 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInstrument-tissue Interaction Detection Framework for Surgical Video Understanding
Mar 30, 2024Instrument-tissue interaction detection task, which helps understand surgical activities, is vital for constructing computer-assisted surgery systems but with many challenges. Firstly, most models represent instrument-tissue interaction in a coarse-grained way which only focuses on classification and lacks the ability to automatically detect instruments and tissues. Secondly, existing works do not fully consider relations between intra- and inter-frame of instruments and tissues. In the paper, we propose to represent instrument-tissue interaction as <instrument class, instrument bounding box, tissue class, tissue bounding box, action class> quintuple and present an Instrument-Tissue Interaction Detection Network (ITIDNet) to detect the quintuple for surgery videos understanding. Specifically, we propose a Snippet Consecutive Feature (SCF) Layer to enhance features by modeling relationships of proposals in the current frame using global context information in the video snippet. We also propose a Spatial Corresponding Attention (SCA) Layer to incorporate features of proposals between adjacent frames through spatial encoding. To reason relationships between instruments and tissues, a Temporal Graph (TG) Layer is proposed with intra-frame connections to exploit relationships between instruments and tissues in the same frame and inter-frame connections to model the temporal information for the same instance. For evaluation, we build a cataract surgery video (PhacoQ) dataset and a cholecystectomy surgery video (CholecQ) dataset. Experimental results demonstrate the promising performance of our model, which outperforms other state-of-the-art models on both datasets.
Match Them Up: Visually Explainable Few-shot Image Classification
Nov 25, 2020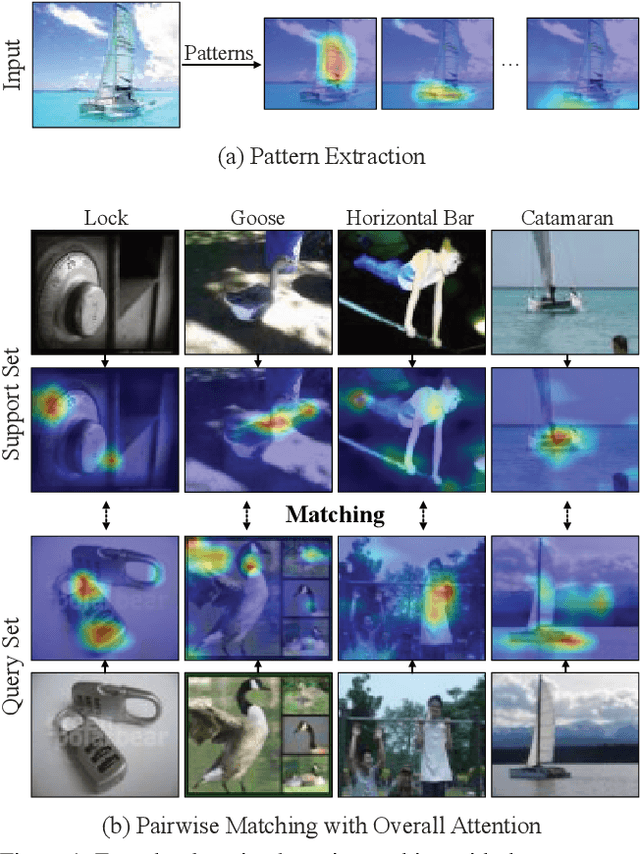
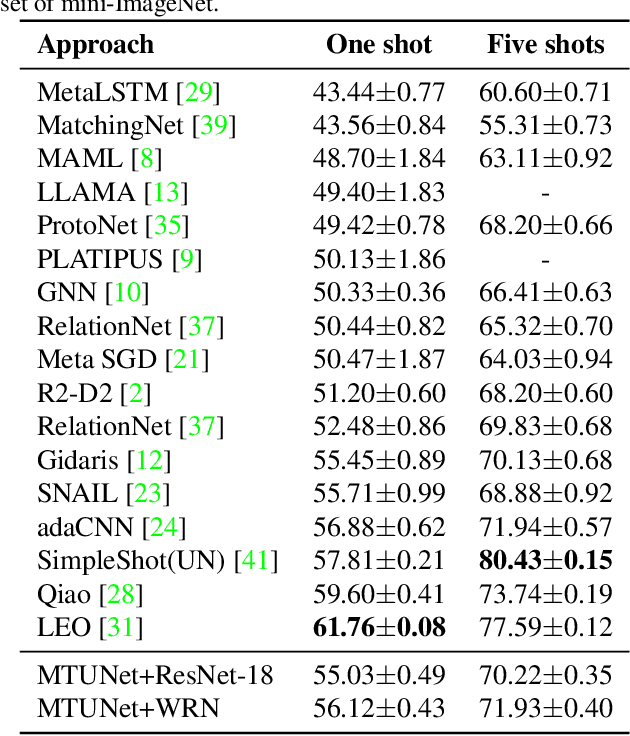
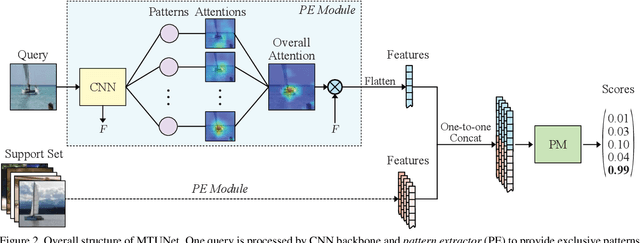
Few-shot learning (FSL) approaches are usually based on an assumption that the pre-trained knowledge can be obtained from base (seen) categories and can be well transferred to novel (unseen) categories. However, there is no guarantee, especially for the latter part. This issue leads to the unknown nature of the inference process in most FSL methods, which hampers its application in some risk-sensitive areas. In this paper, we reveal a new way to perform FSL for image classification, using visual representations from the backbone model and