 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePGR-Net: Prior-Guided ROI Reasoning Network for Brain Tumor MRI Segmentation
Mar 23, 2026Brain tumor MRI segmentation is essential for clinical diagnosis and treatment planning, enabling accurate lesion detection and radiotherapy target delineation. However, tumor lesions occupy only a small fraction of the volumetric space, resulting in severe spatial sparsity, while existing segmentation networks often overlook clinically observed spatial priors of tumor occurrence, leading to redundant feature computation over extensive background regions. To address this issue, we propose PGR-Net (Prior-Guided ROI Reasoning Network) - an explicit ROI-aware framework that incorporates a data-driven spatial prior set to capture the distribution and scale characteristics of tumor lesions, providing global guidance for more stable segmentation. Leveraging these priors, PGR-Net introduces a hierarchical Top-K ROI decision mechanism that progressively selects the most confident lesion candidate regions across encoder layers to improve localization precision. We further develop the WinGS-ROI (Windowed Gaussian-Spatial Decay ROI) module, which uses multi-window Gaussian templates with a spatial decay function to produce center-enhanced guidance maps, thus directing feature learning throughout the network. With these ROI features, a windowed RetNet backbone is adopted to enhance localization reliability. Experiments on BraTS-2019/2023 and MSD Task01 show that PGR-Net consistently outperforms existing approaches while using only 8.64M Params, achieving Dice scores of 89.02%, 91.82%, and 89.67% on the Whole Tumor region. Code is available at https://github.com/CNU-MedAI-Lab/PGR-Net.
DI3CL: Contrastive Learning With Dynamic Instances and Contour Consistency for SAR Land-Cover Classification Foundation Model
Nov 12, 2025Although significant advances have been achieved in SAR land-cover classification, recent methods remain predominantly focused on supervised learning, which relies heavily on extensive labeled datasets. This dependency not only limits scalability and generalization but also restricts adaptability to diverse application scenarios. In this paper, a general-purpose foundation model for SAR land-cover classification is developed, serving as a robust cornerstone to accelerate the development and deployment of various downstream models. Specifically, a Dynamic Instance and Contour Consistency Contrastive Learning (DI3CL) pre-training framework is presented, which incorporates a Dynamic Instance (DI) module and a Contour Consistency (CC) module. DI module enhances global contextual awareness by enforcing local consistency across different views of the same region. CC module leverages shallow feature maps to guide the model to focus on the geometric contours of SAR land-cover objects, thereby improving structural discrimination. Additionally, to enhance robustness and generalization during pre-training, a large-scale and diverse dataset named SARSense, comprising 460,532 SAR images, is constructed to enable the model to capture comprehensive and representative features. To evaluate the generalization capability of our foundation model, we conducted extensive experiments across a variety of SAR land-cover classification tasks, including SAR land-cover mapping, water body detection, and road extraction. The results consistently demonstrate that the proposed DI3CL outperforms existing methods. Our code and pre-trained weights are publicly available at: https://github.com/SARpre-train/DI3CL.
M-Net: MRI Brain Tumor Sequential Segmentation Network via Mesh-Cast
Jul 28, 2025MRI tumor segmentation remains a critical challenge in medical imaging, where volumetric analysis faces unique computational demands due to the complexity of 3D data. The spatially sequential arrangement of adjacent MRI slices provides valuable information that enhances segmentation continuity and accuracy, yet this characteristic remains underutilized in many existing models. The spatial correlations between adjacent MRI slices can be regarded as "temporal-like" data, similar to frame sequences in video segmentation tasks. To bridge this gap, we propose M-Net, a flexible framework specifically designed for sequential image segmentation. M-Net introduces the novel Mesh-Cast mechanism, which seamlessly integrates arbitrary sequential models into the processing of both channel and temporal information, thereby systematically capturing the inherent "temporal-like" spatial correlations between MRI slices. Additionally, we define an MRI sequential input pattern and design a Two-Phase Sequential (TPS) training strategy, which first focuses on learning common patterns across sequences before refining slice-specific feature extraction. This approach leverages temporal modeling techniques to preserve volumetric contextual information while avoiding the high computational cost of full 3D convolutions, thereby enhancing the generalizability and robustness of M-Net in sequential segmentation tasks. Experiments on the BraTS2019 and BraTS2023 datasets demonstrate that M-Net outperforms existing methods across all key metrics, establishing itself as a robust solution for temporally-aware MRI tumor segmentation.
