 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrivacy-Preserving Action Recognition via Motion Difference Quantization
Aug 04, 2022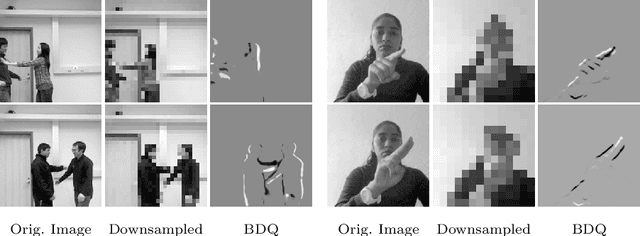

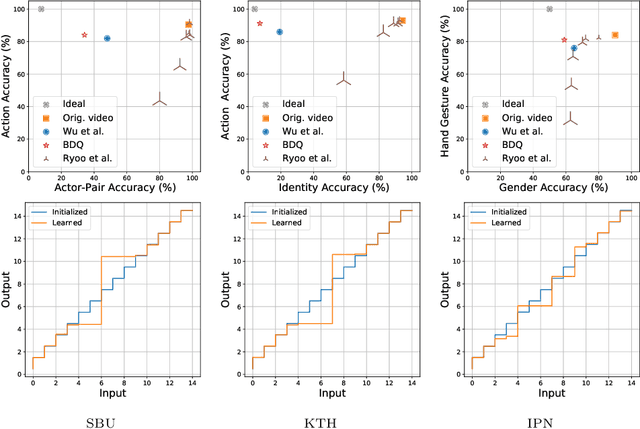
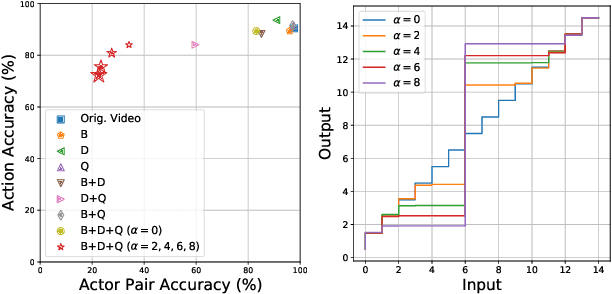
The widespread use of smart computer vision systems in our personal spaces has led to an increased consciousness about the privacy and security risks that these systems pose. On the one hand, we want these systems to assist in our daily lives by understanding their surroundings, but on the other hand, we want them to do so without capturing any sensitive information. Towards this direction, this paper proposes a simple, yet robust privacy-preserving encoder called BDQ for the task of privacy-preserving human action recognition that is composed of three modules: Blur, Difference, and Quantization. First, the input scene is passed to the Blur module to smoothen the edges. This is followed by the Difference module to apply a pixel-wise intensity subtraction between consecutive frames to highlight motion features and suppress obvious high-level privacy attributes. Finally, the Quantization module is applied to the motion difference frames to remove the low-level privacy attributes. The BDQ parameters are optimized in an end-to-end fashion via adversarial training such that it learns to allow action recognition attributes while inhibiting privacy attributes. Our experiments on three benchmark datasets show that the proposed encoder design can achieve state-of-the-art trade-off when compared with previous works. Furthermore, we show that the trade-off achieved is at par with the DVS sensor-based event cameras. Code available at: https://github.com/suakaw/BDQ_PrivacyAR.
