 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTF-Attack: Transferable and Fast Adversarial Attacks on Large Language Models
Aug 26, 2024With the great advancements in large language models (LLMs), adversarial attacks against LLMs have recently attracted increasing attention. We found that pre-existing adversarial attack methodologies exhibit limited transferability and are notably inefficient, particularly when applied to LLMs. In this paper, we analyze the core mechanisms of previous predominant adversarial attack methods, revealing that 1) the distributions of importance score differ markedly among victim models, restricting the transferability; 2) the sequential attack processes induces substantial time overheads. Based on the above two insights, we introduce a new scheme, named TF-Attack, for Transferable and Fast adversarial attacks on LLMs. TF-Attack employs an external LLM as a third-party overseer rather than the victim model to identify critical units within sentences. Moreover, TF-Attack introduces the concept of Importance Level, which allows for parallel substitutions of attacks. We conduct extensive experiments on 6 widely adopted benchmarks, evaluating the proposed method through both automatic and human metrics. Results show that our method consistently surpasses previous methods in transferability and delivers significant speed improvements, up to 20 times faster than earlier attack strategies.
An Energy-based Model for Word-level AutoCompletion in Computer-aided Translation
Jul 29, 2024Word-level AutoCompletion(WLAC) is a rewarding yet challenging task in Computer-aided Translation. Existing work addresses this task through a classification model based on a neural network that maps the hidden vector of the input context into its corresponding label (i.e., the candidate target word is treated as a label). Since the context hidden vector itself does not take the label into account and it is projected to the label through a linear classifier, the model can not sufficiently leverage valuable information from the source sentence as verified in our experiments, which eventually hinders its overall performance. To alleviate this issue, this work proposes an energy-based model for WLAC, which enables the context hidden vector to capture crucial information from the source sentence. Unfortunately, training and inference suffer from efficiency and effectiveness challenges, thereby we employ three simple yet effective strategies to put our model into practice. Experiments on four standard benchmarks demonstrate that our reranking-based approach achieves substantial improvements (about 6.07%) over the previous state-of-the-art model. Further analyses show that each strategy of our approach contributes to the final performance.
CoAct: A Global-Local Hierarchy for Autonomous Agent Collaboration
Jun 19, 2024Existing LLMs exhibit remarkable performance on various NLP tasks, but still struggle with complex real-world tasks, even equipped with advanced strategies like CoT and ReAct. In this work, we propose the CoAct framework, which transfers the hierarchical planning and collaboration patterns in human society to LLM systems. Specifically, our CoAct framework involves two agents: (1) A global planning agent, to comprehend the problem scope, formulate macro-level plans and provide detailed sub-task descriptions to local execution agents, which serves as the initial rendition of a global plan. (2) A local execution agent, to operate within the multi-tier task execution structure, focusing on detailed execution and implementation of specific tasks within the global plan. Experimental results on the WebArena benchmark show that CoAct can re-arrange the process trajectory when facing failures, and achieves superior performance over baseline methods on long-horizon web tasks. Code is available at https://github.com/xmhou2002/CoAct.
On the Hallucination in Simultaneous Machine Translation
Jun 11, 2024It is widely known that hallucination is a critical issue in Simultaneous Machine Translation (SiMT) due to the absence of source-side information. While many efforts have been made to enhance performance for SiMT, few of them attempt to understand and analyze hallucination in SiMT. Therefore, we conduct a comprehensive analysis of hallucination in SiMT from two perspectives: understanding the distribution of hallucination words and the target-side context usage of them. Intensive experiments demonstrate some valuable findings and particularly show that it is possible to alleviate hallucination by decreasing the over usage of target-side information for SiMT.