UniReal: Universal Image Generation and Editing via Learning Real-world Dynamics
Dec 10, 2024



We introduce UniReal, a unified framework designed to address various image generation and editing tasks. Existing solutions often vary by tasks, yet share fundamental principles: preserving consistency between inputs and outputs while capturing visual variations. Inspired by recent video generation models that effectively balance consistency and variation across frames, we propose a unifying approach that treats image-level tasks as discontinuous video generation. Specifically, we treat varying numbers of input and output images as frames, enabling seamless support for tasks such as image generation, editing, customization, composition, etc. Although designed for image-level tasks, we leverage videos as a scalable source for universal supervision. UniReal learns world dynamics from large-scale videos, demonstrating advanced capability in handling shadows, reflections, pose variation, and object interaction, while also exhibiting emergent capability for novel applications.
Causal Interventional Prediction System for Robust and Explainable Effect Forecasting
Jul 29, 2024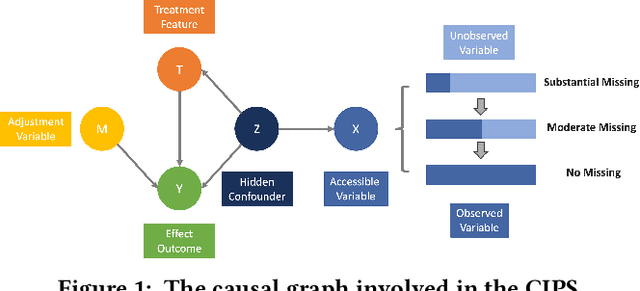
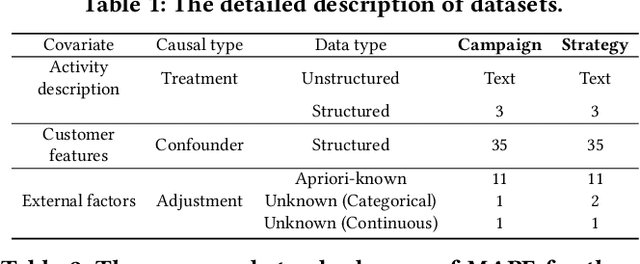
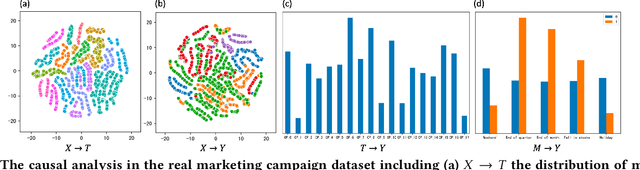
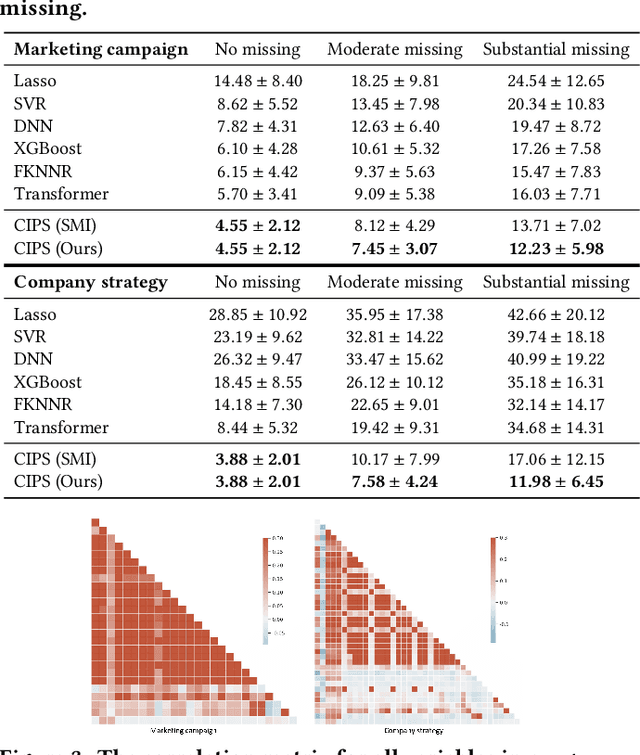
Although the widespread use of AI systems in today's world is growing, many current AI systems are found vulnerable due to hidden bias and missing information, especially in the most commonly used forecasting system. In this work, we explore the robustness and explainability of AI-based forecasting systems. We provide an in-depth analysis of the underlying causality involved in the effect prediction task and further establish a causal graph based on treatment, adjustment variable, confounder, and outcome. Correspondingly, we design a causal interventional prediction system (CIPS) based on a variational autoencoder and fully conditional specification of multiple imputations. Extensive results demonstrate the superiority of our system over state-of-the-art methods and show remarkable versatility and extensibility in practice.
