 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShuffleBlock: Shuffle to Regularize Deep Convolutional Neural Networks
Jun 17, 2021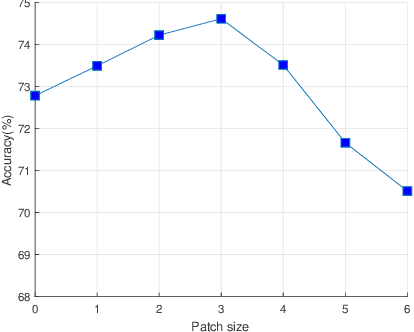
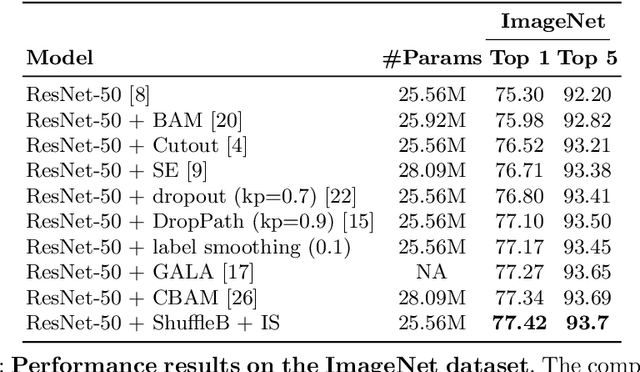
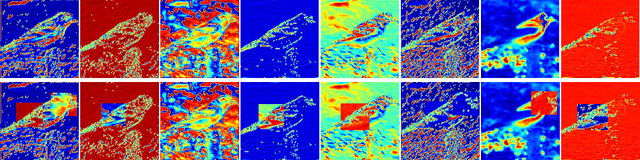
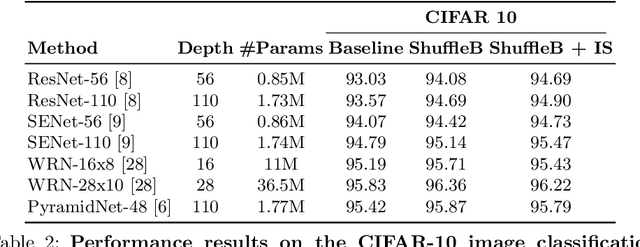
Deep neural networks have enormous representational power which leads them to overfit on most datasets. Thus, regularizing them is important in order to reduce overfitting and enhance their generalization capabilities. Recently, channel shuffle operation has been introduced for mixing channels in group convolutions in resource efficient networks in order to reduce memory and computations. This paper studies the operation of channel shuffle as a regularization technique in deep convolutional networks. We show that while random shuffling of channels during training drastically reduce their performance, however, randomly shuffling small patches between channels significantly improves their performance. The patches to be shuffled are picked from the same spatial locations in the feature maps such that a patch, when transferred from one channel to another, acts as structured noise for the later channel. We call this method "ShuffleBlock". The proposed ShuffleBlock module is easy to implement and improves the performance of several baseline networks on the task of image classification on CIFAR and ImageNet datasets. It also achieves comparable and in many cases better performance than many other regularization methods. We provide several ablation studies on selecting various hyperparameters of the ShuffleBlock module and propose a new scheduling method that further enhances its performance.
Learning to Sort Image Sequences via Accumulated Temporal Differences
Oct 22, 2020
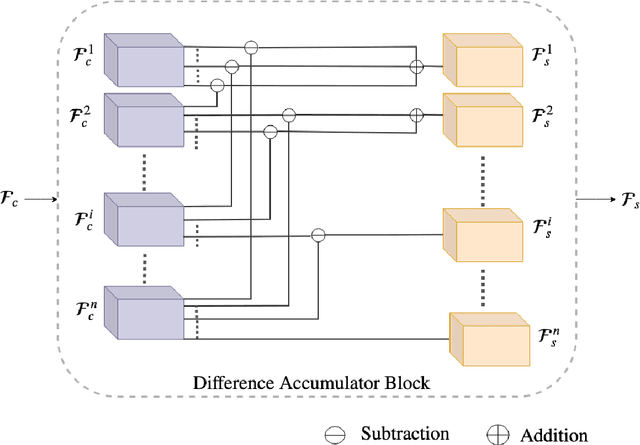

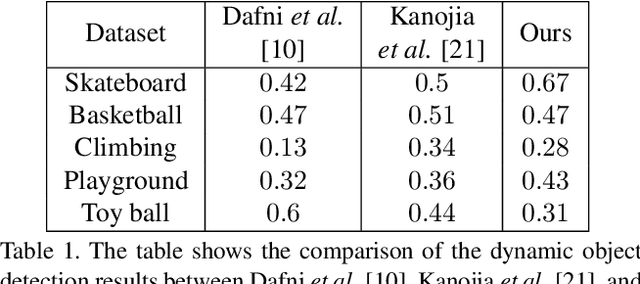
Consider a set of n images of a scene with dynamic objects captured with a static or a handheld camera. Let the temporal order in which these images are captured be unknown. There can be n! possibilities for the temporal order in which these images could have been captured. In this work, we tackle the problem of temporally sequencing the unordered set of images of a dynamic scene captured with a hand-held camera. We propose a convolutional block which captures the spatial information through 2D convolution kernel and captures the temporal information by utilizing the differences present among the feature maps extracted from the input images. We evaluate the performance of the proposed approach on the dataset extracted from a standard action recognition dataset, UCF101. We show that the proposed approach outperforms the state-of-the-art methods by a significant margin. We show that the network generalizes well by evaluating it on a dataset extracted from the DAVIS dataset, a dataset meant for video object segmentation, when the same network was trained with a dataset extracted from UCF101, a dataset meant for action recognition.
