 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVEPO: Variable Entropy Policy Optimization for Low-Resource Language Foundation Models
Mar 19, 2026Large language models frequently exhibit suboptimal performance on low resource languages, primarily due to inefficient subword segmentation and systemic training data imbalances. In this paper, we propose Variable Entropy Policy Optimization (VEPO), which leverages Reinforcement Learning with Verifiable Rewards to incorporate deterministic structural constraints into the policy alignment process. This framework ensures prescribed sequence length, robust format consistency, and rigorous linguistic well formedness, all enforced during training. Central to our approach is a variable entropy mechanism that enables the model to dynamically calibrate the equilibrium between literal fidelity and semantic naturalness by modulating the exploration exploitation manifold. By integrating entropy tempered advantage estimation with asymmetric clipping, VEPO sustains robust exploration while mitigating policy collapse. Empirical evaluations across 90 FLORES-200, COMET-22, chrF directions demonstrate that VEPO yields substantial improvements in both tokenization efficiency and translation quality, bridging the performance gap for underrepresented languages.
Quantifying Memory Utilization with Effective State-Size
Apr 28, 2025The need to develop a general framework for architecture analysis is becoming increasingly important, given the expanding design space of sequence models. To this end, we draw insights from classical signal processing and control theory, to develop a quantitative measure of \textit{memory utilization}: the internal mechanisms through which a model stores past information to produce future outputs. This metric, which we call \textbf{\textit{effective state-size}} (ESS), is tailored to the fundamental class of systems with \textit{input-invariant} and \textit{input-varying linear operators}, encompassing a variety of computational units such as variants of attention, convolutions, and recurrences. Unlike prior work on memory utilization, which either relies on raw operator visualizations (e.g. attention maps), or simply the total \textit{memory capacity} (i.e. cache size) of a model, our metrics provide highly interpretable and actionable measurements. In particular, we show how ESS can be leveraged to improve initialization strategies, inform novel regularizers and advance the performance-efficiency frontier through model distillation. Furthermore, we demonstrate that the effect of context delimiters (such as end-of-speech tokens) on ESS highlights cross-architectural differences in how large language models utilize their available memory to recall information. Overall, we find that ESS provides valuable insights into the dynamics that dictate memory utilization, enabling the design of more efficient and effective sequence models.
Light-R1: Curriculum SFT, DPO and RL for Long COT from Scratch and Beyond
Mar 13, 2025This paper presents our work on the Light-R1 series, with models, data, and code all released. We first focus on training long COT models from scratch, specifically starting from models initially lacking long COT capabilities. Using a curriculum training recipe consisting of two-stage SFT and semi-on-policy DPO, we train our model Light-R1-32B from Qwen2.5-32B-Instruct, resulting in superior math performance compared to DeepSeek-R1-Distill-Qwen-32B. Despite being trained exclusively on math data, Light-R1-32B shows strong generalization across other domains. In the subsequent phase of this work, we highlight the significant benefit of the 3k dataset constructed for the second SFT stage on enhancing other models. By fine-tuning DeepSeek-R1-Distilled models using this dataset, we obtain new SOTA models in 7B and 14B, while the 32B model, Light-R1-32B-DS performed comparably to QwQ-32B and DeepSeek-R1. Furthermore, we extend our work by applying reinforcement learning, specifically GRPO, on long-COT models to further improve reasoning performance. We successfully train our final Light-R1-14B-DS with RL, achieving SOTA performance among 14B parameter models in math. With AIME24 & 25 scores of 74.0 and 60.2 respectively, Light-R1-14B-DS surpasses even many 32B models and DeepSeek-R1-Distill-Llama-70B. Its RL training also exhibits well expected behavior, showing simultaneous increase in response length and reward score. The Light-R1 series of work validates training long-COT models from scratch, showcases the art in SFT data and releases SOTA models from RL.
LEDD: Large Language Model-Empowered Data Discovery in Data Lakes
Feb 21, 2025Data discovery in data lakes with ever increasing datasets has long been recognized as a big challenge in the realm of data management, especially for semantic search of and hierarchical global catalog generation of tables. While large language models (LLMs) facilitate the processing of data semantics, challenges remain in architecting an end-to-end system that comprehensively exploits LLMs for the two semantics-related tasks. In this demo, we propose LEDD, an end-to-end system with an extensible architecture that leverages LLMs to provide hierarchical global catalogs with semantic meanings and semantic table search for data lakes. Specifically, LEDD can return semantically related tables based on natural-language specification. These features make LEDD an ideal foundation for downstream tasks such as model training and schema linking for text-to-SQL tasks. LEDD also provides a simple Python interface to facilitate the extension and the replacement of data discovery algorithms.