ShuffleBlock: Shuffle to Regularize Deep Convolutional Neural Networks
Jun 17, 2021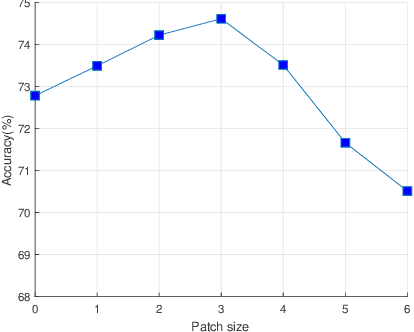
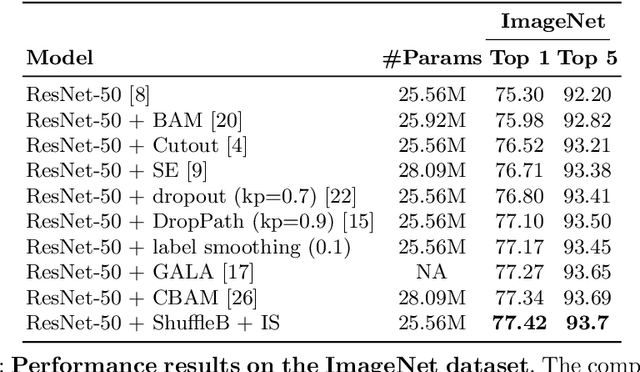
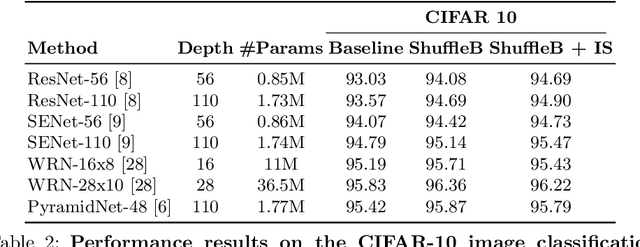
Deep neural networks have enormous representational power which leads them to overfit on most datasets. Thus, regularizing them is important in order to reduce overfitting and enhance their generalization capabilities. Recently, channel shuffle operation has been introduced for mixing channels in group convolutions in resource efficient networks in order to reduce memory and computations. This paper studies the operation of channel shuffle as a regularization technique in deep convolutional networks. We show that while random shuffling of channels during training drastically reduce their performance, however, randomly shuffling small patches between channels significantly improves their performance. The patches to be shuffled are picked from the same spatial locations in the feature maps such that a patch, when transferred from one channel to another, acts as structured noise for the later channel. We call this method "ShuffleBlock". The proposed ShuffleBlock module is easy to implement and improves the performance of several baseline networks on the task of image classification on CIFAR and ImageNet datasets. It also achieves comparable and in many cases better performance than many other regularization methods. We provide several ablation studies on selecting various hyperparameters of the ShuffleBlock module and propose a new scheduling method that further enhances its performance.
Depthwise Spatio-Temporal STFT Convolutional Neural Networks for Human Action Recognition
Jul 22, 2020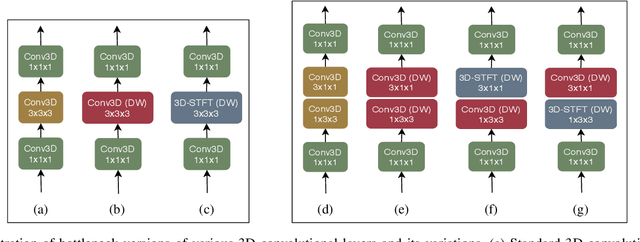
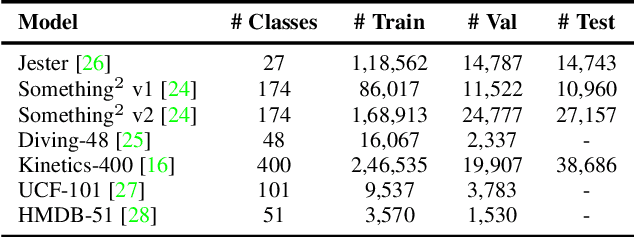
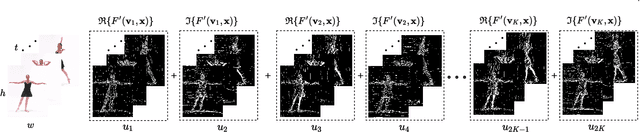
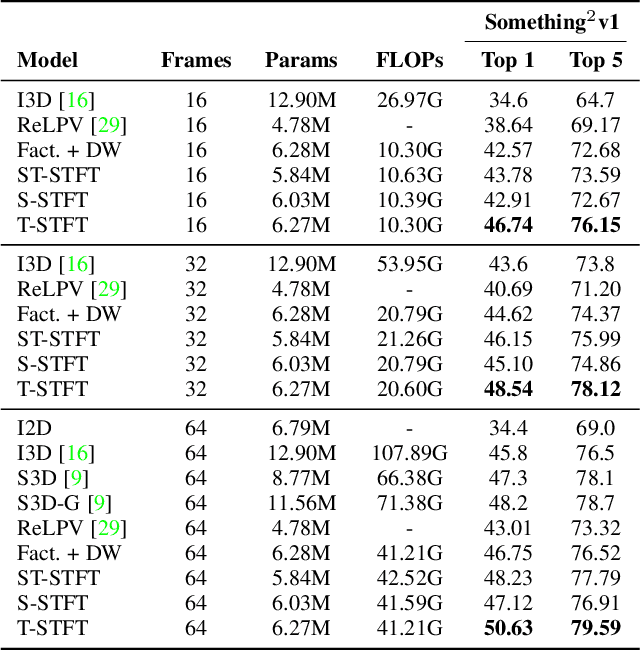
Conventional 3D convolutional neural networks (CNNs) are computationally expensive, memory intensive, prone to overfitting, and most importantly, there is a need to improve their feature learning capabilities. To address these issues, we propose spatio-temporal short term Fourier transform (STFT) blocks, a new class of convolutional blocks that can serve as an alternative to the 3D convolutional