Simultaneous Detection and Removal of Dynamic Objects in Multi-view Images
Dec 11, 2019


Consider a set of images of a scene consisting of moving objects captured using a hand-held camera. In this work, we propose an algorithm which takes this set of multi-view images as input, detects the dynamic objects present in the scene, and replaces them with the static regions which are being occluded by them. The proposed algorithm scans the reference image in the row-major order at the pixel level and classifies each pixel as static or dynamic. During the scan, when a pixel is classified as dynamic, the proposed algorithm replaces that pixel value with the corresponding pixel value of the static region which is being occluded by that dynamic region. We show that we achieve artifact-free removal of dynamic objects in multi-view images of several real-world scenes. To the best of our knowledge, we propose the first method which simultaneously detects and removes the dynamic objects present in multi-view images.
Exploring Temporal Differences in 3D Convolutional Neural Networks
Sep 07, 2019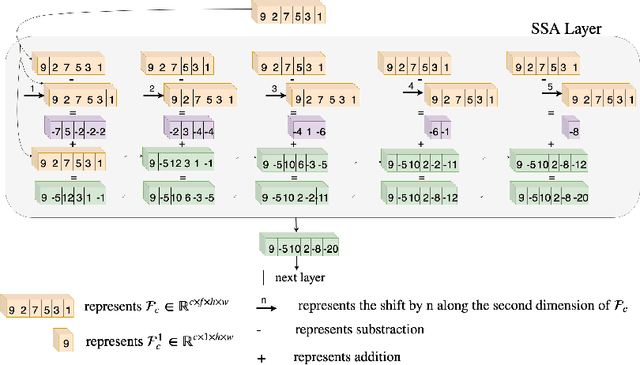
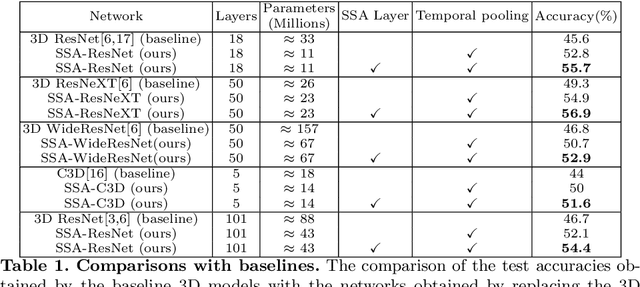
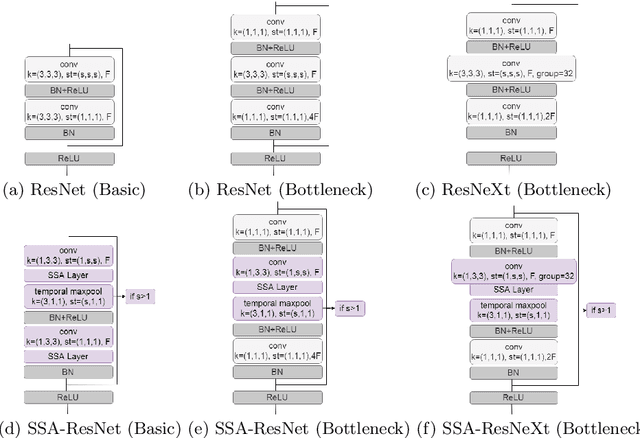

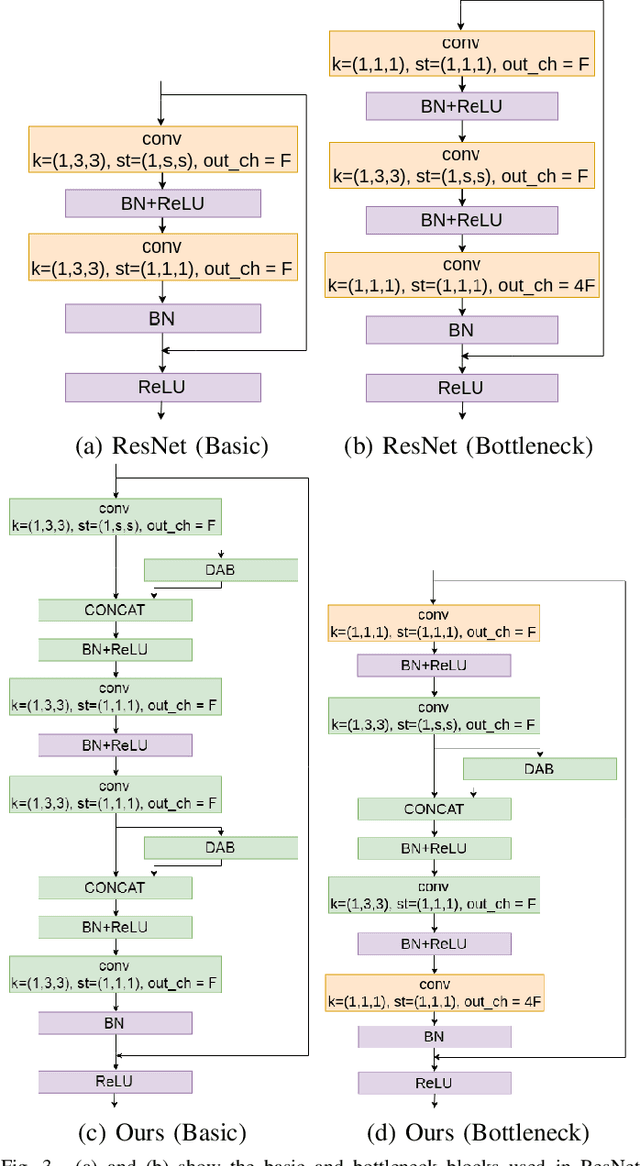
Traditional 3D convolutions are computationally expensive, memory intensive, and due to large number of parameters, they often tend to overfit. On the other hand, 2D CNNs are less computationally expensive and less memory intensive than 3D CNNs and have shown remarkable results in applications like image classification and object recognition. However, in previous works, it has been observed that they are inferior to 3D CNNs when applied on a spatio-temporal input. In this work, we propose a convolutional block which extracts the