Side Information
Jan 27, 2021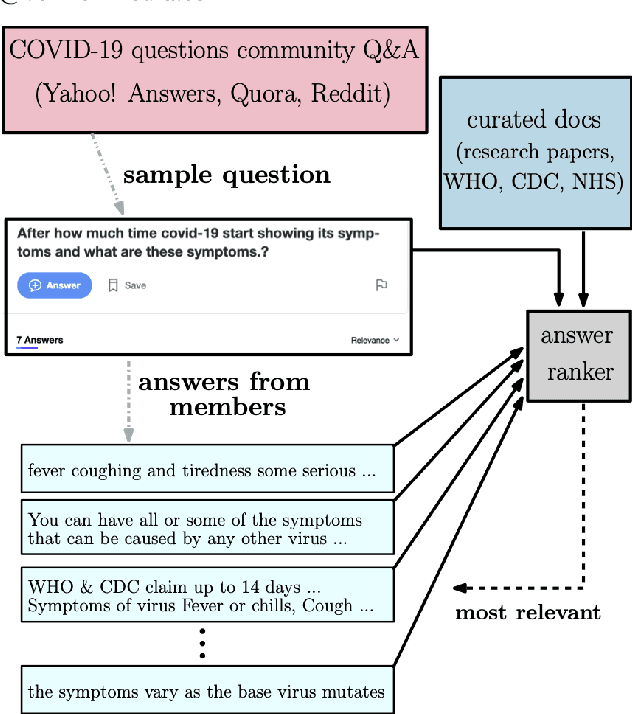

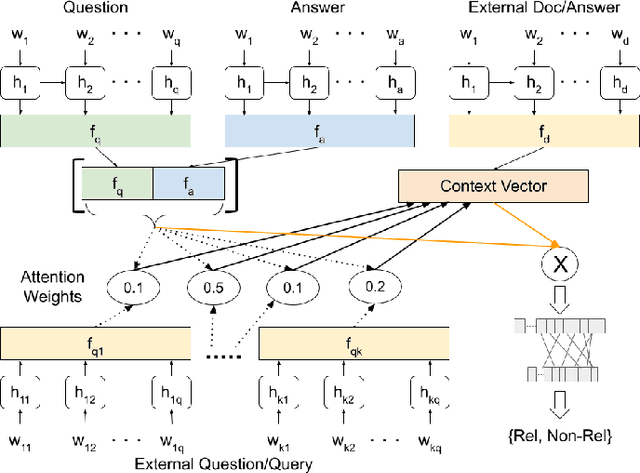
Community question answering and discussion platforms such as Reddit, Yahoo! answers or Quora provide users the flexibility of asking open ended questions to a large audience, and replies to such questions maybe useful both to the user and the community on certain topics such as health, sports or finance. Given the recent events around COVID-19, some of these platforms have attracted 2000+ questions from users about several aspects associated with the disease. Given the impact of this disease on general public, in this work we investigate ways to improve the ranking of user generated answers on COVID-19. We specifically explore the utility of external technical sources of side information (such as CDC guidelines or WHO FAQs) in improving answer ranking on such platforms. We found that ranking user answers based on question-answer similarity is not sufficient, and existing models cannot effectively exploit external (side) information. In this work, we demonstrate the effectiveness of different attention based neural models that can directly exploit side information available in technical documents or verified forums (e.g., research publications on COVID-19 or WHO website). Augmented with a temperature mechanism, the attention based neural models can selectively determine the relevance of side information for a given user question, while ranking answers.