layer and its variants in 3D CNNs. An STFT block consists of non-trainable convolution layers that capture spatially and/or temporally local Fourier information using a STFT kernel at multiple low frequency points, followed by a set of trainable linear weights for learning channel correlations. The STFT blocks significantly reduce the space-time complexity in 3D CNNs. In general, they use 3.5 to 4.5 times less parameters and 1.5 to 1.8 times less computational costs when compared to the state-of-the-art methods. Furthermore, their feature learning capabilities are significantly better than the conventional 3D convolutional layer and its variants. Our extensive evaluation on seven action recognition datasets, including Something-something v1 and v2, Jester, Diving-48, Kinetics-400, UCF 101, and HMDB 51, demonstrate that STFT blocks based 3D CNNs achieve on par or even better performance compared to the state-of-the-art methods.
Yoga-82: A New Dataset for Fine-grained Classification of Human Poses
Apr 22, 2020
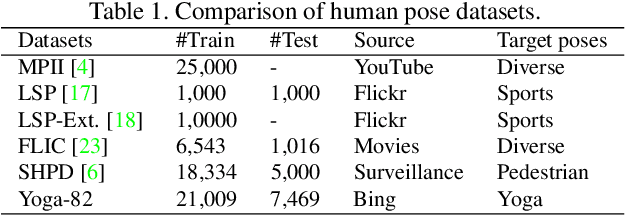

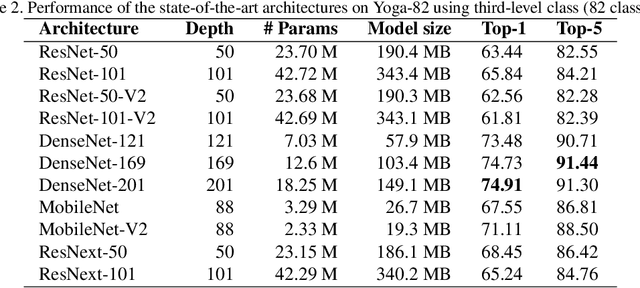
Human pose estimation is a well-known problem in computer vision to locate joint positions. Existing datasets for the learning of poses are observed to be not challenging enough in terms of pose diversity, object occlusion, and viewpoints. This makes the pose annotation process relatively simple and restricts the application of the models that have been trained on them. To handle more variety in human poses, we propose the concept of fine-grained hierarchical pose classification, in which we formulate the pose estimation as a classification task, and propose a dataset, Yoga-82, for large-scale yoga pose recognition with 82 classes. Yoga-82 consists of complex poses where fine annotations may not be possible. To resolve this, we provide hierarchical labels for yoga poses based on the body configuration of the pose. The dataset contains a three-level hierarchy including body positions, variations in body positions, and the actual pose names. We present the classification accuracy of the state-of-the-art convolutional neural network architectures on Yoga-82. We also present several hierarchical variants of DenseNet in order to utilize the hierarchical labels.