Instrument-tissue Interaction Detection Framework for Surgical Video Understanding
Mar 30, 2024Instrument-tissue interaction detection task, which helps understand surgical activities, is vital for constructing computer-assisted surgery systems but with many challenges. Firstly, most models represent instrument-tissue interaction in a coarse-grained way which only focuses on classification and lacks the ability to automatically detect instruments and tissues. Secondly, existing works do not fully consider relations between intra- and inter-frame of instruments and tissues. In the paper, we propose to represent instrument-tissue interaction as <instrument class, instrument bounding box, tissue class, tissue bounding box, action class> quintuple and present an Instrument-Tissue Interaction Detection Network (ITIDNet) to detect the quintuple for surgery videos understanding. Specifically, we propose a Snippet Consecutive Feature (SCF) Layer to enhance features by modeling relationships of proposals in the current frame using global context information in the video snippet. We also propose a Spatial Corresponding Attention (SCA) Layer to incorporate features of proposals between adjacent frames through spatial encoding. To reason relationships between instruments and tissues, a Temporal Graph (TG) Layer is proposed with intra-frame connections to exploit relationships between instruments and tissues in the same frame and inter-frame connections to model the temporal information for the same instance. For evaluation, we build a cataract surgery video (PhacoQ) dataset and a cholecystectomy surgery video (CholecQ) dataset. Experimental results demonstrate the promising performance of our model, which outperforms other state-of-the-art models on both datasets.
Benchmarking LLMs via Uncertainty Quantification
Jan 23, 2024



The proliferation of open-source Large Language Models (LLMs) from various institutions has highlighted the urgent need for comprehensive evaluation methods. However, current evaluation platforms, such as the widely recognized HuggingFace open LLM leaderboard, neglect a crucial aspect -- uncertainty, which is vital for thoroughly assessing LLMs. To bridge this gap, we introduce a new benchmarking approach for LLMs that integrates uncertainty quantification. Our examination involves eight LLMs (LLM series) spanning five representative natural language processing tasks. Additionally, we introduce an uncertainty-aware evaluation metric, UAcc, which takes into account both prediction accuracy and prediction uncertainty. Our findings reveal that: I) LLMs with higher accuracy may exhibit lower certainty; II) Larger-scale LLMs may display greater uncertainty compared to their smaller counterparts; and III) Instruction-finetuning tends to increase the uncertainty of LLMs. By taking uncertainty into account, our new UAcc metric can either amplify or diminish the relative improvement of one LLM over another and may even change the relative ranking of two LLMs. These results underscore the significance of incorporating uncertainty in the evaluation of LLMs.
Context Consistency between Training and Testing in Simultaneous Machine Translation
Nov 13, 2023Simultaneous Machine Translation (SiMT) aims to yield a real-time partial translation with a monotonically growing the source-side context. However, there is a counterintuitive phenomenon about the context usage between training and testing: e.g., the wait-k testing model consistently trained with wait-k is much worse than that model inconsistently trained with wait-k' (k' is not equal to k) in terms of translation quality. To this end, we first investigate the underlying reasons behind this phenomenon and uncover the following two factors: 1) the limited correlation between translation quality and training (cross-entropy) loss; 2) exposure bias between training and testing. Based on both reasons, we then propose an effective training approach called context consistency training accordingly, which makes consistent the context usage between training and testing by optimizing translation quality and latency as bi-objectives and exposing the predictions to the model during the training. The experiments on three language pairs demonstrate our intuition: our system encouraging context consistency outperforms that existing systems with context inconsistency for the first time, with the help of our context consistency training approach.