Match Them Up: Visually Explainable Few-shot Image Classification
Nov 25, 2020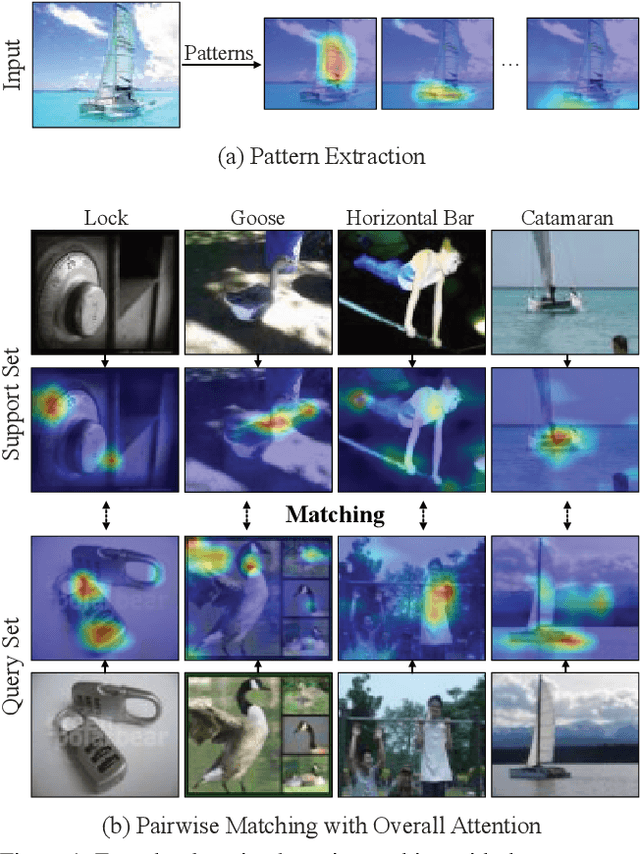
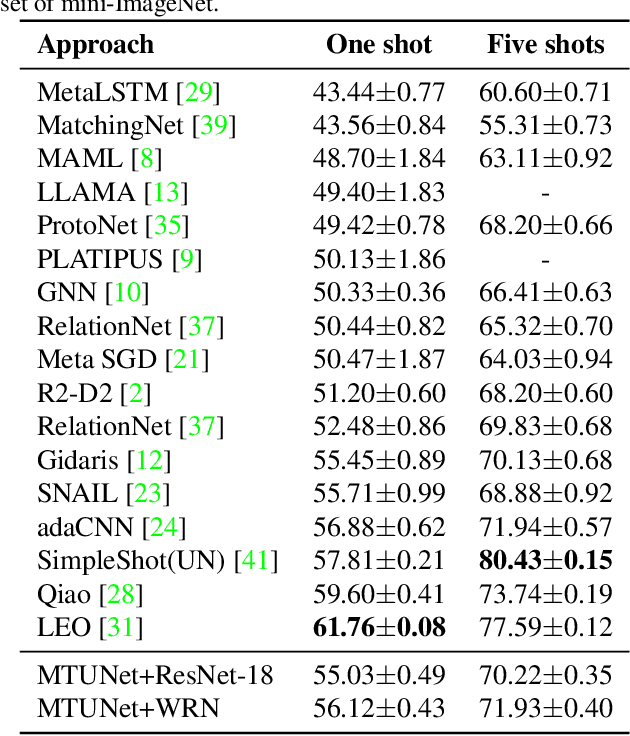
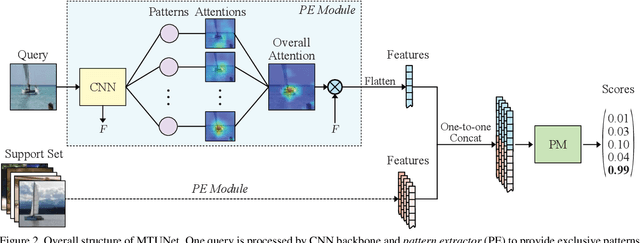
Few-shot learning (FSL) approaches are usually based on an assumption that the pre-trained knowledge can be obtained from base (seen) categories and can be well transferred to novel (unseen) categories. However, there is no guarantee, especially for the latter part. This issue leads to the unknown nature of the inference process in most FSL methods, which hampers its application in some risk-sensitive areas. In this paper, we reveal a new way to perform FSL for image classification, using visual representations from the backbone model and weights generated by a newly-emerged explainable classifier. The weighted representations only include a minimum number of distinguishable features and the visualized weights can serve as an informative hint for the FSL process. Finally, a discriminator will compare the representations of each pair of the images in the support set and the query set. Pairs with the highest scores will decide the classification results. Experimental results prove that the proposed method can achieve both good accuracy and satisfactory explainability on three mainstream datasets.
