 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM Zeroth-Order Fine-Tuning is an Inference Workload
May 27, 2026Zeroth-order (ZO) fine-tuning is attractive for large language models because it replaces backpropagation with forward objective evaluations. Existing implementations nevertheless execute ZO algorithms inside conventional training loops, even though their dominant work is repeated scoring under nearby parameter states. This creates a workload-runtime mismatch: the algorithm asks for structured inference-style scoring, while the system exposes a sequence of fragmented training-loop steps. We show that LLM ZO fine-tuning is an inference-dominated workload and execute its repeated scoring phase through a serving runtime. On OPT-13B SST-2, the resulting vLLM execution path completes the 20k-step LoZO run in 0.51 estimated training hours versus 4.15 hours for the official LoZO baseline under the matched LoRA-only setting, an 8.13x speedup, while reaching 0.922 final evaluation accuracy and 0.931 final full-validation accuracy. In core-step scaling experiments across OPT-1.3B to OPT-13B, the same runtime reorganization gives 2.34x--7.72x speedups. A MeZO-style high-rank factorized experiment shows that the same runtime paradigm can track a MeZO-like loss trajectory while running up to 2.55x faster. More broadly, representing ZO updates as dynamic adapter states suggests a practical path toward inference-time training, where lightweight adaptation can be scheduled as an inference-like workload rather than as a separate training job.
Mnemis: Dual-Route Retrieval on Hierarchical Graphs for Long-Term LLM Memory
Feb 17, 2026AI Memory, specifically how models organizes and retrieves historical messages, becomes increasingly valuable to Large Language Models (LLMs), yet existing methods (RAG and Graph-RAG) primarily retrieve memory through similarity-based mechanisms. While efficient, such System-1-style retrieval struggles with scenarios that require global reasoning or comprehensive coverage of all relevant information. In this work, We propose Mnemis, a novel memory framework that integrates System-1 similarity search with a complementary System-2 mechanism, termed Global Selection. Mnemis organizes memory into a base graph for similarity retrieval and a hierarchical graph that enables top-down, deliberate traversal over semantic hierarchies. By combining the complementary strength from both retrieval routes, Mnemis retrieves memory items that are both semantically and structurally relevant. Mnemis achieves state-of-the-art performance across all compared methods on long-term memory benchmarks, scoring 93.9 on LoCoMo and 91.6 on LongMemEval-S using GPT-4.1-mini.
Recover Cell Tensor: Diffusion-Equivalent Tensor Completion for Fluorescence Microscopy Imaging
Jan 27, 2026Fluorescence microscopy (FM) imaging is a fundamental technique for observing live cell division, one of the most essential processes in the cycle of life and death. Observing 3D live cells requires scanning through the cell volume while minimizing lethal phototoxicity. That limits acquisition time and results in sparsely sampled volumes with anisotropic resolution and high noise. Existing image restoration methods, primarily based on inverse problem modeling, assume known and stable degradation processes and struggle under such conditions, especially in the absence of high-quality reference volumes. In this paper, from a new perspective, we propose a novel tensor completion framework tailored to the nature of FM imaging, which inherently involves nonlinear signal degradation and incomplete observations. Specifically, FM imaging with equidistant Z-axis sampling is essentially a tensor completion task under a uniformly random sampling condition. On one hand, we derive the theoretical lower bound for exact cell tensor completion, validating the feasibility of accurately recovering 3D cell tensor. On the other hand, we reformulate the tensor completion problem as a mathematically equivalent score-based generative model. By incorporating structural consistency priors, the generative trajectory is effectively guided toward denoised and geometrically coherent reconstructions. Our method demonstrates state-of-the-art performance on SR-CACO-2 and three real \textit{in vivo} cellular datasets, showing substantial improvements in both signal-to-noise ratio and structural fidelity.
