 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeManagers versus Machines: Do Algorithms Replicate Human Intuition in Credit Ratings?
Feb 09, 2022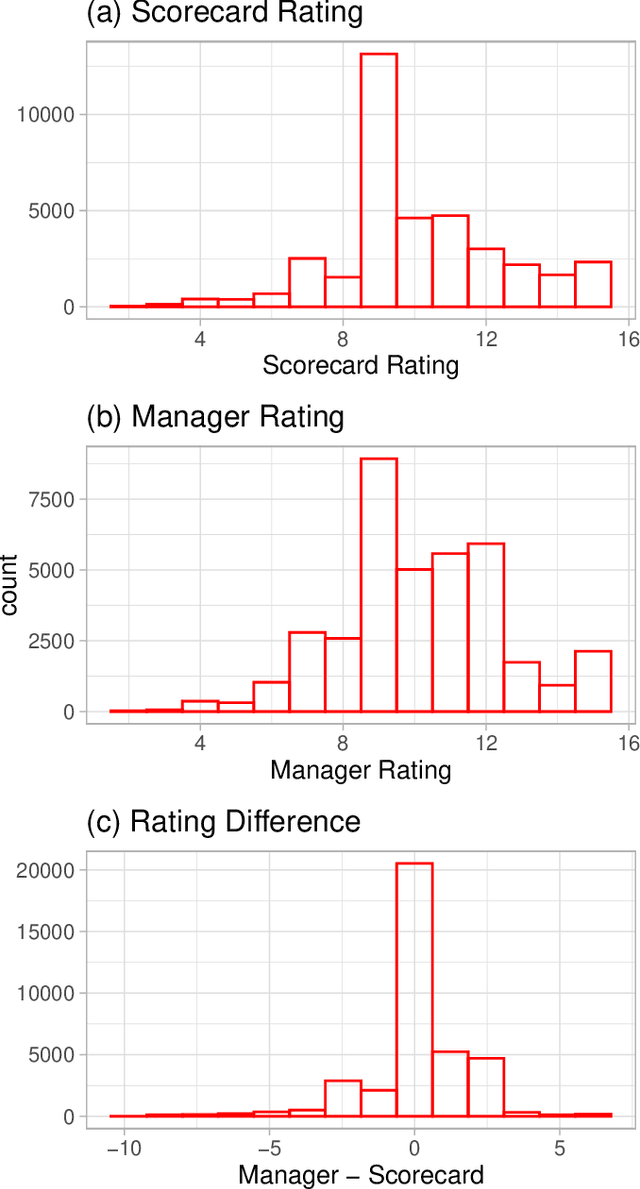
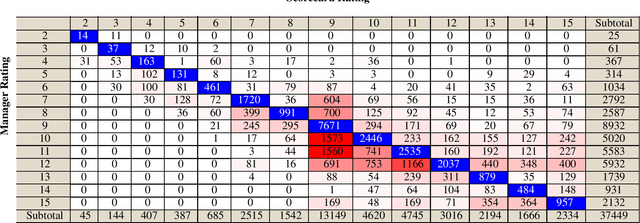
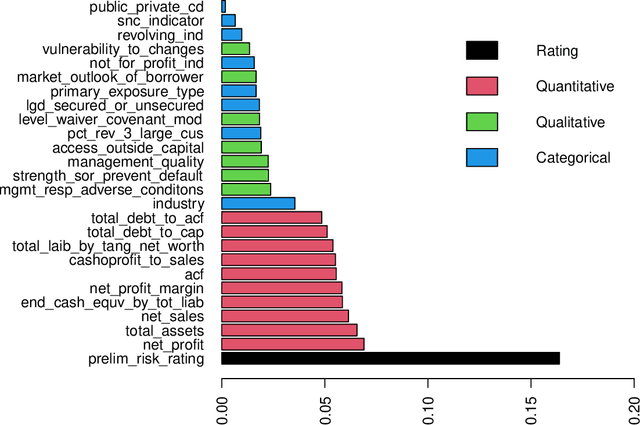

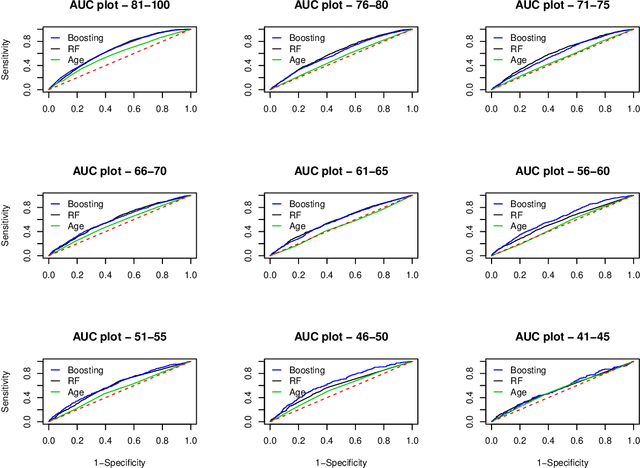
We use machine learning techniques to investigate whether it is possible to replicate the behavior of bank managers who assess the risk of commercial loans made by a large commercial US bank. Even though a typical bank already relies on an algorithmic scorecard process to evaluate risk, bank managers are given significant latitude in adjusting the risk score in order to account for other holistic factors based on their intuition and experience. We show that it is possible to find machine learning algorithms that can replicate the behavior of the bank managers. The input to the algorithms consists of a combination of standard financials and soft information available to bank managers as part of the typical loan review process. We also document the presence of significant heterogeneity in the adjustment process that can be traced to