Grading the Severity of Arteriolosclerosis from Retinal Arterio-venous Crossing Patterns
Nov 07, 2020
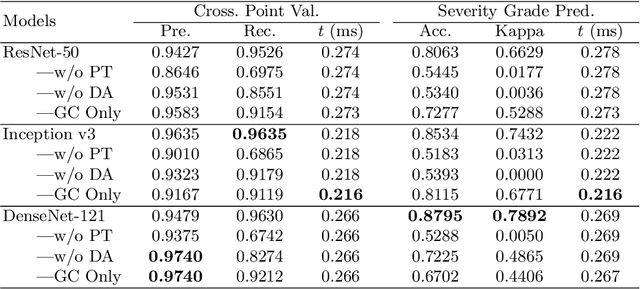
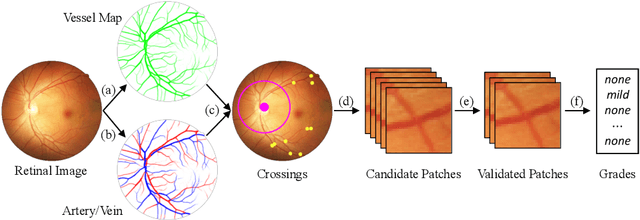
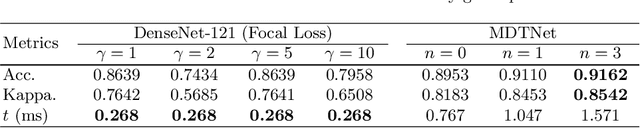
The status of retinal arteriovenous crossing is of great significance for clinical evaluation of arteriolosclerosis and systemic hypertension. As an ophthalmology diagnostic criteria, Scheie's classification has been used to grade the severity of arteriolosclerosis. In this paper, we propose a deep learning approach to support the diagnosis process, which, to the best of our knowledge, is one of the earliest attempts in medical imaging. The proposed pipeline is three-fold. First, we adopt segmentation and classification models to automatically obtain vessels in a retinal image with the corresponding artery/vein labels and find candidate arteriovenous crossing points. Second, we use a classification model to validate the true crossing point. At last, the grade of severity for the vessel crossings is classified. To better address the problem of label ambiguity and imbalanced label distribution, we propose a new model, named multi-diagnosis team network (MDTNet), in which the sub-models with different structures or different loss functions provide different decisions. MDTNet unifies these diverse theories to give the final decision with high accuracy. Our severity grading method was able to validate crossing points with precision and recall of 96.3% and 96.3%, respectively. Among correctly detected crossing points, the kappa value for the agreement between the grading by a retina specialist and the estimated score was 0.85, with an accuracy of 0.92. The numerical results demonstrate that our method can achieve a good performance in both arteriovenous crossing validation and severity grading tasks. By the proposed models, we could build a pipeline reproducing retina specialist's subjective grading without feature extractions. The code is available for reproducibility.
SCOUTER: Slot Attention-based Classifier for Explainable Image Recognition
Sep 14, 2020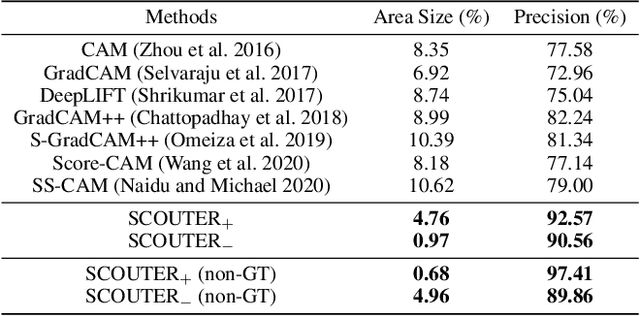



Explainable artificial intelligence is gaining attention. However, most existing methods are based on gradients or intermediate features, which are not directly involved in the decision-making process of the classifier. In this paper, we propose a slot attention-based light-weighted classifier called SCOUTER for transparent yet accurate classification. Two major differences from other attention-based methods include: (a) SCOUTER's explanation involves the final confidence for each category, offering more intuitive interpretation, and (b) all the categories have their corresponding positive or negative explanation, which tells "why the image is of a certain category" or "why the image is not of a certain category." We design a new loss tailored for SCOUTER that controls the model's behavior to switch between positive and negative explanations, as well as the size of explanatory regions. Experimental results show that SCOUTER can give better visual explanations while keeping good accuracy on a large dataset.