Navigate Biopsy with Ultrasound under Augmented Reality Device: Towards Higher System Performance
Feb 04, 2024
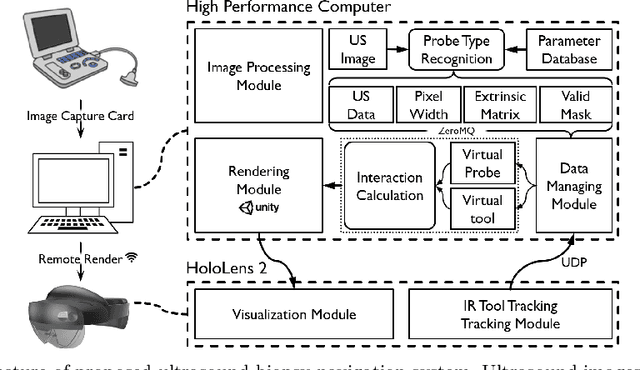
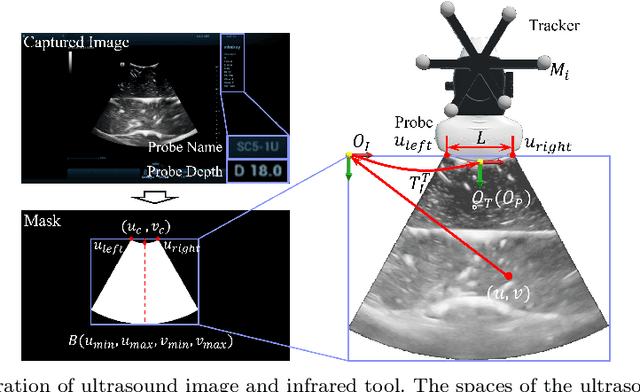
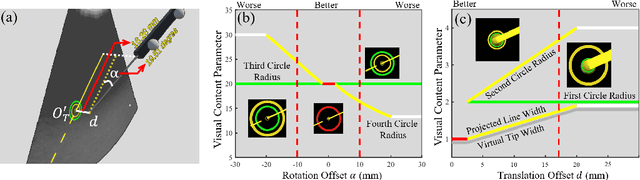
Purpose: Biopsies play a crucial role in determining the classification and staging of tumors. Ultrasound is frequently used in this procedure to provide real-time anatomical information. Using augmented reality (AR), surgeons can visualize ultrasound data and spatial navigation information seamlessly integrated with real tissues. This innovation facilitates faster and more precise biopsy operations. Methods: We developed an AR biopsy navigation system with low display latency and high accuracy. Ultrasound data is initially read by an image capture card and streamed to Unity via net communication. In Unity, navigation information is rendered and transmitted to the HoloLens 2 device using holographic remoting. Retro-reflective tool tracking is implemented on the HoloLens 2, enabling simultaneous tracking of the ultrasound probe and biopsy needle. Distinct navigation information is provided during in-plane and out-of-plane punctuation. To evaluate the effectiveness of our system, we conducted a study involving ten participants, for puncture accuracy and biopsy time, comparing to traditional methods. Results: Our proposed framework enables ultrasound visualization in AR with only $16.22\pm11.45ms$ additional latency. Navigation accuracy reached $1.23\pm 0.68mm$ in the image plane and $0.95\pm 0.70mm$ outside the image plane. Remarkably, the utilization of our system led to $98\%$ and $95\%$ success rate in out-of-plane and in-plane biopsy. Conclusion: To sum up, this paper introduces an AR-based ultrasound biopsy navigation system characterized by high navigation accuracy and minimal latency. The system provides distinct visualization contents during in-plane and out-of-plane operations according to their different characteristics. Use case study in this paper proved that our system can help young surgeons perform biopsy faster and more accurately.
