 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCalibrated Language Model Fine-Tuning for In- and Out-of-Distribution Data
Oct 22, 2020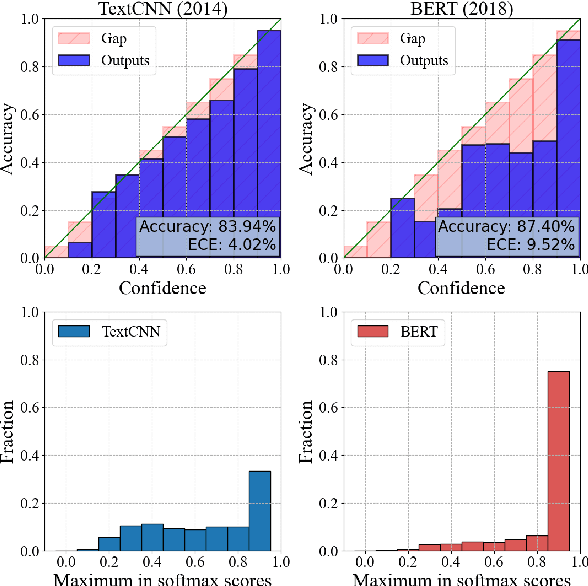
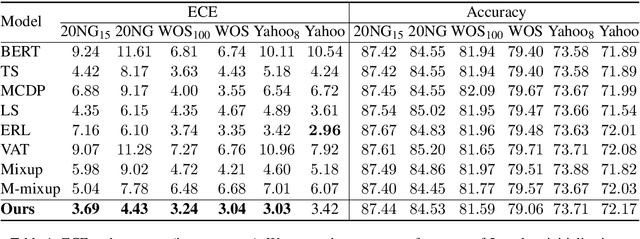
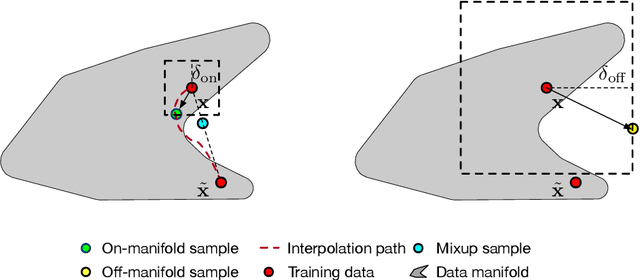
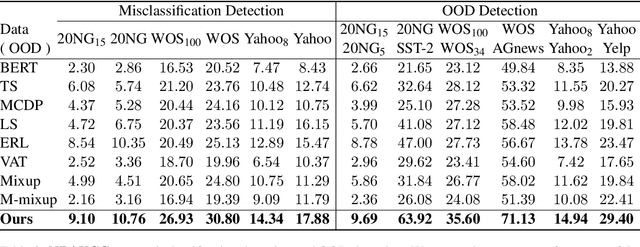
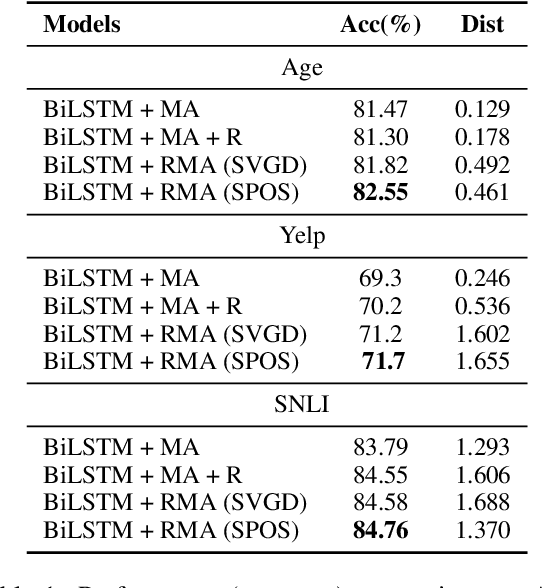
Fine-tuned pre-trained language models can suffer from severe miscalibration for both in-distribution and out-of-distribution (OOD) data due to over-parameterization. To mitigate this issue, we propose a regularized fine-tuning method. Our method introduces two types of regularization for better calibration: (1) On-manifold regularization, which generates pseudo on-manifold samples through interpolation within the data manifold. Augmented training with these pseudo samples imposes a smoothness regularization to improve in-distribution calibration. (2) Off-manifold regularization, which encourages the model to output uniform distributions for pseudo off-manifold samples to address the over-confidence issue for OOD data. Our experiments demonstrate that the proposed method outperforms existing calibration methods for text classification in terms of expectation calibration error, misclassification detection, and OOD detection on six datasets. Our code can be found at https://github.com/Lingkai-Kong/Calibrated-BERT-Fine-Tuning.
Repulsive Attention: Rethinking Multi-head Attention as Bayesian Inference
Sep 20, 2020