Mind the Ambiguity: Aleatoric Uncertainty Quantification in LLMs for Safe Medical Question Answering
Jan 24, 2026The deployment of Large Language Models in Medical Question Answering is severely hampered by ambiguous user queries, a significant safety risk that demonstrably reduces answer accuracy in high-stakes healthcare settings. In this paper, we formalize this challenge by linking input ambiguity to aleatoric uncertainty (AU), which is the irreducible uncertainty arising from underspecified input. To facilitate research in this direction, we construct CV-MedBench, the first benchmark designed for studying input ambiguity in Medical QA. Using this benchmark, we analyze AU from a representation engineering perspective, revealing that AU is linearly encoded in LLM's internal activation patterns. Leveraging this insight, we introduce a novel AU-guided "Clarify-Before-Answer" framework, which incorporates AU-Probe - a lightweight module that detects input ambiguity directly from hidden states. Unlike existing uncertainty estimation methods, AU-Probe requires neither LLM fine-tuning nor multiple forward passes, enabling an efficient mechanism to proactively request user clarification and significantly enhance safety. Extensive experiments across four open LLMs demonstrate the effectiveness of our QA framework, with an average accuracy improvement of 9.48% over baselines. Our framework provides an efficient and robust solution for safe Medical QA, strengthening the reliability of health-related applications. The code is available at https://github.com/yaokunliu/AU-Med.git, and the CV-MedBench dataset is released on Hugging Face at https://huggingface.co/datasets/yaokunl/CV-MedBench.
COMPARE: Clinical Optimization with Modular Planning and Assessment via RAG-Enhanced AI-OCT: Superior Decision Support for Percutaneous Coronary Intervention Compared to ChatGPT-5 and Junior Operators
Dec 11, 2025Background: While intravascular imaging, particularly optical coherence tomography (OCT), improves percutaneous coronary intervention (PCI) outcomes, its interpretation is operator-dependent. General-purpose artificial intelligence (AI) shows promise but lacks domain-specific reliability. We evaluated the performance of CA-GPT, a novel large model deployed on an AI-OCT system, against that of the general-purpose ChatGPT-5 and junior physicians for OCT-guided PCI planning and assessment. Methods: In this single-center analysis of 96 patients who underwent OCT-guided PCI, the procedural decisions generated by the CA-GPT, ChatGPT-5, and junior physicians were compared with an expert-derived procedural record. Agreement was assessed using ten pre-specified metrics across pre-PCI and post-PCI phases. Results: For pre-PCI planning, CA-GPT demonstrated significantly higher median agreement scores (5[IQR 3.75-5]) compared to both ChatGPT-5 (3[2-4], P<0.001) and junior physicians (4[3-4], P<0.001). CA-GPT significantly outperformed ChatGPT-5 across all individual pre-PCI metrics and showed superior performance to junior physicians in stent diameter (90.3% vs. 72.2%, P<0.05) and length selection (80.6% vs. 52.8%, P<0.01). In post-PCI assessment, CA-GPT maintained excellent overall agreement (5[4.75-5]), significantly higher than both ChatGPT-5 (4[4-5], P<0.001) and junior physicians (5[4-5], P<0.05). Subgroup analysis confirmed CA-GPT's robust performance advantage in complex scenarios. Conclusion: The CA-GPT-based AI-OCT system achieved superior decision-making agreement versus a general-purpose large language model and junior physicians across both PCI planning and assessment phases. This approach provides a standardized and reliable method for intravascular imaging interpretation, demonstrating significant potential to augment operator expertise and optimize OCT-guided PCI.
Sublinear-Time Algorithms for Diagonally Dominant Systems and Applications to the Friedkin-Johnsen Model
Sep 16, 2025


We study sublinear-time algorithms for solving linear systems $Sz = b$, where $S$ is a diagonally dominant matrix, i.e., $|S_{ii}| \geq \delta + \sum_{j \ne i} |S_{ij}|$ for all $i \in [n]$, for some $\delta \geq 0$. We present randomized algorithms that, for any $u \in [n]$, return an estimate $z_u$ of $z^*_u$ with additive error $\varepsilon$ or $\varepsilon \lVert z^*\rVert_\infty$, where $z^*$ is some solution to $Sz^* = b$, and the algorithm only needs to read a small portion of the input $S$ and $b$. For example, when the additive error is $\varepsilon$ and assuming $\delta>0$, we give an algorithm that runs in time $O\left( \frac{\|b\|_\infty^2 S_{\max}}{\delta^3 \varepsilon^2} \log \frac{\| b \|_\infty}{\delta \varepsilon} \right)$, where $S_{\max} = \max_{i \in [n]} |S_{ii}|$. We also prove a matching lower bound, showing that the linear dependence on $S_{\max}$ is optimal. Unlike previous sublinear-time algorithms, which apply only to symmetric diagonally dominant matrices with non-negative diagonal entries, our algorithm works for general strictly diagonally dominant matrices ($\delta > 0$) and a broader class of non-strictly diagonally dominant matrices $(\delta = 0)$. Our approach is based on analyzing a simple probabilistic recurrence satisfied by the solution. As an application, we obtain an improved sublinear-time algorithm for opinion estimation in the Friedkin--Johnsen model.