Social-Mobility-Aware Joint Communication and Computation Resource Management in NOMA-Enabled Vehicular Networks
Jul 08, 2023



The existing computation and communication (2C) optimization schemes for vehicular edge computing (VEC) networks mainly focus on the physical domain without considering the influence from the social domain. This may greatly limit the potential of task offloading, making it difficult to fully boom the task offloading rate with given power, resulting in low energy efficiency (EE). To address the issue, this letter devotes itself to investigate social-mobility-aware VEC framework and proposes a novel EE-oriented 2C assignment scheme. In doing so, we assume that the task vehicular user (T-VU) can offload computation tasks to the service vehicular user (S-VU) and the road side unit (RSU) by non-orthogonal multiple access (NOMA). An optimization problem is formulated to jointly assign the 2C resources to maximize the system EE, which turns out to be a mixed integer non-convex objective function. To solve the problem, we transform it into separated computation and communication resource allocation subproblems. Dealing with the first subproblem, we propose a social-mobility-aware edge server selection and task splitting algorithm (SM-SSTSA) to achieve edge server selection and task splitting. Then, by solving the second subproblem, the power allocation and spectrum assignment solutions are obtained utilizing a tightening lower bound method and a Kuhn-Munkres algorithm. Finally, we solve the original problem through an iterative method. Simulation results demonstrate the superior EE performance of the proposed scheme.
EVD Surgical Guidance with Retro-Reflective Tool Tracking and Spatial Reconstruction using Head-Mounted Augmented Reality Device
Jul 03, 2023



Augmented Reality (AR) has been used to facilitate surgical guidance during External Ventricular Drain (EVD) surgery, reducing the risks of misplacement in manual operations. During this procedure, the key challenge is accurately estimating the spatial relationship between pre-operative images and actual patient anatomy in AR environment. This research proposes a novel framework utilizing Time of Flight (ToF) depth sensors integrated in commercially available AR Head Mounted Devices (HMD) for precise EVD surgical guidance. As previous studies have proven depth errors for ToF sensors, we first assessed their properties on AR-HMDs. Subsequently, a depth error model and patient-specific parameter identification method are introduced for accurate surface information. A tracking pipeline combining retro-reflective markers and point clouds is then proposed for accurate head tracking. The head surface is reconstructed using depth data for spatial registration, avoiding fixing tracking targets rigidly on the patient's skull. Firstly, $7.580\pm 1.488 mm$ depth value error was revealed on human skin, indicating the significance of depth correction. Our results showed that the error was reduced by over $85\%$ using proposed depth correction method on head phantoms in different materials. Meanwhile, the head surface reconstructed with corrected depth data achieved sub-millimetre accuracy. An experiment on sheep head revealed $0.79 mm$ reconstruction error. Furthermore, a user study was conducted for the performance in simulated EVD surgery, where five surgeons performed nine k-wire injections on a head phantom with virtual guidance. Results of this study revealed $2.09 \pm 0.16 mm$ translational accuracy and $2.97\pm 0.91$ degree orientational accuracy.