weights generated by a newly-emerged explainable classifier. The weighted representations only include a minimum number of distinguishable features and the visualized weights can serve as an informative hint for the FSL process. Finally, a discriminator will compare the representations of each pair of the images in the support set and the query set. Pairs with the highest scores will decide the classification results. Experimental results prove that the proposed method can achieve both good accuracy and satisfactory explainability on three mainstream datasets.
Grading the Severity of Arteriolosclerosis from Retinal Arterio-venous Crossing Patterns
Nov 07, 2020
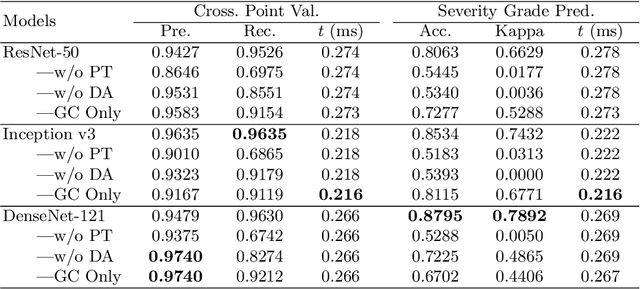
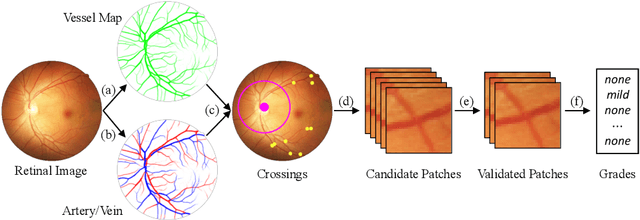
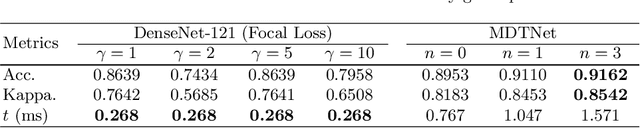
The status of retinal arteriovenous crossing is of great significance for clinical evaluation of arteriolosclerosis and systemic hypertension. As an ophthalmology diagnostic criteria, Scheie's classification has been used to grade the severity of arteriolosclerosis. In this paper, we propose a deep learning approach to support the diagnosis process, which, to the best of our knowledge, is one of the earliest attempts in medical imaging. The proposed pipeline is three-fold. First, we adopt segmentation and classification models to automatically obtain vessels in a retinal image with the corresponding artery/vein labels and find candidate arteriovenous crossing points. Second, we use a classification model to validate the true crossing point. At last, the grade of severity for the vessel crossings is classified. To better address the problem of label ambiguity and imbalanced label distribution, we propose a new model, named multi-diagnosis team network (MDTNet), in which the sub-models with different structures or different loss functions provide different decisions. MDTNet unifies these diverse theories to give the final decision with high accuracy. Our severity grading method was able to validate crossing points with precision and recall of 96.3% and 96.3%, respectively. Among correctly detected crossing points, the kappa value for the agreement between the grading by a retina specialist and the estimated score was 0.85, with an accuracy of 0.92. The numerical results demonstrate that our method can achieve a good performance in both arteriovenous crossing validation and severity grading tasks. By the proposed models, we could build a pipeline reproducing retina specialist's subjective grading without feature extractions. The code is available for reproducibility.