MiniMax-M1: Scaling Test-Time Compute Efficiently with Lightning Attention
Jun 16, 2025



We introduce MiniMax-M1, the world's first open-weight, large-scale hybrid-attention reasoning model. MiniMax-M1 is powered by a hybrid Mixture-of-Experts (MoE) architecture combined with a lightning attention mechanism. The model is developed based on our previous MiniMax-Text-01 model, which contains a total of 456 billion parameters with 45.9 billion parameters activated per token. The M1 model natively supports a context length of 1 million tokens, 8x the context size of DeepSeek R1. Furthermore, the lightning attention mechanism in MiniMax-M1 enables efficient scaling of test-time compute. These properties make M1 particularly suitable for complex tasks that require processing long inputs and thinking extensively. MiniMax-M1 is trained using large-scale reinforcement learning (RL) on diverse problems including sandbox-based, real-world software engineering environments. In addition to M1's inherent efficiency advantage for RL training, we propose CISPO, a novel RL algorithm to further enhance RL efficiency. CISPO clips importance sampling weights rather than token updates, outperforming other competitive RL variants. Combining hybrid-attention and CISPO enables MiniMax-M1's full RL training on 512 H800 GPUs to complete in only three weeks, with a rental cost of just $534,700. We release two versions of MiniMax-M1 models with 40K and 80K thinking budgets respectively, where the 40K model represents an intermediate phase of the 80K training. Experiments on standard benchmarks show that our models are comparable or superior to strong open-weight models such as the original DeepSeek-R1 and Qwen3-235B, with particular strengths in complex software engineering, tool utilization, and long-context tasks. We publicly release MiniMax-M1 at https://github.com/MiniMax-AI/MiniMax-M1.
LLMEval-Med: A Real-world Clinical Benchmark for Medical LLMs with Physician Validation
Jun 04, 2025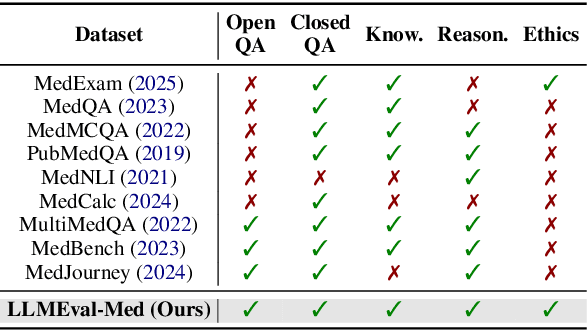
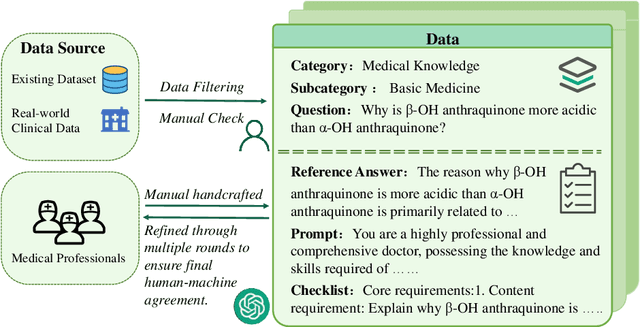
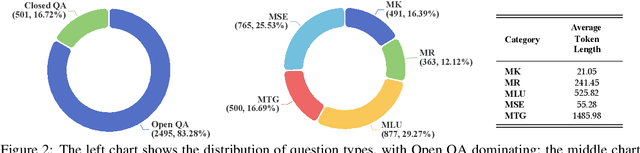
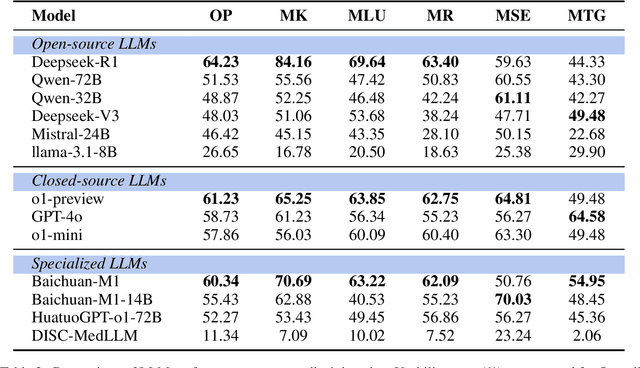
Evaluating large language models (LLMs) in medicine is crucial because medical applications require high accuracy with little room for error. Current medical benchmarks have three main types: medical exam-based, comprehensive medical, and specialized assessments. However, these benchmarks have limitations in question design (mostly multiple-choice), data sources (often not derived from real clinical scenarios), and evaluation methods (poor assessment of complex reasoning). To address these issues, we present LLMEval-Med, a new benchmark covering five core medical areas, including 2,996 questions created from real-world electronic health records and expert-designed clinical scenarios. We also design an automated evaluation pipeline, incorporating expert-developed checklists into our LLM-as-Judge framework. Furthermore, our methodology validates machine scoring through human-machine agreement analysis, dynamically refining checklists and prompts based on expert feedback to ensure reliability. We evaluate 13 LLMs across three categories (specialized medical models, open-source models, and closed-source models) on LLMEval-Med, providing valuable insights for the safe and effective deployment of LLMs in medical domains. The dataset is released in https://github.com/llmeval/LLMEval-Med.
Component-Based Fairness in Face Attribute Classification with Bayesian Network-informed Meta Learning