Depthwise-STFT based separable Convolutional Neural Networks
Jan 27, 2020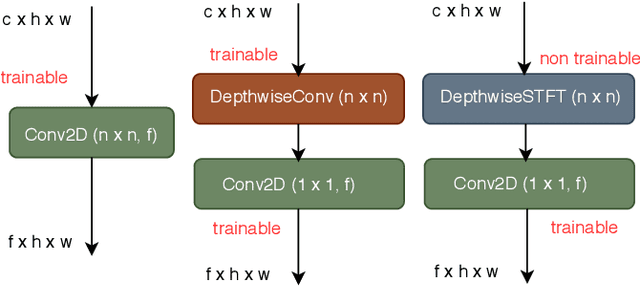


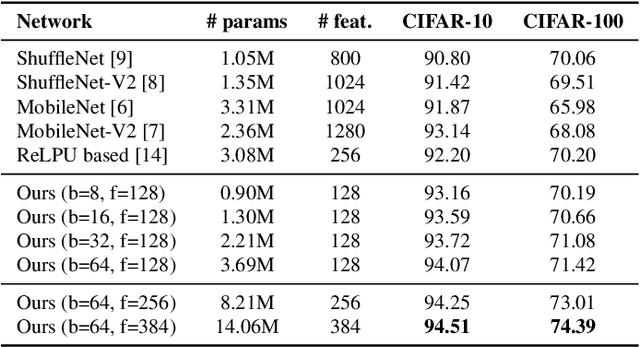
In this paper, we propose a new convolutional layer called Depthwise-STFT Separable layer that can serve as an alternative to the standard depthwise separable convolutional layer. The construction of the proposed layer is inspired by the fact that the Fourier coefficients can accurately represent important features such as edges in an image. It utilizes the Fourier coefficients computed (channelwise) in the 2D local neighborhood (e.g., 3x3) of each position of the input map to obtain the feature maps. The Fourier coefficients are computed using 2D Short Term Fourier Transform (STFT) at multiple fixed low frequency points in the 2D local neighborhood at each position. These feature maps at different frequency points are then linearly combined using trainable pointwise (1x1) convolutions. We show that the proposed layer outperforms the standard depthwise separable layer-based models on the CIFAR-10 and CIFAR-100 image classification datasets with reduced space-time complexity.
PlantDoc: A Dataset for Visual Plant Disease Detection
Nov 23, 2019

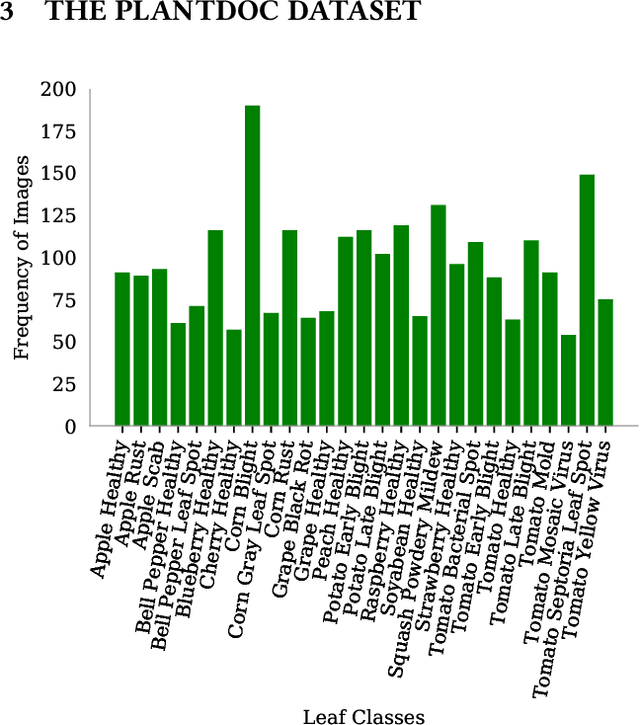
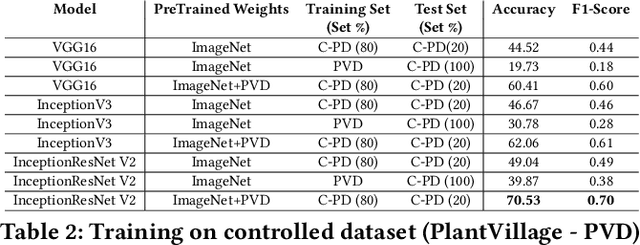
India loses 35% of the annual crop yield due to plant diseases. Early detection of plant diseases remains difficult due to the lack of lab infrastructure and expertise. In this paper, we explore the possibility of computer vision approaches for scalable and early plant disease detection. The lack of availability of sufficiently large-scale non-lab data set remains a major challenge for enabling vision based plant disease detection. Against this background, we present PlantDoc: a dataset for visual plant disease detection. Our dataset contains 2,598 data points in total across 13 plant species and up to 17 classes of diseases, involving approximately 300 human hours of effort in annotating internet scraped images. To show the efficacy of our dataset, we learn 3 models for the task of plant disease classification. Our results show that modelling using our dataset can increase the classification accuracy by up to 31%. We believe that our dataset can help reduce the entry barrier of computer vision techniques in plant disease detection.
