 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLBVCNN: Local Binary Volume Convolutional Neural Network for Facial Expression Recognition from Image Sequences
Paper and Code
Apr 16, 2019
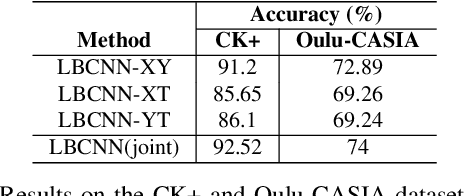
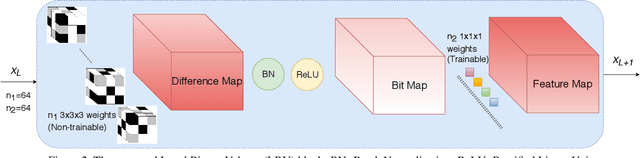
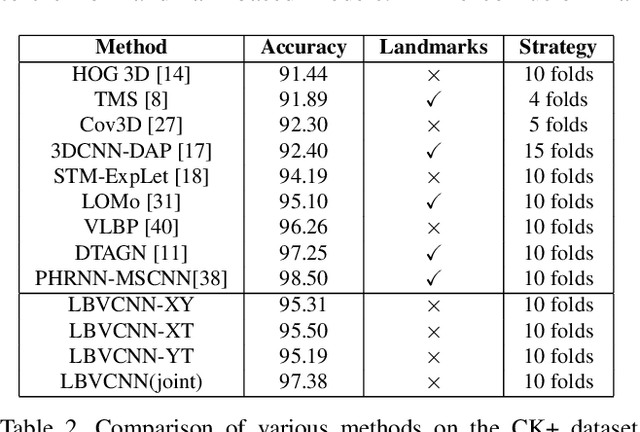
Recognizing facial expressions is one of the central problems in computer vision. Temporal image sequences have useful spatio-temporal features for recognizing expressions. In this paper, we propose a new 3D Convolution Neural Network (CNN) that can be trained end-to-end for facial expression recognition on temporal image sequences without using facial landmarks. More specifically, a novel 3D convolutional layer that we call Local Binary Volume (LBV) layer is proposed. The LBV layer, when used with our newly proposed LBVCNN network, achieve comparable results compared to state-of-the-art landmark-based or without landmark-based models on image sequences from CK+, Oulu-CASIA, and UNBC McMaster shoulder pain datasets. Furthermore, our LBV layer reduces the number of trainable parameters by a significant amount when compared to a conventional 3D convolutional layer. As a matter of fact, when compared to a 3x3x3 conventional 3D convolutional layer, the LBV layer uses 27 times less trainable parameters.