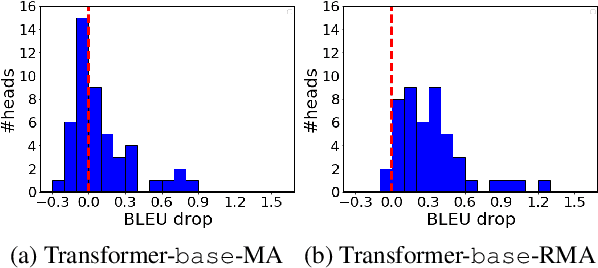
The neural attention mechanism plays an important role in many natural language processing applications. In particular, the use of multi-head attention extends single-head attention by allowing a model to jointly attend information from different perspectives. Without explicit constraining, however, multi-head attention may suffer from attention collapse, an issue that makes different heads extract similar attentive features, thus limiting the model's representation power. In this paper, for the first time, we provide a novel understanding of multi-head attention from a Bayesian perspective. Based on the recently developed particle-optimization sampling techniques, we propose a non-parametric approach that explicitly improves the repulsiveness in multi-head attention and consequently strengthens model's expressiveness. Remarkably, our Bayesian interpretation provides theoretical inspirations on the not-well-understood questions: why and how one uses multi-head attention. Extensive experiments on various attention models and applications demonstrate that the proposed repulsive attention can improve the learned feature diversity, leading to more informative representations with consistent performance improvement on various tasks.
Long-term Multi-granularity Deep Framework for Driver Drowsiness Detection
Jan 08, 2018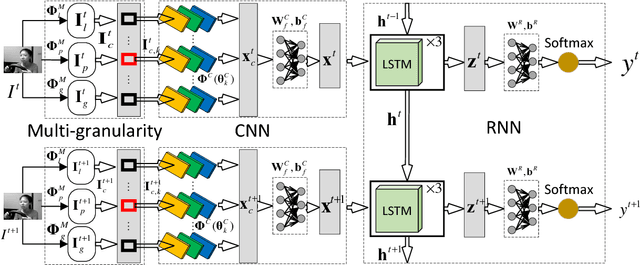



For real-world driver drowsiness detection from videos, the variation of head pose is so large that the existing methods on global face is not capable of extracting effective features, such as looking aside and lowering head. Temporal dependencies with variable length are also rarely considered by the previous approaches, e.g., yawning and speaking. In this paper, we propose a Long-term Multi-granularity Deep Framework to detect driver drowsiness in driving videos containing the frontal faces. The framework includes two key components: (1) Multi-granularity Convolutional Neural Network (MCNN), a novel network utilizes a group of parallel CNN extractors on well-aligned facial patches of different granularities, and extracts facial representations effectively for large variation of head pose, furthermore, it can flexibly fuse both detailed appearance clues of the main parts and local to global spatial constraints; (2) a deep Long Short Term Memory network is applied on facial representations to explore long-term relationships with variable length over sequential frames, which is capable to distinguish the states with temporal dependencies, such as blinking and closing eyes. Our approach achieves 90.05% accuracy and about 37 fps speed on the evaluation set of the public NTHU-DDD dataset, which is the state-of-the-art method on driver drowsiness detection. Moreover, we build a new dataset named FI-DDD, which is of higher precision of drowsy locations in temporal dimension.
Learning Fixation Point Strategy for Object Detection and Classification
Dec 19, 2017


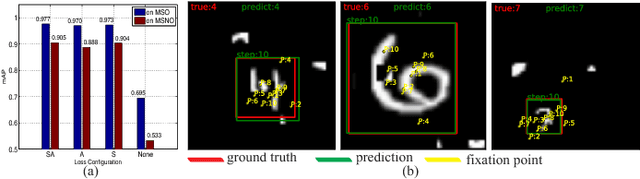
We propose a novel recurrent attentional structure to localize and recognize objects jointly. The network can learn to extract a sequence of local observations with detailed appearance and rough context, instead of sliding windows or convolutions on the entire image. Meanwhile, those observations are fused to complete detection and classification tasks. On training, we present a hybrid loss function to learn the parameters of the multi-task network end-to-end. Particularly, the combination of stochastic and object-awareness strategy, named SA, can select more abundant context and ensure the last fixation close to the object. In addition, we build a real-world dataset to verify the capacity of our method in detecting the object of interest including those small ones. Our method can predict a precise bounding box on an image, and achieve high speed on large images without pooling operations. Experimental results indicate that the proposed method can mine effective context by several local observations. Moreover, the precision and speed are easily improved by changing the number of recurrent steps. Finally, we will open the source code of our proposed approach.