 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting Mortality from Credit Reports
Nov 05, 2021
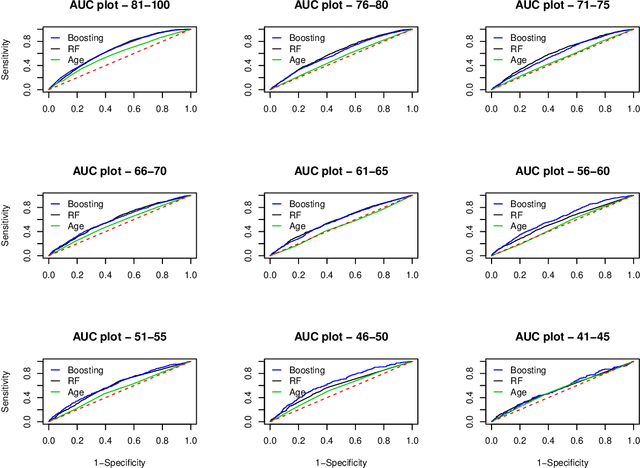

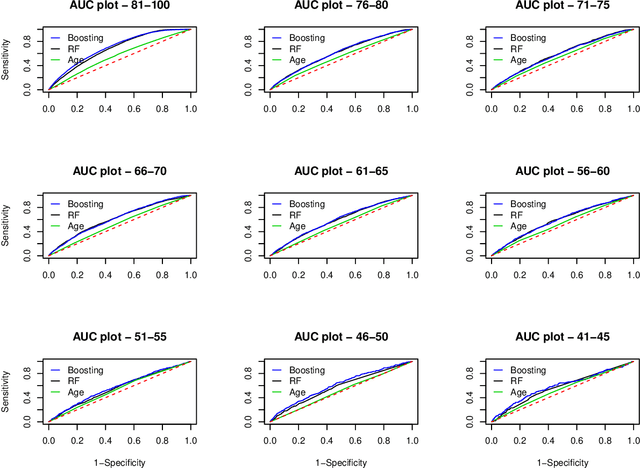
Data on hundreds of variables related to individual consumer finance behavior (such as credit card and loan activity) is routinely collected in many countries and plays an important role in lending decisions. We postulate that the detailed nature of this data may be used to predict outcomes in seemingly unrelated domains such as individual health. We build a series of machine learning models to demonstrate that credit report data can be used to predict individual mortality. Variable groups related to credit cards and various loans, mostly unsecured loans, are shown to carry significant predictive power. Lags of these variables are also significant thus indicating that dynamics also matters. Improved mortality predictions based on consumer finance data can have important economic implications in insurance markets but may also raise privacy concerns.
Sharpe Ratio in High Dimensions: Cases of Maximum Out of Sample, Constrained Maximum, and Optimal Portfolio Choice
Feb 05, 2020



In this paper, we analyze maximum Sharpe ratio when the number of assets in a portfolio is larger than its time span. One obstacle in this large dimensional setup is the singularity of the sample covariance matrix of the excess asset returns. To solve this issue, we benefit from a technique called nodewise regression, which was developed by Meinshausen and Buhlmann (2006). It provides a sparse/weakly sparse and consistent estimate of the precision matrix, using the Lasso method. We analyze three issues. One of the key results in our paper is that mean-variance efficiency for the portfolios in large dimensions is established. Then tied to that result, we also show that the maximum out-of-sample Sharpe ratio can be consistently estimated in this large portfolio of assets. Furthermore, we provide convergence rates and see that the number of assets slow down the convergence up to a logarithmic factor. Then, we provide consistency of maximum Sharpe Ratio when the portfolio weights add up to one, and also provide a new formula and an estimate for constrained maximum Sharpe ratio. Finally, we provide consistent estimates of the Sharpe ratios of global minimum variance portfolio and Markowitz's (1952) mean variance portfolio. In terms of assumptions, we allow for time series data. Simulation and out-of-sample forecasting exercise shows that our new method performs well compared to factor and shrinkage based techniques.
BooST: Boosting Smooth Trees for Partial Effect Estimation in Nonlinear Regressions
Aug 20, 2018

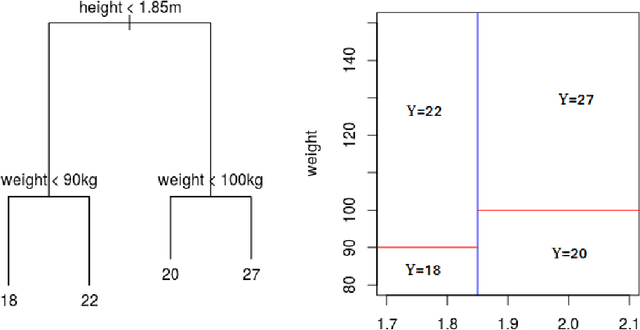

In this paper we introduce a new machine learning (ML) model for nonlinear regression called Boosting Smooth Transition Regression Trees (BooST). The main advantage of the BooST model is that it estimates the derivatives (partial effects) of very general nonlinear models, providing more interpretation about the mapping between the covariates and the dependent variable than other tree based models, such as Random Forests. We provide some asymptotic theory that shows consistency of the partial derivative estimates and we present some examples on both simulated and real data.