differences across managers and industries. Our results highlight the effectiveness of machine learning based analytic approaches to banking and the potential challenges to high-skill jobs in the financial sector.
Predicting Mortality from Credit Reports
Nov 05, 2021

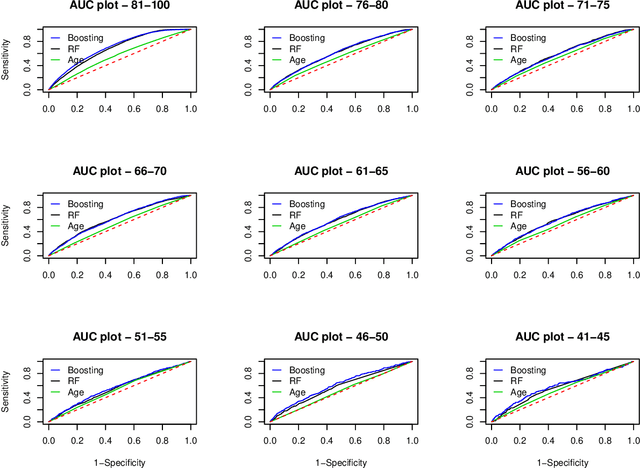
Data on hundreds of variables related to individual consumer finance behavior (such as credit card and loan activity) is routinely collected in many countries and plays an important role in lending decisions. We postulate that the detailed nature of this data may be used to predict outcomes in seemingly unrelated domains such as individual health. We build a series of machine learning models to demonstrate that credit report data can be used to predict individual mortality. Variable groups related to credit cards and various loans, mostly unsecured loans, are shown to carry significant predictive power. Lags of these variables are also significant thus indicating that dynamics also matters. Improved mortality predictions based on consumer finance data can have important economic implications in insurance markets but may also raise privacy concerns.