Exploring Temporal Differences in 3D Convolutional Neural Networks
Sep 07, 2019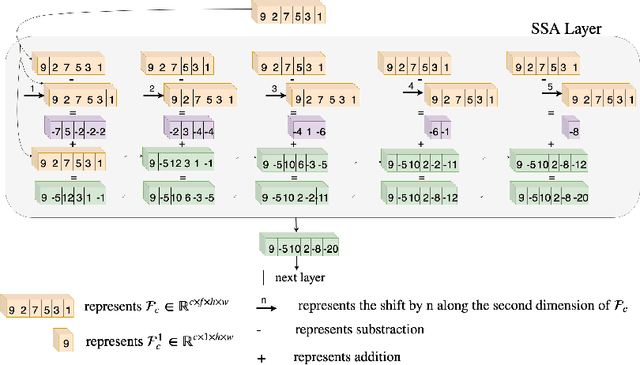
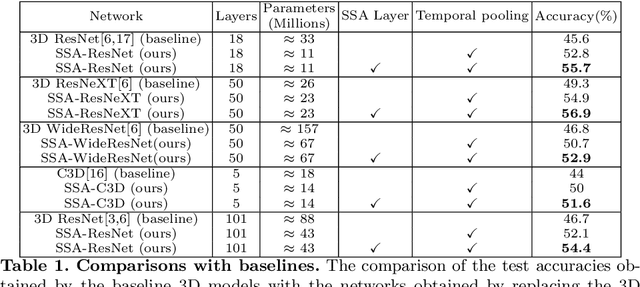
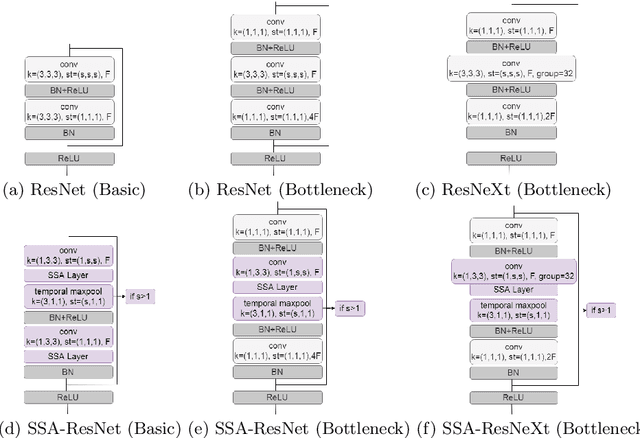

Traditional 3D convolutions are computationally expensive, memory intensive, and due to large number of parameters, they often tend to overfit. On the other hand, 2D CNNs are less computationally expensive and less memory intensive than 3D CNNs and have shown remarkable results in applications like image classification and object recognition. However, in previous works, it has been observed that they are inferior to 3D CNNs when applied on a spatio-temporal input. In this work, we propose a convolutional block which extracts the spatial information by performing a 2D convolution and extracts the temporal information by exploiting temporal differences, i.e., the change in the spatial information at different time instances, using simple operations of shift, subtract and add without utilizing any trainable parameters. The proposed convolutional block has same number of parameters as of a 2D convolution kernel of size nxn, i.e. n^2, and has n times lesser parameters than an nxnxn 3D convolution kernel. We show that the 3D CNNs perform better when the 3D convolution kernels are replaced by the proposed convolutional blocks. We evaluate the proposed convolutional block on UCF101 and ModelNet datasets.