Noisy-LSTM: Improving Temporal Awareness for Video Semantic Segmentation
Oct 19, 2020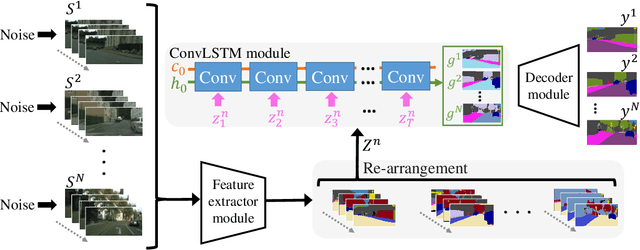

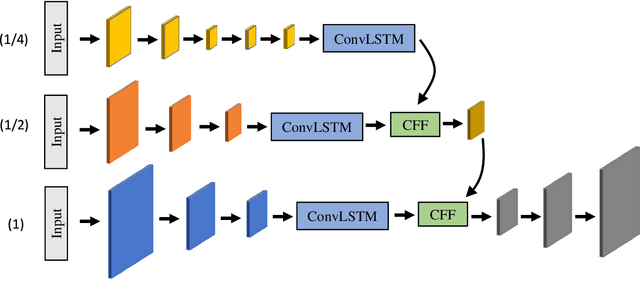

Semantic video segmentation is a key challenge for various applications. This paper presents a new model named Noisy-LSTM, which is trainable in an end-to-end manner, with convolutional LSTMs (ConvLSTMs) to leverage the temporal coherency in video frames. We also present a simple yet effective training strategy, which replaces a frame in video sequence with noises. This strategy spoils the temporal coherency in video frames during training and thus makes the temporal links in ConvLSTMs unreliable, which may consequently improve feature extraction from video frames, as well as serve as a regularizer to avoid overfitting, without requiring extra data annotation or computational costs. Experimental results demonstrate that the proposed model can achieve state-of-the-art performances in both the CityScapes and EndoVis2018 datasets.
SCOUTER: Slot Attention-based Classifier for Explainable Image Recognition
Sep 14, 2020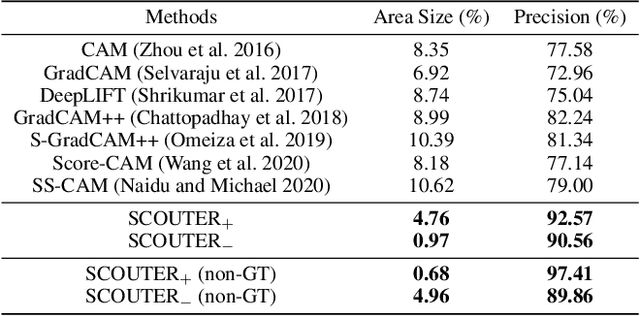



Explainable artificial intelligence is gaining attention. However, most existing methods are based on gradients or intermediate features, which are not directly involved in the decision-making process of the classifier. In this paper, we propose a slot attention-based light-weighted classifier called SCOUTER for transparent yet accurate classification. Two major differences from other attention-based methods include: (a) SCOUTER's explanation involves the final confidence for each category, offering more intuitive interpretation, and (b) all the categories have their corresponding positive or negative explanation, which tells "why the image is of a certain category" or "why the image is not of a certain category." We design a new loss tailored for SCOUTER that controls the model's behavior to switch between positive and negative explanations, as well as the size of explanatory regions. Experimental results show that SCOUTER can give better visual explanations while keeping good accuracy on a large dataset.