A Panel Quantile Approach to Attrition Bias in Big Data: Evidence from a Randomized Experiment
Aug 09, 2018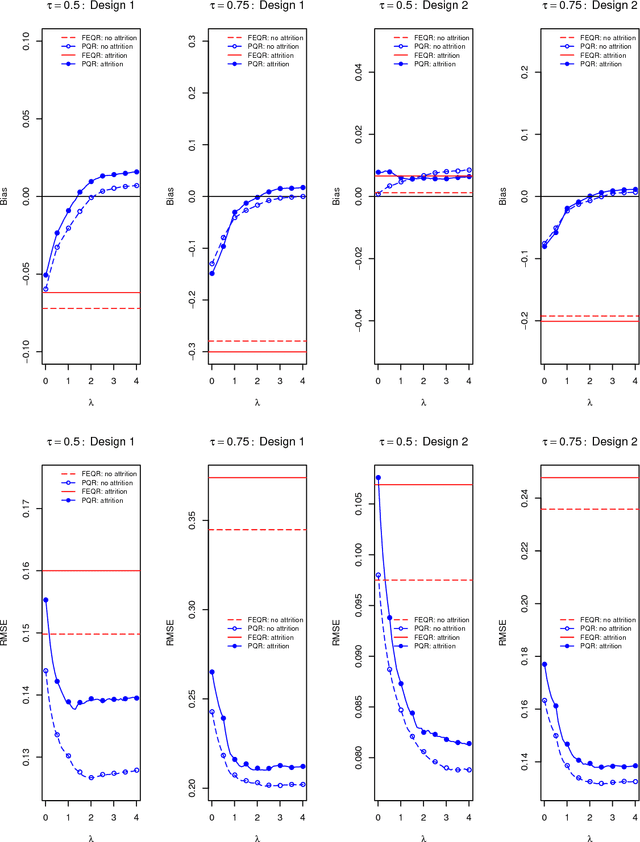
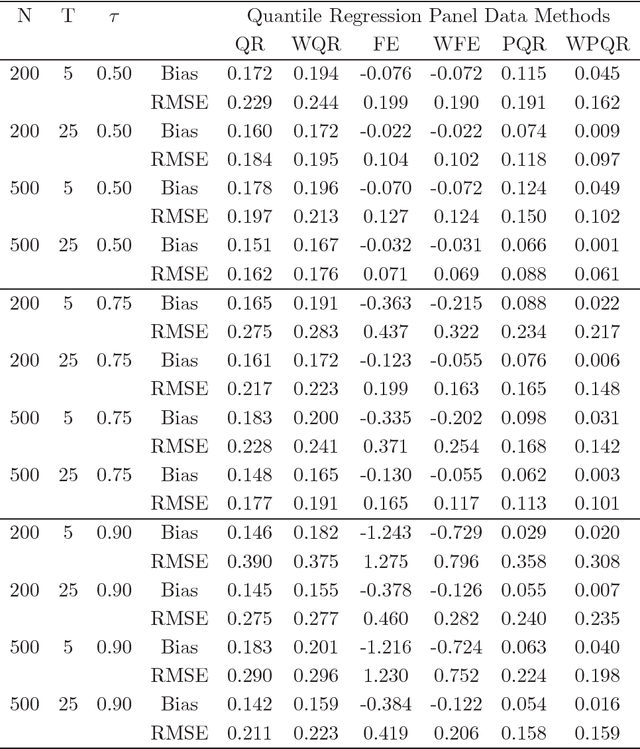
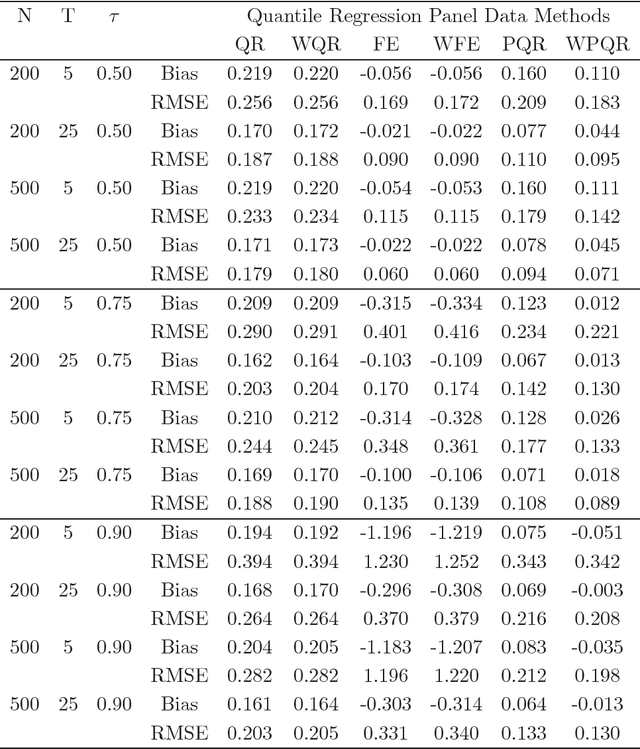
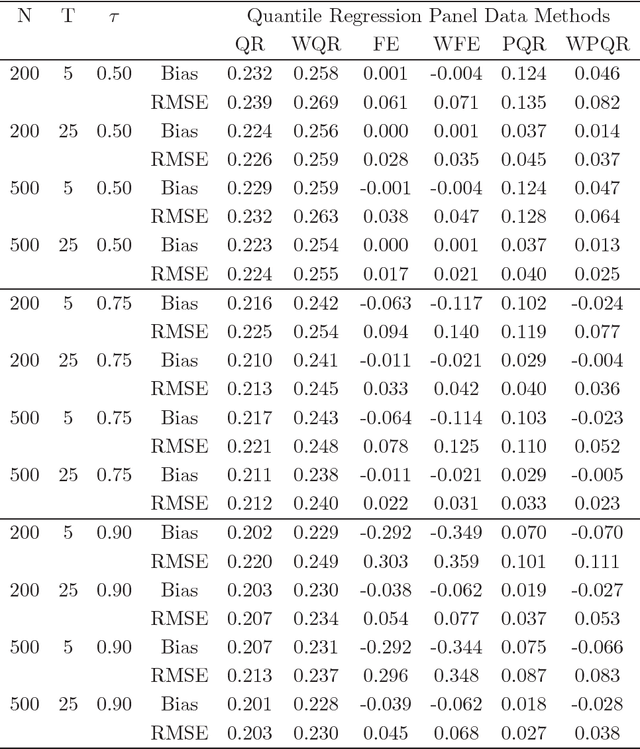
This paper introduces a quantile regression estimator for panel data models with individual heterogeneity and attrition. The method is motivated by the fact that attrition bias is often encountered in Big Data applications. For example, many users sign-up for the latest program but few remain active users several months later, making the evaluation of such interventions inherently very challenging. Building on earlier work by Hausman and Wise (1979), we provide a simple identification strategy that leads to a two-step estimation procedure. In the first step, the coefficients of interest in the selection equation are consistently estimated using parametric or nonparametric methods. In the second step, standard panel quantile methods are employed on a subset of weighted observations. The estimator is computationally easy to implement in Big Data applications with a large number of subjects. We investigate the conditions under which the parameter estimator is asymptotically Gaussian and we carry out a series of Monte Carlo simulations to investigate the finite sample properties of the estimator. Lastly, using a simulation exercise, we apply the method to the evaluation of a recent Time-of-Day electricity pricing experiment inspired by the work of Aigner and Hausman (1980).