spatial information by performing a 2D convolution and extracts the temporal information by exploiting temporal differences, i.e., the change in the spatial information at different time instances, using simple operations of shift, subtract and add without utilizing any trainable parameters. The proposed convolutional block has same number of parameters as of a 2D convolution kernel of size nxn, i.e. n^2, and has n times lesser parameters than an nxnxn 3D convolution kernel. We show that the 3D CNNs perform better when the 3D convolution kernels are replaced by the proposed convolutional blocks. We evaluate the proposed convolutional block on UCF101 and ModelNet datasets.
Attentive Spatio-Temporal Representation Learning for Diving Classification
Apr 30, 2019
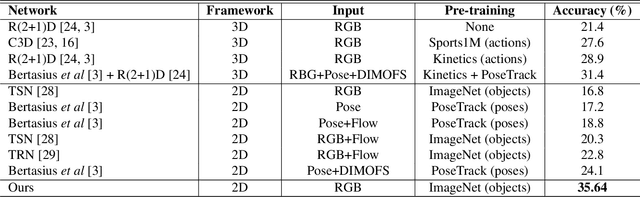
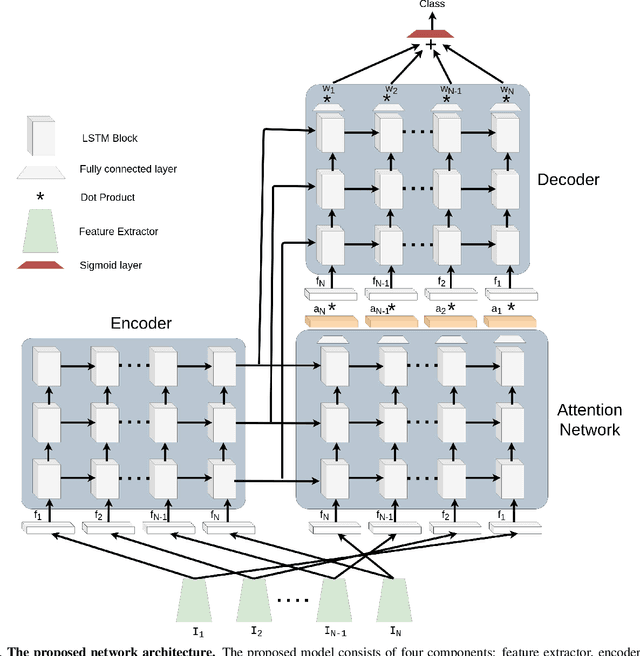

Competitive diving is a well recognized aquatic sport in which a person dives from a platform or a springboard into the water. Based on the acrobatics performed during the dive, diving is classified into a finite set of action classes which are standardized by FINA. In this work, we propose an attention guided LSTM-based neural network architecture for the task of diving classification. The network takes the frames of a diving video as input and determines its class. We evaluate the performance of the proposed model on a recently introduced competitive diving dataset, Diving48. It contains over 18000 video clips which covers 48 classes of diving. The proposed model outperforms the classification accuracy of the state-of-the-art models in both 2D and 3D frameworks by 11.54% and 4.24%, respectively. We show that the network is able to localize the diver in the video frames during the dive without being trained with such a supervision.