 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient3D: A Unified Framework for Adaptive and Debiased Token Reduction in 3D MLLMs
Apr 03, 2026Recent advances in Multimodal Large Language Models (MLLMs) have expanded reasoning capabilities into 3D domains, enabling fine-grained spatial understanding. However, the substantial size of 3D MLLMs and the high dimensionality of input features introduce considerable inference overhead, which limits practical deployment on resource constrained platforms. To overcome this limitation, this paper presents Efficient3D, a unified framework for visual token pruning that accelerates 3D MLLMs while maintaining competitive accuracy. The proposed framework introduces a Debiased Visual Token Importance Estimator (DVTIE) module, which considers the influence of shallow initial layers during attention aggregation, thereby producing more reliable importance predictions for visual tokens. In addition, an Adaptive Token Rebalancing (ATR) strategy is developed to dynamically adjust pruning strength based on scene complexity, preserving semantic completeness and maintaining balanced attention across layers. Together, they enable context-aware token reduction that maintains essential semantics with lower computation. Comprehensive experiments conducted on five representative 3D vision and language benchmarks, including ScanRefer, Multi3DRefer, Scan2Cap, ScanQA, and SQA3D, demonstrate that Efficient3D achieves superior performance compared with unpruned baselines, with a +2.57% CIDEr improvement on the Scan2Cap dataset. Therefore, Efficient3D provides a scalable and effective solution for efficient inference in 3D MLLMs. The code is released at: https://github.com/sol924/Efficient3D
Action-Based ADHD Diagnosis in Video
Sep 03, 2024


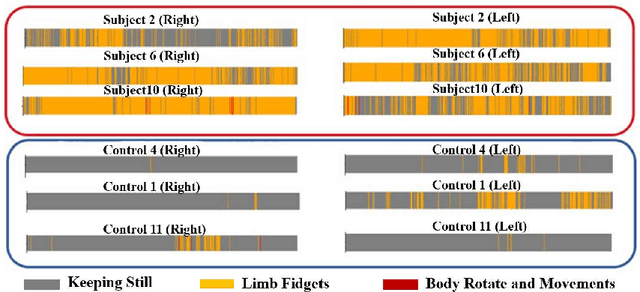
Attention Deficit Hyperactivity Disorder (ADHD) causes significant impairment in various domains. Early diagnosis of ADHD and treatment could significantly improve the quality of life and functioning. Recently, machine learning methods have improved the accuracy and efficiency of the ADHD diagnosis process. However, the cost of the equipment and trained staff required by the existing methods are generally huge. Therefore, we introduce the video-based frame-level action recognition network to ADHD diagnosis for the first time. We also record a real multi-modal ADHD dataset and extract three action classes from the video modality for ADHD diagnosis. The whole process data have been reported to CNTW-NHS Foundation Trust, which would be reviewed by medical consultants/professionals and will be made public in due course.
Unlocking the Potential: Benchmarking Large Language Models in Water Engineering and Research
Jul 22, 2024


Recent advancements in Large Language Models (LLMs) have sparked interest in their potential applications across various fields. This paper embarked on a pivotal inquiry: Can existing LLMs effectively serve as "water expert models" for water engineering and research tasks? This study was the first to evaluate LLMs' contributions across various water engineering and research tasks by establishing a domain-specific benchmark suite, namely, WaterER. Herein, we prepared 983 tasks related to water engineering and research, categorized into "wastewater treatment", "environmental restoration", "drinking water treatment and distribution", "sanitation", "anaerobic digestion" and "contaminants assessment". We evaluated the performance of seven LLMs (i.e., GPT-4, GPT-3.5, Gemini, GLM-4, ERNIE, QWEN and Llama3) on these tasks. We highlighted the strengths of GPT-4 in handling diverse and complex tasks of water engineering and water research, the specialized capabilities of Gemini in academic contexts, Llama3's strongest capacity to answer Chinese water engineering questions and the competitive performance of Chinese-oriented models like GLM-4, ERNIE and QWEN in some water engineering tasks. More specifically, current LLMs excelled particularly in generating precise research gaps for papers on "contaminants and related water quality monitoring and assessment". Additionally, they were more adept at creating appropriate titles for research papers on "treatment processes for wastewaters", "environmental restoration", and "drinking water treatment". Overall, this study pioneered evaluating LLMs in water engineering and research by introducing the WaterER benchmark to assess the trustworthiness of their predictions. This standardized evaluation framework would also drive future advancements in LLM technology by using targeting datasets, propelling these models towards becoming true "water expert".
Position and Orientation-Aware One-Shot Learning for Medical Action Recognition from Signal Data
Sep 27, 2023