Rethinking Word-Level Auto-Completion in Computer-Aided Translation
Oct 24, 2023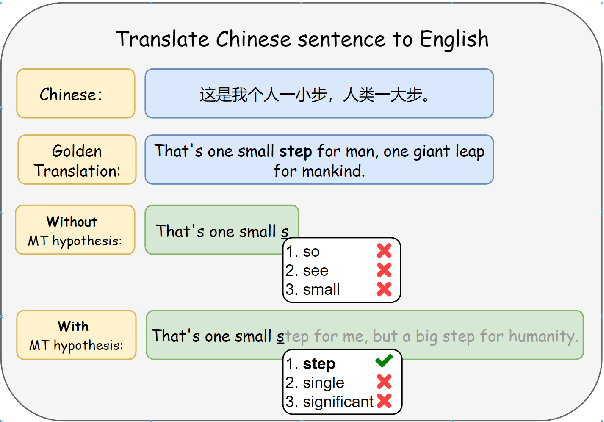
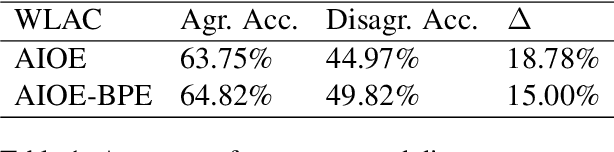

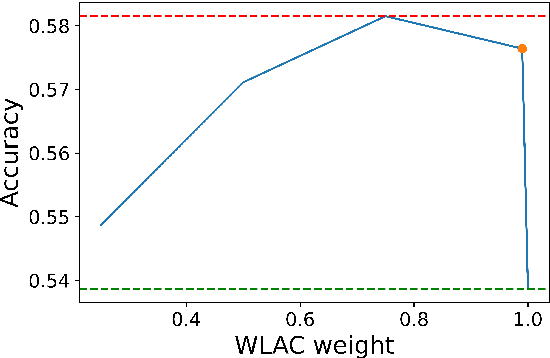
Word-Level Auto-Completion (WLAC) plays a crucial role in Computer-Assisted Translation. It aims at providing word-level auto-completion suggestions for human translators. While previous studies have primarily focused on designing complex model architectures, this paper takes a different perspective by rethinking the fundamental question: what kind of words are good auto-completions? We introduce a measurable criterion to answer this question and discover that existing WLAC models often fail to meet this criterion. Building upon this observation, we propose an effective approach to enhance WLAC performance by promoting adherence to the criterion. Notably, the proposed approach is general and can be applied to various encoder-based architectures. Through extensive experiments, we demonstrate that our approach outperforms the top-performing system submitted to the WLAC shared tasks in WMT2022, while utilizing significantly smaller model sizes.
Image super-resolution via dynamic network
Oct 16, 2023



Convolutional neural networks (CNNs) depend on deep network architectures to extract accurate information for image super-resolution. However, obtained information of these CNNs cannot completely express predicted high-quality images for complex scenes. In this paper, we present a dynamic network for image super-resolution (DSRNet), which contains a residual enhancement block, wide enhancement block, feature refinement block and construction block. The residual enhancement block is composed of a residual enhanced architecture to facilitate hierarchical features for image super-resolution. To enhance robustness of obtained super-resolution model for complex scenes, a wide enhancement block achieves a dynamic architecture to learn more robust information to enhance applicability of an obtained super-resolution model for varying scenes. To prevent interference of components in a wide enhancement block, a refinement block utilizes a stacked architecture to accurately learn obtained features. Also, a residual learning operation is embedded in the refinement block to prevent long-term dependency problem. Finally, a construction block is responsible for reconstructing high-quality images. Designed heterogeneous architecture can not only facilitate richer structural information, but also be lightweight, which is suitable for mobile digital devices. Experimental results shows that our method is more competitive in terms of performance and recovering time of image super-resolution and complexity. The code of DSRNet can be obtained at https://github.com/hellloxiaotian/DSRNet.
Hard Exudate Segmentation Supplemented by Super-Resolution with Multi-scale Attention Fusion Module
Nov 17, 2022Hard exudates (HE) is the most specific biomarker for retina edema. Precise HE segmentation is vital for disease diagnosis and treatment, but automatic segmentation is challenged by its large variation of characteristics including size, shape and position, which makes it difficult to detect tiny lesions and lesion boundaries. Considering the complementary features between segmentation and super-resolution tasks, this paper proposes a novel hard exudates segmentation method named SS-MAF with an auxiliary super-resolution task, which brings in helpful detailed features for tiny lesion and boundaries detection. Specifically, we propose a fusion module named Multi-scale Attention Fusion (MAF) module for our dual-stream framework to effectively integrate features of the two tasks. MAF first adopts split spatial convolutional (SSC) layer for multi-scale features extraction and then utilize attention mechanism for features fusion of the two tasks. Considering pixel dependency, we introduce region mutual information (RMI) loss to optimize MAF module for tiny lesions and boundary detection. We evaluate our method on two public lesion datasets, IDRiD and E-Ophtha. Our method shows competitive performance with low-resolution inputs, both quantitatively and qualitatively. On E-Ophtha dataset, the method can achieve $\geq3\%$ higher dice and recall compared with the state-of-the-art methods.