Learning to Create Better Ads: Generation and Ranking Approaches for Ad Creative Refinement
Aug 17, 2020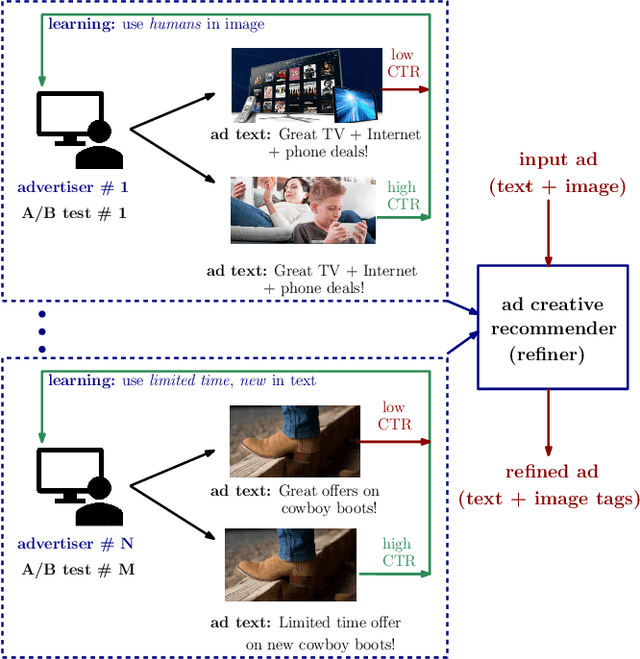
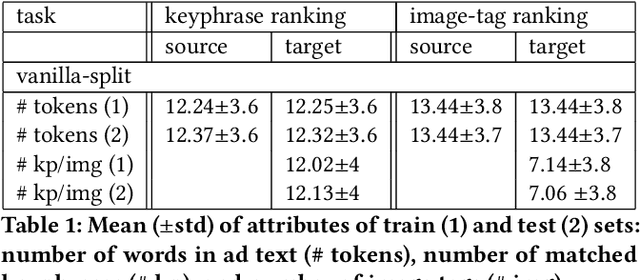
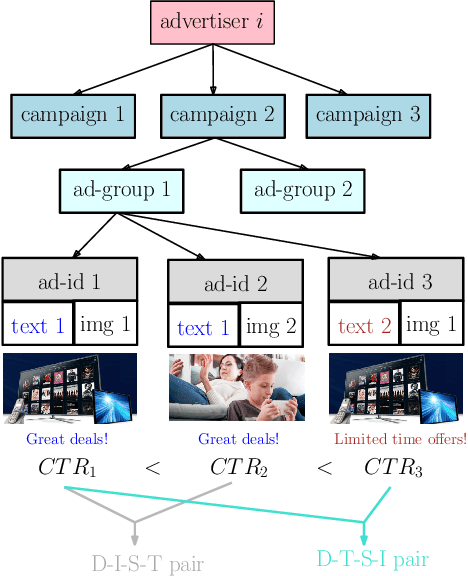
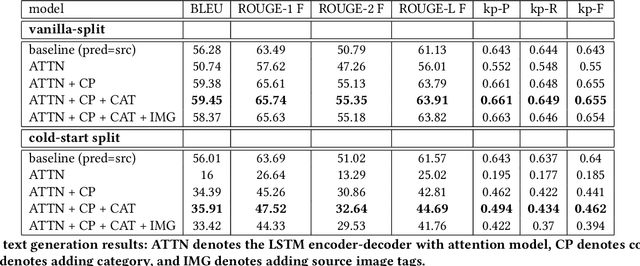
In the online advertising industry, the process of designing an ad creative (i.e., ad text and image) requires manual labor. Typically, each advertiser launches multiple creatives via online A/B tests to infer effective creatives for the target audience, that are then refined further in an iterative fashion. Due to the manual nature of this process, it is time-consuming to learn, refine, and deploy the modified creatives. Since major ad platforms typically run A/B tests for multiple advertisers in parallel, we explore the possibility of collaboratively learning ad creative refinement via A/B tests of multiple advertisers. In particular, given an input ad creative, we study approaches to refine the given ad text and image by: (i) generating new ad text, (ii) recommending keyphrases for new ad text, and (iii) recommending image tags (objects in image) to select new ad image. Based on A/B tests conducted by multiple advertisers, we form pairwise examples of inferior and superior ad creatives, and use such pairs to train models for the above tasks. For generating new ad text, we demonstrate the efficacy of an encoder-decoder architecture with copy mechanism, which allows some words from the (inferior) input text to be copied to the output while incorporating new words associated with higher click-through-rate. For the keyphrase and image tag recommendation task, we demonstrate the efficacy of a deep relevance matching model, as well as the relative robustness of ranking approaches compared to ad text generation in cold-start scenarios with unseen advertisers. We also share broadly applicable insights from our experiments using data from the Yahoo Gemini ad platform.