In this work, we propose a position and orientation-aware one-shot learning framework for medical action recognition from signal data. The proposed framework comprises two stages and each stage includes signal-level image generation (SIG), cross-attention (CsA), dynamic time warping (DTW) modules and the information fusion between the proposed privacy-preserved position and orientation features. The proposed SIG method aims to transform the raw skeleton data into privacy-preserved features for training. The CsA module is developed to guide the network in reducing medical action recognition bias and more focusing on important human body parts for each specific action, aimed at addressing similar medical action related issues. Moreover, the DTW module is employed to minimize temporal mismatching between instances and further improve model performance. Furthermore, the proposed privacy-preserved orientation-level features are utilized to assist the position-level features in both of the two stages for enhancing medical action recognition performance. Extensive experimental results on the widely-used and well-known NTU RGB+D 60, NTU RGB+D 120, and PKU-MMD datasets all demonstrate the effectiveness of the proposed method, which outperforms the other state-of-the-art methods with general dataset partitioning by 2.7%, 6.2% and 4.1%, respectively.
EVD Surgical Guidance with Retro-Reflective Tool Tracking and Spatial Reconstruction using Head-Mounted Augmented Reality Device
Jul 03, 2023



Augmented Reality (AR) has been used to facilitate surgical guidance during External Ventricular Drain (EVD) surgery, reducing the risks of misplacement in manual operations. During this procedure, the key challenge is accurately estimating the spatial relationship between pre-operative images and actual patient anatomy in AR environment. This research proposes a novel framework utilizing Time of Flight (ToF) depth sensors integrated in commercially available AR Head Mounted Devices (HMD) for precise EVD surgical guidance. As previous studies have proven depth errors for ToF sensors, we first assessed their properties on AR-HMDs. Subsequently, a depth error model and patient-specific parameter identification method are introduced for accurate surface information. A tracking pipeline combining retro-reflective markers and point clouds is then proposed for accurate head tracking. The head surface is reconstructed using depth data for spatial registration, avoiding fixing tracking targets rigidly on the patient's skull. Firstly, $7.580\pm 1.488 mm$ depth value error was revealed on human skin, indicating the significance of depth correction. Our results showed that the error was reduced by over $85\%$ using proposed depth correction method on head phantoms in different materials. Meanwhile, the head surface reconstructed with corrected depth data achieved sub-millimetre accuracy. An experiment on sheep head revealed $0.79 mm$ reconstruction error. Furthermore, a user study was conducted for the performance in simulated EVD surgery, where five surgeons performed nine k-wire injections on a head phantom with virtual guidance. Results of this study revealed $2.09 \pm 0.16 mm$ translational accuracy and $2.97\pm 0.91$ degree orientational accuracy.
Multimodal Short Video Rumor Detection System Based on Contrastive Learning
Apr 18, 2023



With short video platforms becoming one of the important channels for news sharing, major short video platforms in China have gradually become new breeding grounds for fake news. However, it is not easy to distinguish short video rumors due to the great amount of information and features contained in short videos, as well as the serious homogenization and similarity of features among videos. In order to mitigate the spread of short video rumors, our group decides to detect short video rumors by constructing multimodal feature fusion and introducing external knowledge after considering the advantages and disadvantages of each algorithm. The ideas of detection are as follows: (1) dataset creation: to build a short video dataset with multiple features; (2) multimodal rumor detection model: firstly, we use TSN (Temporal Segment Networks) video coding model to extract video features; then, we use OCR (Optical Character Recognition) and ASR (Automatic Character Recognition) to extract video features. Recognition) and ASR (Automatic Speech Recognition) fusion to extract text, and then use the BERT model to fuse text features with video features (3) Finally, use contrast learning to achieve distinction: first crawl external knowledge, then use the vector database to achieve the introduction of external knowledge and the final structure of the classification output. Our research process is always oriented to practical needs, and the related knowledge results will play an important role in many practical scenarios such as short video rumor identification and social opinion control.