PolyFormer: Referring Image Segmentation as Sequential Polygon Generation
Feb 14, 2023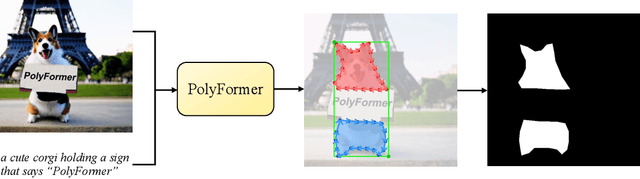
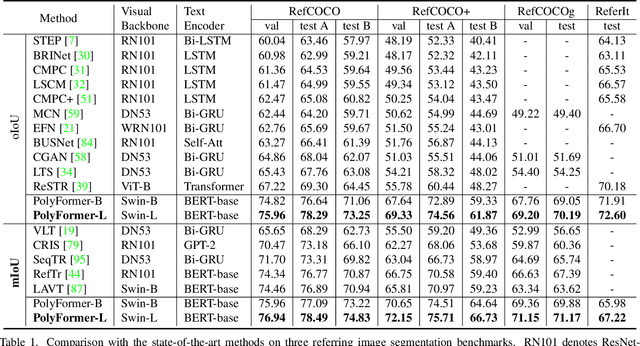
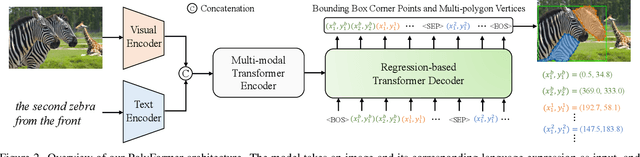
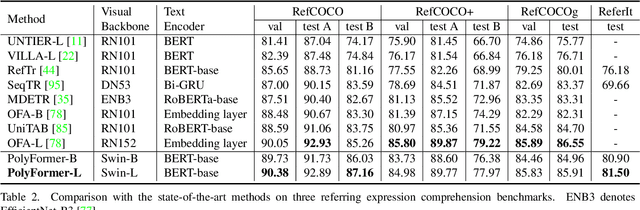
In this work, instead of directly predicting the pixel-level segmentation masks, the problem of referring image segmentation is formulated as sequential polygon generation, and the predicted polygons can be later converted into segmentation masks. This is enabled by a new sequence-to-sequence framework, Polygon Transformer (PolyFormer), which takes a sequence of image patches and text query tokens as input, and outputs a sequence of polygon vertices autoregressively. For more accurate geometric localization, we propose a regression-based decoder, which predicts the precise floating-point coordinates directly, without any coordinate quantization error. In the experiments, PolyFormer outperforms the prior art by a clear margin, e.g., 5.40% and 4.52% absolute improvements on the challenging RefCOCO+ and RefCOCOg datasets. It also shows strong generalization ability when evaluated on the referring video segmentation task without fine-tuning, e.g., achieving competitive 61.5% J&F on the Ref-DAVIS17 dataset.