Depthwise Spatio-Temporal STFT Convolutional Neural Networks for Human Action Recognition
Jul 22, 2020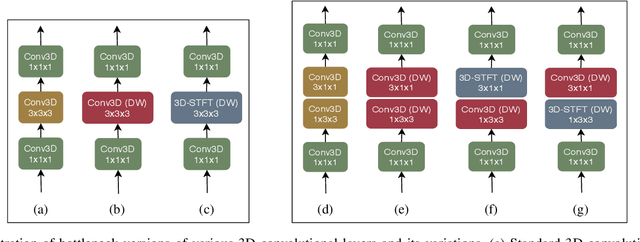
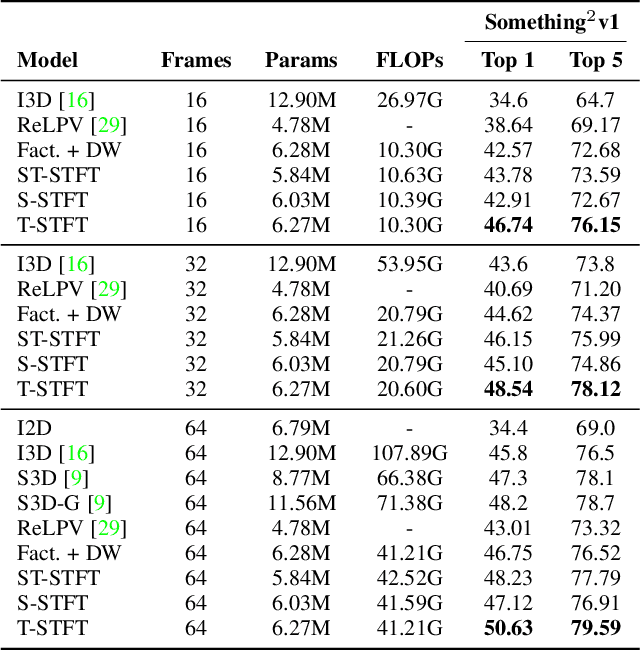
Conventional 3D convolutional neural networks (CNNs) are computationally expensive, memory intensive, prone to overfitting, and most importantly, there is a need to improve their feature learning capabilities. To address these issues, we propose spatio-temporal short term Fourier transform (STFT) blocks, a new class of convolutional blocks that can serve as an alternative to the 3D convolutional layer and its variants in 3D CNNs. An STFT block consists of non-trainable convolution layers that capture spatially and/or temporally local Fourier information using a STFT kernel at multiple low frequency points, followed by a set of trainable linear weights for learning channel correlations. The STFT blocks significantly reduce the space-time complexity in 3D CNNs. In general, they use 3.5 to 4.5 times less parameters and 1.5 to 1.8 times less computational costs when compared to the state-of-the-art methods. Furthermore, their feature learning capabilities are significantly better than the conventional 3D convolutional layer and its variants. Our extensive evaluation on seven action recognition datasets, including Something-something v1 and v2, Jester, Diving-48, Kinetics-400, UCF 101, and HMDB 51, demonstrate that STFT blocks based 3D CNNs achieve on par or even better performance compared to the state-of-the-art methods.