Attentive Spatio-Temporal Representation Learning for Diving Classification
Apr 30, 2019
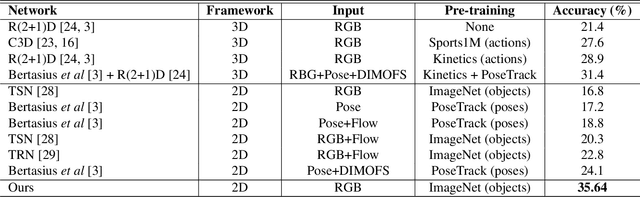
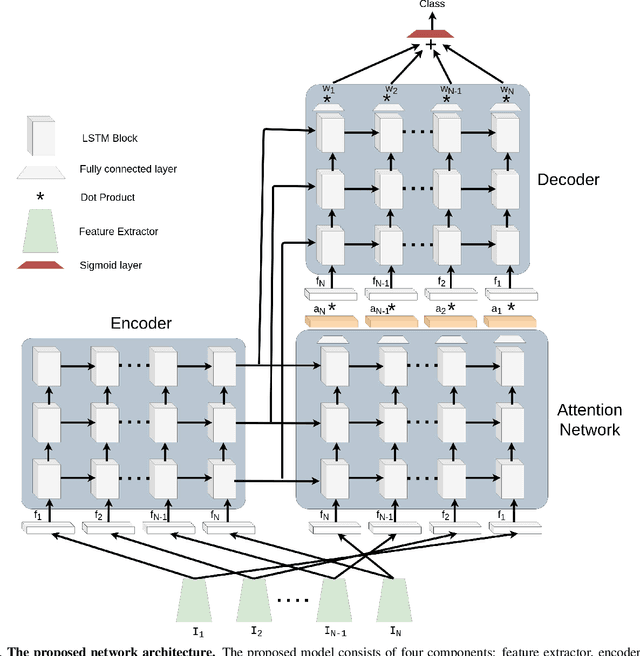

Competitive diving is a well recognized aquatic sport in which a person dives from a platform or a springboard into the water. Based on the acrobatics performed during the dive, diving is classified into a finite set of action classes which are standardized by FINA. In this work, we propose an attention guided LSTM-based neural network architecture for the task of diving classification. The network takes the frames of a diving video as input and determines its class. We evaluate the performance of the proposed model on a recently introduced competitive diving dataset, Diving48. It contains over 18000 video clips which covers 48 classes of diving. The proposed model outperforms the classification accuracy of the state-of-the-art models in both 2D and 3D frameworks by 11.54% and 4.24%, respectively. We show that the network is able to localize the diver in the video frames during the dive without being trained with such a supervision.
LBVCNN: Local Binary Volume Convolutional Neural Network for Facial Expression Recognition from Image Sequences
Apr 16, 2019
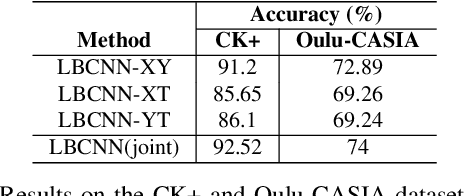
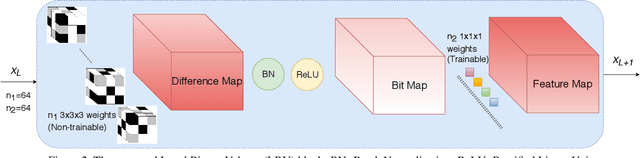
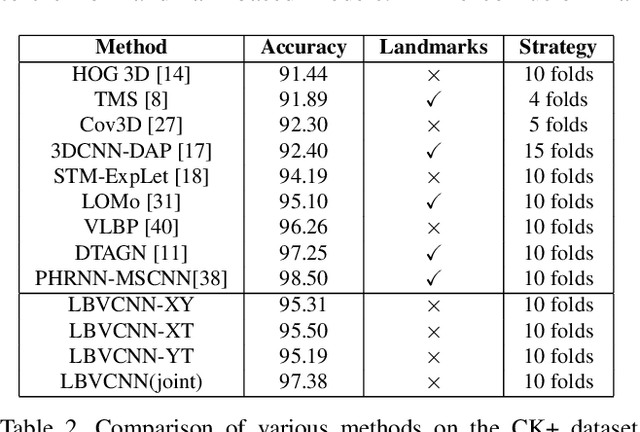
Recognizing facial expressions is one of the central problems in computer vision. Temporal image sequences have useful spatio-temporal features for recognizing expressions. In this paper, we propose a new 3D Convolution Neural Network (CNN) that can be trained end-to-end for facial expression recognition on temporal image sequences without using facial landmarks. More specifically, a novel 3D convolutional layer that we call Local Binary Volume (LBV) layer is proposed. The LBV layer, when used with our newly proposed LBVCNN network, achieve comparable results compared to state-of-the-art landmark-based or without landmark-based models on image sequences from CK+, Oulu-CASIA, and UNBC McMaster shoulder pain datasets. Furthermore, our LBV layer reduces the number of trainable parameters by a significant amount when compared to a conventional 3D convolutional layer. As a matter of fact, when compared to a 3x3x3 conventional 3D convolutional layer, the LBV layer uses 27 times less trainable parameters.
