 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Do Large Language Models Learn Concepts During Continual Pre-Training?
Jan 07, 2026Human beings primarily understand the world through concepts (e.g., dog), abstract mental representations that structure perception, reasoning, and learning. However, how large language models (LLMs) acquire, retain, and forget such concepts during continual pretraining remains poorly understood. In this work, we study how individual concepts are acquired and forgotten, as well as how multiple concepts interact through interference and synergy. We link these behavioral dynamics to LLMs' internal Concept Circuits, computational subgraphs associated with specific concepts, and incorporate Graph Metrics to characterize circuit structure. Our analysis reveals: (1) LLMs concept circuits provide a non-trivial, statistically significant signal of concept learning and forgetting; (2) Concept circuits exhibit a stage-wise temporal pattern during continual pretraining, with an early increase followed by gradual decrease and stabilization; (3) concepts with larger learning gains tend to exhibit greater forgetting under subsequent training; (4) semantically similar concepts induce stronger interference than weakly related ones; (5) conceptual knowledge differs in their transferability, with some significantly facilitating the learning of others. Together, our findings offer a circuit-level view of concept learning dynamics and inform the design of more interpretable and robust concept-aware training strategies for LLMs.
Clone Deterministic 3D Worlds with Geometrically-Regularized World Models
Oct 30, 2025A world model is an internal model that simulates how the world evolves. Given past observations and actions, it predicts the future of both the embodied agent and its environment. Accurate world models are essential for enabling agents to think, plan, and reason effectively in complex, dynamic settings. Despite rapid progress, current world models remain brittle and degrade over long horizons. We argue that a central cause is representation quality: exteroceptive inputs (e.g., images) are high-dimensional, and lossy or entangled latents make dynamics learning unnecessarily hard. We therefore ask whether improving representation learning alone can substantially improve world-model performance. In this work, we take a step toward building a truly accurate world model by addressing a fundamental yet open problem: constructing a model that can fully clone and overfit to a deterministic 3D world. We propose Geometrically-Regularized World Models (GRWM), which enforces that consecutive points along a natural sensory trajectory remain close in latent representation space. This approach yields significantly improved latent representations that align closely with the true topology of the environment. GRWM is plug-and-play, requires only minimal architectural modification, scales with trajectory length, and is compatible with diverse latent generative backbones. Across deterministic 3D settings and long-horizon prediction tasks, GRWM significantly increases rollout fidelity and stability. Analyses show that its benefits stem from learning a latent manifold with superior geometric structure. These findings support a clear takeaway: improving representation learning is a direct and useful path to robust world models, delivering reliable long-horizon predictions without enlarging the dynamics module.
Enhancing the Scalability and Applicability of Kohn-Sham Hamiltonians for Molecular Systems
Feb 26, 2025Density Functional Theory (DFT) is a pivotal method within quantum chemistry and materials science, with its core involving the construction and solution of the Kohn-Sham Hamiltonian. Despite its importance, the application of DFT is frequently limited by the substantial computational resources required to construct the Kohn-Sham Hamiltonian. In response to these limitations, current research has employed deep-learning models to efficiently predict molecular and solid Hamiltonians, with roto-translational symmetries encoded in their neural networks. However, the scalability of prior models may be problematic when applied to large molecules, resulting in non-physical predictions of ground-state properties. In this study, we generate a substantially larger training set (PubChemQH) than used previously and use it to create a scalable model for DFT calculations with physical accuracy. For our model, we introduce a loss function derived from physical principles, which we call Wavefunction Alignment Loss (WALoss). WALoss involves performing a basis change on the predicted Hamiltonian to align it with the observed one; thus, the resulting differences can serve as a surrogate for orbital energy differences, allowing models to make better predictions for molecular orbitals and total energies than previously possible. WALoss also substantially accelerates self-consistent-field (SCF) DFT calculations. Here, we show it achieves a reduction in total energy prediction error by a factor of 1347 and an SCF calculation speed-up by a factor of 18%. These substantial improvements set new benchmarks for achieving accurate and applicable predictions in larger molecular systems.
Efficient and Scalable Density Functional Theory Hamiltonian Prediction through Adaptive Sparsity
Feb 03, 2025Hamiltonian matrix prediction is pivotal in computational chemistry, serving as the foundation for determining a wide range of molecular properties. While SE(3) equivariant graph neural networks have achieved remarkable success in this domain, their substantial computational cost-driven by high-order tensor product (TP) operations-restricts their scalability to large molecular systems with extensive basis sets. To address this challenge, we introduce SPHNet, an efficient and scalable equivariant network that incorporates adaptive sparsity into Hamiltonian prediction. SPHNet employs two innovative sparse gates to selectively constrain non-critical interaction combinations, significantly reducing tensor product computations while maintaining accuracy. To optimize the sparse representation, we develop a Three-phase Sparsity Scheduler, ensuring stable convergence and achieving high performance at sparsity rates of up to 70 percent. Extensive evaluations on QH9 and PubchemQH datasets demonstrate that SPHNet achieves state-of-the-art accuracy while providing up to a 7x speedup over existing models. Beyond Hamiltonian prediction, the proposed sparsification techniques also hold significant potential for improving the efficiency and scalability of other SE(3) equivariant networks, further broadening their applicability and impact.