Joint Learning of Vessel Segmentation and Artery/Vein Classification with Post-processing
May 27, 2020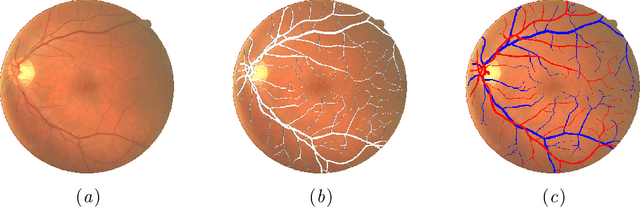
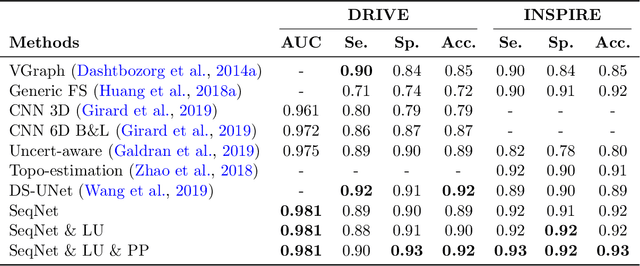
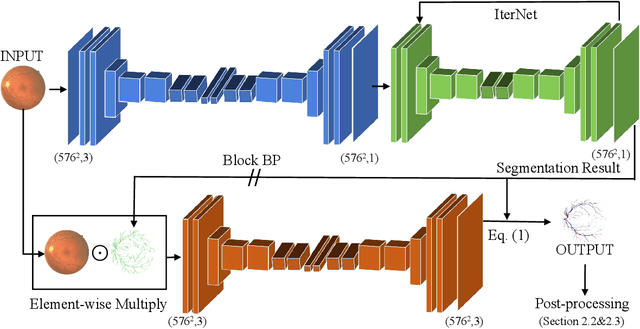
Retinal imaging serves as a valuable tool for diagnosis of various diseases. However, reading retinal images is a difficult and time-consuming task even for experienced specialists. The fundamental step towards automated retinal image analysis is vessel segmentation and artery/vein classification, which provide various information on potential disorders. To improve the performance of the existing automated methods for retinal image analysis, we propose a two-step vessel classification. We adopt a UNet-based model, SeqNet, to accurately segment vessels from the background and make prediction on the vessel type. Our model does segmentation and classification sequentially, which alleviates the problem of label distribution bias and facilitates training. To further refine classification results, we post-process them considering the structural information among vessels to propagate highly confident prediction to surrounding vessels. Our experiments show that our method improves AUC to 0.98 for segmentation and the accuracy to 0.92 in classification over DRIVE dataset.
IterNet: Retinal Image Segmentation Utilizing Structural Redundancy in Vessel Networks
Dec 12, 2019
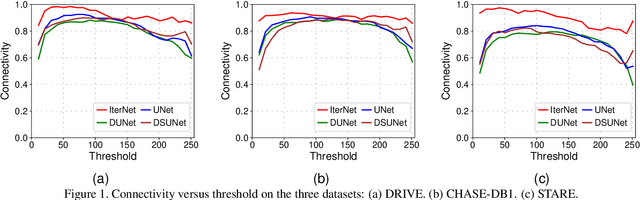


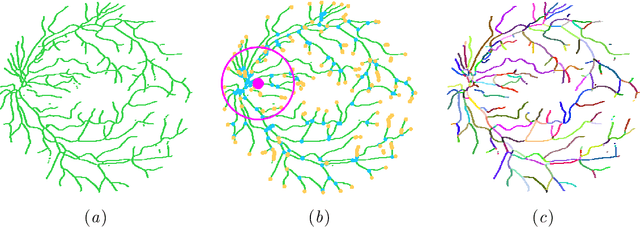
Retinal vessel segmentation is of great interest for diagnosis of retinal vascular diseases. To further improve the performance of vessel segmentation, we propose IterNet, a new model based on UNet, with the ability to find obscured details of the vessel from the segmented vessel image itself, rather than the raw input image. IterNet consists of multiple iterations of a mini-UNet, which can be 4$\times$ deeper than the common UNet. IterNet also adopts the weight-sharing and skip-connection features to facilitate training; therefore, even with such a large architecture, IterNet can still learn from merely 10$\sim$20 labeled images, without pre-training or any prior knowledge. IterNet achieves AUCs of 0.9816, 0.9851, and 0.9881 on three mainstream datasets, namely DRIVE, CHASE-DB1, and STARE, respectively, which currently are the best scores in the literature. The source code is available.