Joint Learning of Vessel Segmentation and Artery/Vein Classification with Post-processing
May 27, 2020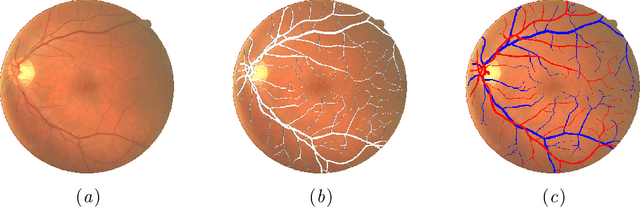
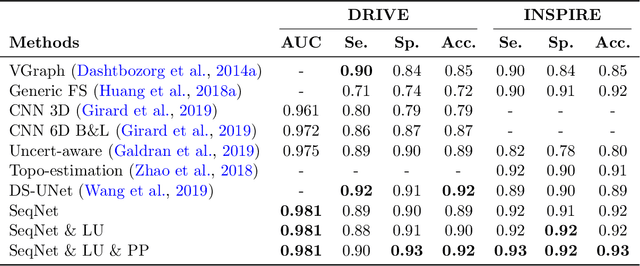
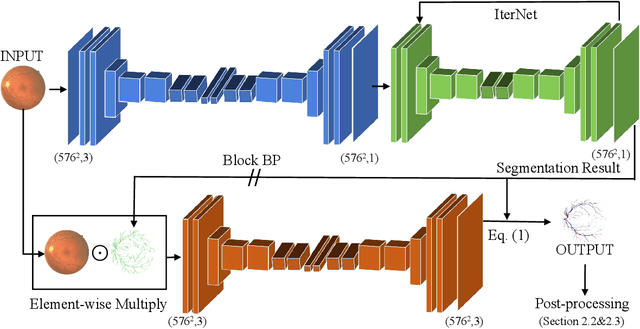
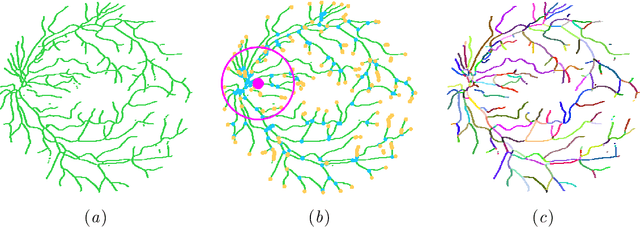
Retinal imaging serves as a valuable tool for diagnosis of various diseases. However, reading retinal images is a difficult and time-consuming task even for experienced specialists. The fundamental step towards automated retinal image analysis is vessel segmentation and artery/vein classification, which provide various information on potential disorders. To improve the performance of the existing automated methods for retinal image analysis, we propose a two-step vessel classification. We adopt a UNet-based model, SeqNet, to accurately segment vessels from the background and make prediction on the vessel type. Our model does segmentation and classification sequentially, which alleviates the problem of label distribution bias and facilitates training. To further refine classification results, we post-process them considering the structural information among vessels to propagate highly confident prediction to surrounding vessels. Our experiments show that our method improves AUC to 0.98 for segmentation and the accuracy to 0.92 in classification over DRIVE dataset.
Yoga-82: A New Dataset for Fine-grained Classification of Human Poses
Apr 22, 2020

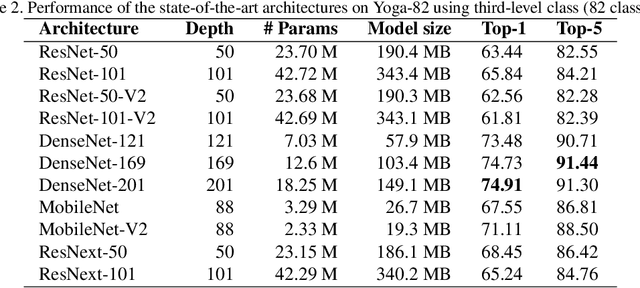
Human pose estimation is a well-known problem in computer vision to locate joint positions. Existing datasets for the learning of poses are observed to be not challenging enough in terms of pose diversity, object occlusion, and viewpoints. This makes the pose annotation process relatively simple and restricts the application of the models that have been trained on them. To handle more variety in human poses, we propose the concept of fine-grained hierarchical pose classification, in which we formulate the pose estimation as a classification task, and propose a dataset, Yoga-82, for large-scale yoga pose recognition with 82 classes. Yoga-82 consists of complex poses where fine annotations may not be possible. To resolve this, we provide hierarchical labels for yoga poses based on the body configuration of the pose. The dataset contains a three-level hierarchy including body positions, variations in body positions, and the actual pose names. We present the classification accuracy of the state-of-the-art convolutional neural network architectures on Yoga-82. We also present several hierarchical variants of DenseNet in order to utilize the hierarchical labels.