LP-3DCNN: Unveiling Local Phase in 3D Convolutional Neural Networks
Apr 06, 2019
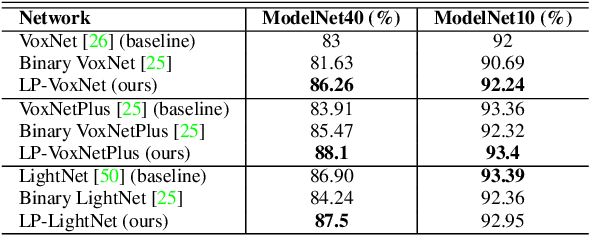
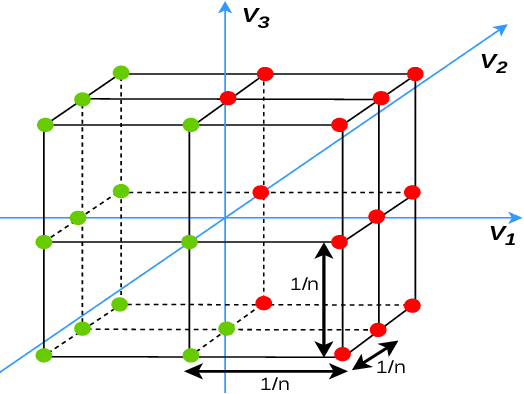
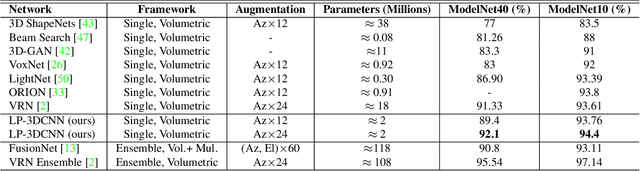
Traditional 3D Convolutional Neural Networks (CNNs) are computationally expensive, memory intensive, prone to overfit, and most importantly, there is a need to improve their feature learning capabilities. To address these issues, we propose Rectified Local Phase Volume (ReLPV) block, an efficient alternative to the standard 3D convolutional layer. The ReLPV block extracts the phase in a 3D local neighborhood (e.g., 3x3x3) of each position of the input map to obtain the feature maps. The phase is extracted by computing 3D Short Term Fourier Transform (STFT) at multiple fixed low frequency points in the 3D local neighborhood of each position. These feature maps at different frequency points are then linearly combined after passing them through an activation function. The ReLPV block provides significant parameter savings of at least, 3^3 to 13^3 times compared to the standard 3D convolutional layer with the filter sizes 3x3x3 to 13x13x13, respectively. We show that the feature learning capabilities of the ReLPV block are significantly better than the standard 3D convolutional layer. Furthermore, it produces consistently better results across different 3D data representations. We achieve state-of-the-art accuracy on the volumetric ModelNet10 and ModelNet40 datasets while utilizing only 11% parameters of the current state-of-the-art. We also improve the state-of-the-art on the UCF-101 split-1 action recognition dataset by 5.68% (when trained from scratch) while using only 15% of the parameters of the state-of-the-art. The project webpage is available at https://sites.google.com/view/lp-3dcnn/home.