Hierarchical Capsule Prediction Network for Marketing Campaigns Effect
Aug 22, 2022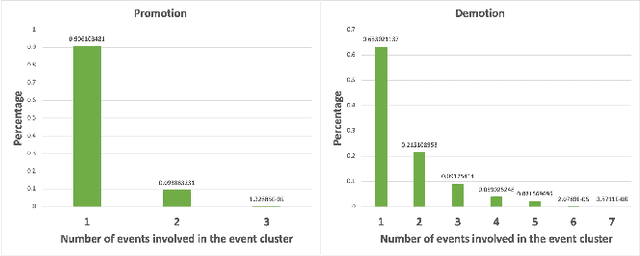
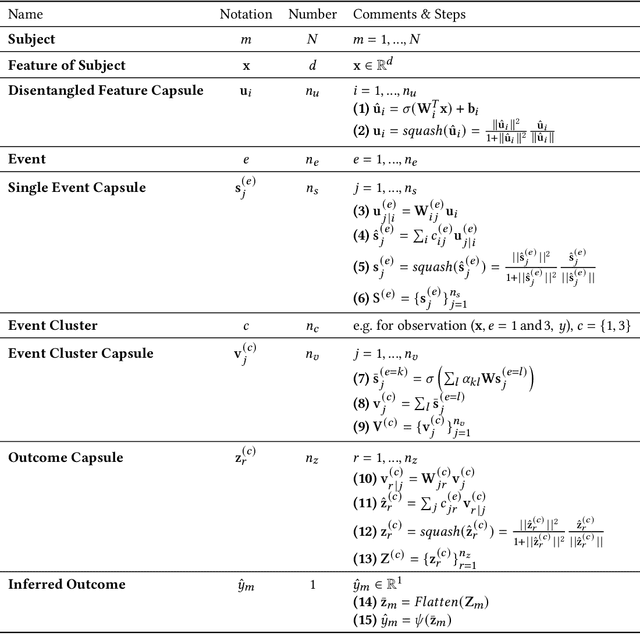
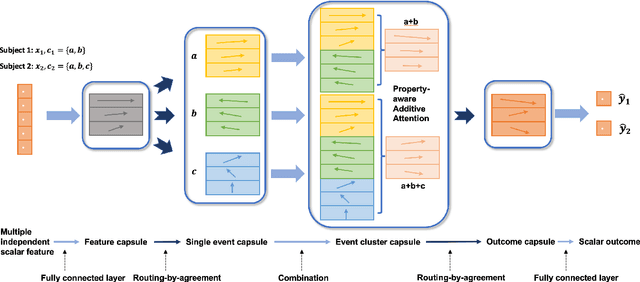
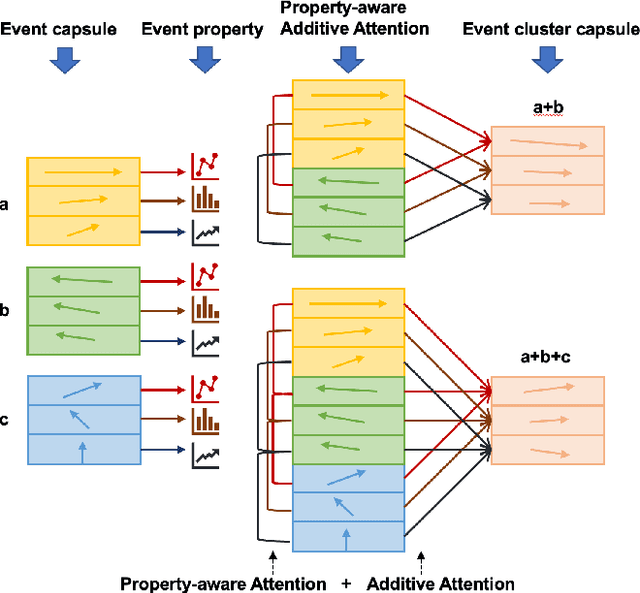
Marketing campaigns are a set of strategic activities that can promote a business's goal. The effect prediction for marketing campaigns in a real industrial scenario is very complex and challenging due to the fact that prior knowledge is often learned from observation data, without any intervention for the marketing campaign. Furthermore, each subject is always under the interference of several marketing campaigns simultaneously. Therefore, we cannot easily parse and evaluate the effect of a single marketing campaign. To the best of our knowledge, there are currently no effective methodologies to solve such a problem, i.e., modeling an individual-level prediction task based on a hierarchical structure with multiple intertwined events. In this paper, we provide an in-depth analysis of the underlying parse tree-like structure involved in the effect prediction task and we further establish a Hierarchical Capsule Prediction Network (HapNet) for predicting the effects of marketing campaigns. Extensive results based on both the synthetic data and real data demonstrate the superiority of our model over the state-of-the-art methods and show remarkable practicability in real industrial applications.