Recommending Themes for Ad Creative Design via Visual-Linguistic Representations
Feb 27, 2020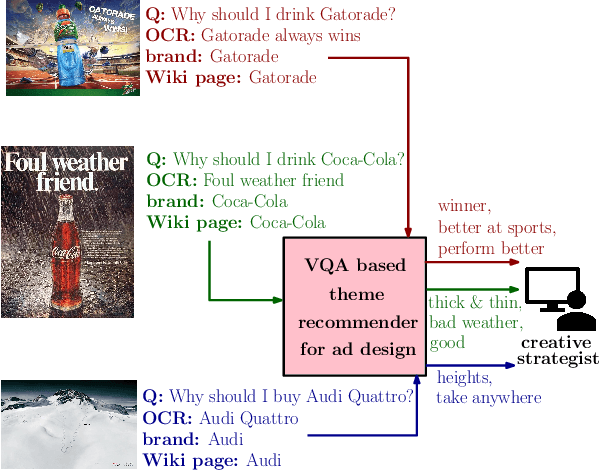
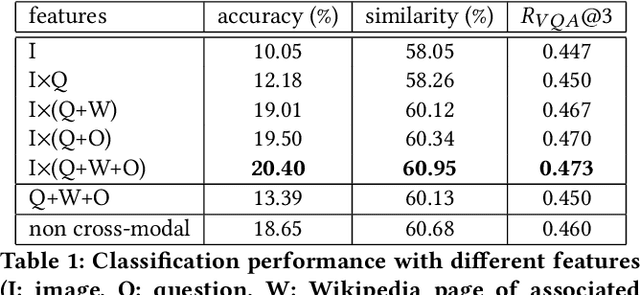
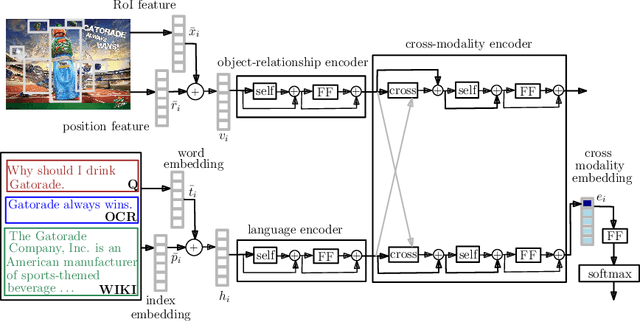
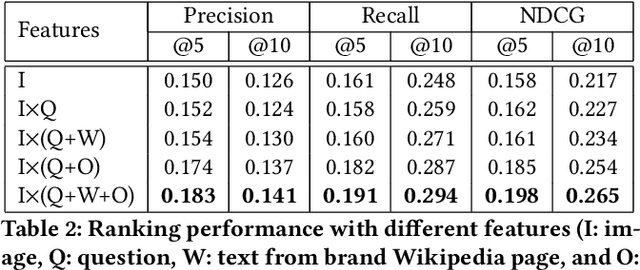
There is a perennial need in the online advertising industry to refresh ad creatives, i.e., images and text used for enticing online users towards a brand. Such refreshes are required to reduce the likelihood of ad fatigue among online users, and to incorporate insights from other successful campaigns in related product categories. Given a brand, to come up with themes for a new ad is a painstaking and time consuming process for creative strategists. Strategists typically draw inspiration from the images and text used for past ad campaigns, as well as world knowledge on the brands. To automatically infer ad themes via such multimodal sources of information in past ad campaigns, we propose a theme (keyphrase) recommender system for ad creative strategists. The theme recommender is based on aggregating results from a visual question answering (VQA) task, which ingests the following: (i) ad images, (ii) text associated with the ads as well as Wikipedia pages on the brands in the ads, and (iii) questions around the ad. We leverage transformer based cross-modality encoders to train visual-linguistic representations for our VQA task. We study two formulations for the VQA task along the lines of classification and ranking; via experiments on a public dataset, we show that cross-modal representations lead to significantly better classification accuracy and ranking precision-recall metrics. Cross-modal representations show better performance compared to separate image and text representations. In addition, the use of multimodal information shows a significant lift over using only textual or visual information.