Scalable Bayesian Non-Negative Tensor Factorization for Massive Count Data
Aug 18, 2015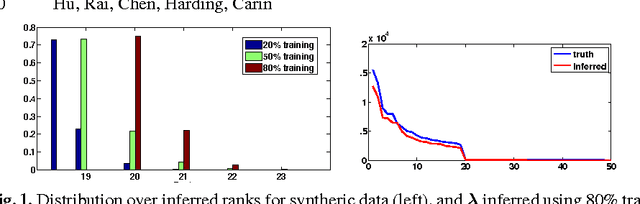
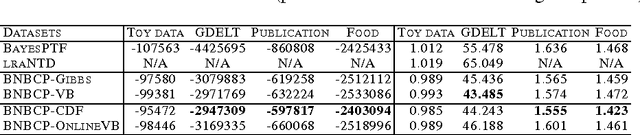
We present a Bayesian non-negative tensor factorization model for count-valued tensor data, and develop scalable inference algorithms (both batch and online) for dealing with massive tensors. Our generative model can handle overdispersed counts as well as infer the rank of the decomposition. Moreover, leveraging a reparameterization of the Poisson distribution as a multinomial facilitates conjugacy in the model and enables simple and efficient Gibbs sampling and variational Bayes (VB) inference updates, with a computational cost that only depends on the number of nonzeros in the tensor. The model also provides a nice interpretability for the factors; in our model, each factor corresponds to a "topic". We develop a set of online inference algorithms that allow further scaling up the model to massive tensors, for which batch inference methods may be infeasible. We apply our framework on diverse real-world applications, such as \emph{multiway} topic modeling on a scientific publications database, analyzing a political science data set, and analyzing a massive household transactions data set.