Self-Supervised Learning for Building Damage Assessment from Large-scale xBD Satellite Imagery Benchmark Datasets
Jun 01, 2022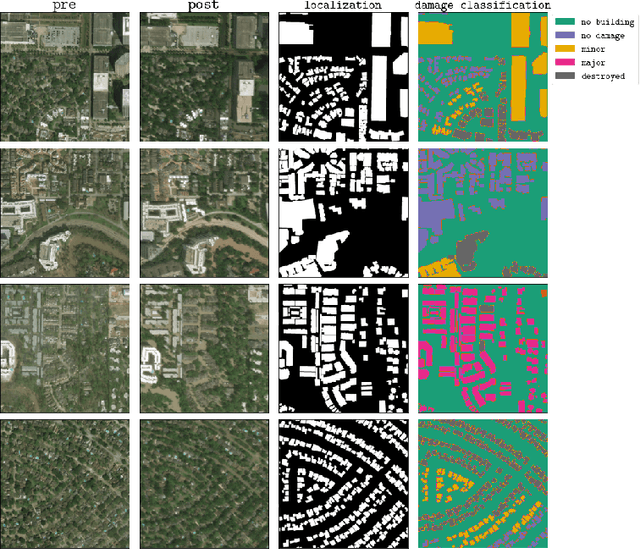
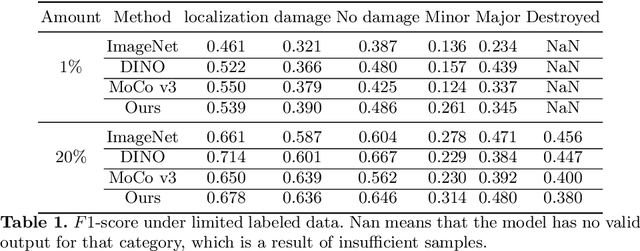
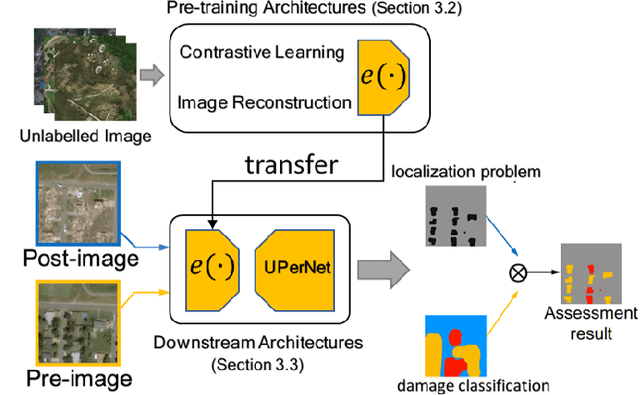
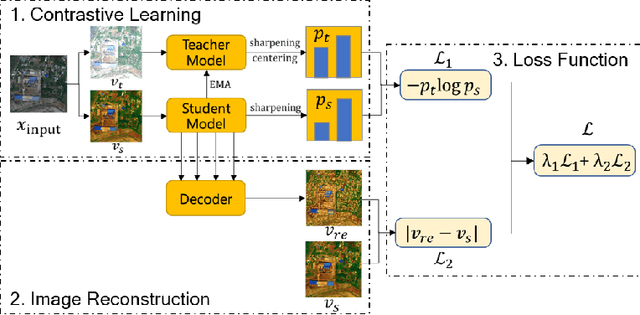
In the field of post-disaster assessment, for timely and accurate rescue and localization after a disaster, people need to know the location of damaged buildings. In deep learning, some scholars have proposed methods to make automatic and highly accurate building damage assessments by remote sensing images, which are proved to be more efficient than assessment by domain experts. However, due to the lack of a large amount of labeled data, these kinds of tasks can suffer from being able to do an accurate assessment, as the efficiency of deep learning models relies highly on labeled data. Although existing semi-supervised and unsupervised studies have made breakthroughs in this area, none of them has completely solved this problem. Therefore, we propose adopting a self-supervised comparative learning approach to address the task without the requirement of labeled data. We constructed a novel asymmetric twin network architecture and tested its performance on the xBD dataset. Experiment results of our model show the improvement compared to baseline and commonly used methods. We also demonstrated the potential of self-supervised methods for building damage recognition awareness.