 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOcclusion-Adaptive Deep Network for Robust Facial Expression Recognition
Paper and Code
May 12, 2020

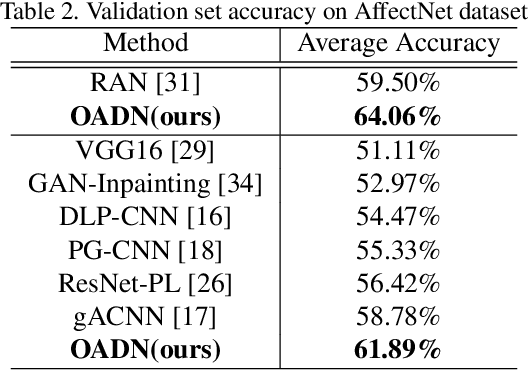
Recognizing the expressions of partially occluded faces is a challenging computer vision problem. Previous expression recognition methods, either overlooked this issue or resolved it using extreme assumptions. Motivated by the fact that the human visual system is adept at ignoring the occlusion and focus on non-occluded facial areas, we propose a landmark-guided attention branch to find and discard corrupted features from occluded regions so that they are not used for recognition. An attention map is first generated to indicate if a specific facial part is occluded and guide our model to attend to non-occluded regions. To further improve robustness, we propose a facial region branch to partition the feature maps into non-overlapping facial blocks and task each block to predict the expression independently. This results in more diverse and discriminative features, enabling the expression recognition system to recover even though the face is partially occluded. Depending on the synergistic effects of the two branches, our occlusion-adaptive deep network significantly outperforms state-of-the-art methods on two challenging in-the-wild benchmark datasets and three real-world occluded expression datasets.