 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLight-R1: Curriculum SFT, DPO and RL for Long COT from Scratch and Beyond
Mar 13, 2025This paper presents our work on the Light-R1 series, with models, data, and code all released. We first focus on training long COT models from scratch, specifically starting from models initially lacking long COT capabilities. Using a curriculum training recipe consisting of two-stage SFT and semi-on-policy DPO, we train our model Light-R1-32B from Qwen2.5-32B-Instruct, resulting in superior math performance compared to DeepSeek-R1-Distill-Qwen-32B. Despite being trained exclusively on math data, Light-R1-32B shows strong generalization across other domains. In the subsequent phase of this work, we highlight the significant benefit of the 3k dataset constructed for the second SFT stage on enhancing other models. By fine-tuning DeepSeek-R1-Distilled models using this dataset, we obtain new SOTA models in 7B and 14B, while the 32B model, Light-R1-32B-DS performed comparably to QwQ-32B and DeepSeek-R1. Furthermore, we extend our work by applying reinforcement learning, specifically GRPO, on long-COT models to further improve reasoning performance. We successfully train our final Light-R1-14B-DS with RL, achieving SOTA performance among 14B parameter models in math. With AIME24 & 25 scores of 74.0 and 60.2 respectively, Light-R1-14B-DS surpasses even many 32B models and DeepSeek-R1-Distill-Llama-70B. Its RL training also exhibits well expected behavior, showing simultaneous increase in response length and reward score. The Light-R1 series of work validates training long-COT models from scratch, showcases the art in SFT data and releases SOTA models from RL.
Unlocking the Potential: Benchmarking Large Language Models in Water Engineering and Research
Jul 22, 2024

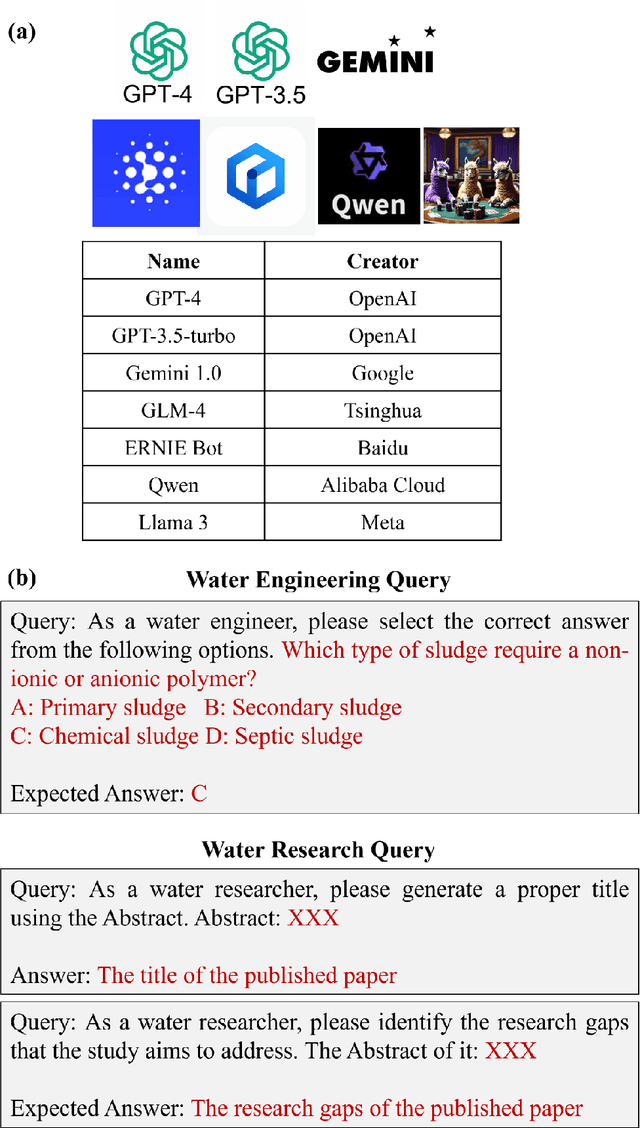

Recent advancements in Large Language Models (LLMs) have sparked interest in their potential applications across various fields. This paper embarked on a pivotal inquiry: Can existing LLMs effectively serve as "water expert models" for water engineering and research tasks? This study was the first to evaluate LLMs' contributions across various water engineering and research tasks by establishing a domain-specific benchmark suite, namely, WaterER. Herein, we prepared 983 tasks related to water engineering and research, categorized into "wastewater treatment", "environmental restoration", "drinking water treatment and distribution", "sanitation", "anaerobic digestion" and "contaminants assessment". We evaluated the performance of seven LLMs (i.e., GPT-4, GPT-3.5, Gemini, GLM-4, ERNIE, QWEN and Llama3) on these tasks. We highlighted the strengths of GPT-4 in handling diverse and complex tasks of water engineering and water research, the specialized capabilities of Gemini in academic contexts, Llama3's strongest capacity to answer Chinese water engineering questions and the competitive performance of Chinese-oriented models like GLM-4, ERNIE and QWEN in some water engineering tasks. More specifically, current LLMs excelled particularly in generating precise research gaps for papers on "contaminants and related water quality monitoring and assessment". Additionally, they were more adept at creating appropriate titles for research papers on "treatment processes for wastewaters", "environmental restoration", and "drinking water treatment". Overall, this study pioneered evaluating LLMs in water engineering and research by introducing the WaterER benchmark to assess the trustworthiness of their predictions. This standardized evaluation framework would also drive future advancements in LLM technology by using targeting datasets, propelling these models towards becoming true "water expert".