May 03, 2025The widespread integration of face recognition technologies into various applications (e.g., access control and personalized advertising) necessitates a critical emphasis on fairness. While previous efforts have focused on demographic fairness, the fairness of individual biological face components remains unexplored. In this paper, we focus on face component fairness, a fairness notion defined by biological face features. To our best knowledge, our work is the first work to mitigate bias of face attribute prediction at the biological feature level. In this work, we identify two key challenges in optimizing face component fairness: attribute label scarcity and attribute inter-dependencies, both of which limit the effectiveness of bias mitigation from previous approaches. To address these issues, we propose \textbf{B}ayesian \textbf{N}etwork-informed \textbf{M}eta \textbf{R}eweighting (BNMR), which incorporates a Bayesian Network calibrator to guide an adaptive meta-learning-based sample reweighting process. During the training process of our approach, the Bayesian Network calibrator dynamically tracks model bias and encodes prior probabilities for face component attributes to overcome the above challenges. To demonstrate the efficacy of our approach, we conduct extensive experiments on a large-scale real-world human face dataset. Our results show that BNMR is able to consistently outperform recent face bias mitigation baselines. Moreover, our results suggest a positive impact of face component fairness on the commonly considered demographic fairness (e.g., \textit{gender}). Our findings pave the way for new research avenues on face component fairness, suggesting that face component fairness could serve as a potential surrogate objective for demographic fairness. The code for our work is publicly available~\footnote{https://github.com/yliuaa/BNMR-FairCompFace.git}.
Volume Tells: Dual Cycle-Consistent Diffusion for 3D Fluorescence Microscopy De-noising and Super-Resolution
Mar 04, 20253D fluorescence microscopy is essential for understanding fundamental life processes through long-term live-cell imaging. However, due to inherent issues in imaging principles, it faces significant challenges including spatially varying noise and anisotropic resolution, where the axial resolution lags behind the lateral resolution up to 4.5 times. Meanwhile, laser power is kept low to maintain cell viability, leading to inaccessible low-noise and high-resolution paired ground truth (GT). To tackle these limitations, a dual Cycle-consistent Diffusion is proposed to effectively mine intra-volume imaging priors within 3D cell volumes in an unsupervised manner, i.e., Volume Tells (VTCD), achieving de-noising and super-resolution (SR) simultaneously. Specifically, a spatially iso-distributed denoiser is designed to exploit the noise distribution consistency between adjacent low-noise and high-noise regions within the 3D cell volume, suppressing the spatially varying noise. Then, in light of the structural consistency of the cell volume, a cross-plane global-propagation SR module propagates high-resolution details from the XY plane into adjacent regions in the XZ and YZ planes, progressively enhancing resolution across the entire 3D cell volume. Experimental results on 10 in vivo cellular dataset demonstrate high improvements in both denoising and super-resolution, with axial resolution enhanced from ~ 430 nm to ~ 90 nm.