State-Free Inference of State-Space Models: The Transfer Function Approach
May 10, 2024We approach designing a state-space model for deep learning applications through its dual representation, the transfer function, and uncover a highly efficient sequence parallel inference algorithm that is state-free: unlike other proposed algorithms, state-free inference does not incur any significant memory or computational cost with an increase in state size. We achieve this using properties of the proposed frequency domain transfer function parametrization, which enables direct computation of its corresponding convolutional kernel's spectrum via a single Fast Fourier Transform. Our experimental results across multiple sequence lengths and state sizes illustrates, on average, a 35% training speed improvement over S4 layers -- parametrized in time-domain -- on the Long Range Arena benchmark, while delivering state-of-the-art downstream performances over other attention-free approaches. Moreover, we report improved perplexity in language modeling over a long convolutional Hyena baseline, by simply introducing our transfer function parametrization. Our code is available at https://github.com/ruke1ire/RTF.
Multi-Stage Contrastive Regression for Action Quality Assessment
Jan 05, 2024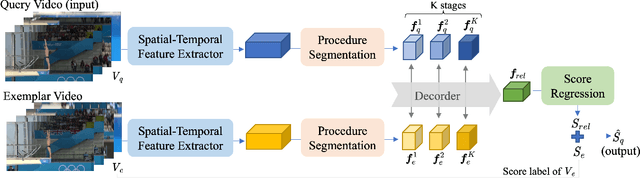
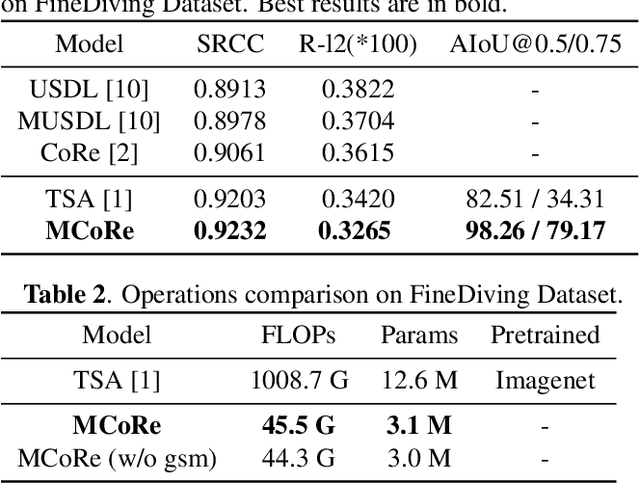

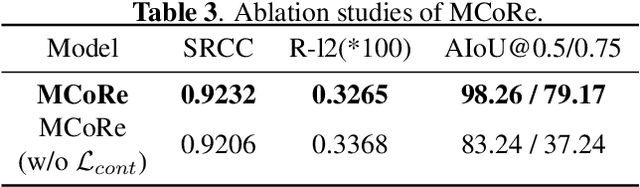
In recent years, there has been growing interest in the video-based action quality assessment (AQA). Most existing methods typically solve AQA problem by considering the entire video yet overlooking the inherent stage-level characteristics of actions. To address this issue, we design a novel Multi-stage Contrastive Regression (MCoRe) framework for the AQA task. This approach allows us to efficiently extract spatial-temporal information, while simultaneously reducing computational costs by segmenting the input video into multiple stages or procedures. Inspired by the graph contrastive learning, we propose a new stage-wise contrastive learning loss function to enhance performance. As a result, MCoRe demonstrates the state-of-the-art result so far on the widely-adopted fine-grained AQA dataset.
Enhancement of Healthcare Data Performance Metrics using Neural Network Machine Learning Algorithms
Jan 16, 2022Patients are often encouraged to make use of wearable devices for remote collection and monitoring of health data. This adoption of wearables results in a significant increase in the volume of data collected and transmitted. The battery life of the devices is then quickly diminished due to the high processing requirements of the devices. Given the importance attached to medical data, it is imperative that all transmitted data adhere to strict integrity and availability requirements. Reducing the volume of healthcare data for network transmission may improve sensor battery life without compromising accuracy. There is a trade-off between efficiency and accuracy which can be controlled by adjusting the sampling and transmission rates. This paper demonstrates that machine learning can be used to analyse complex health data metrics such as the accuracy and efficiency of data transmission to overcome the trade-off problem. The study uses time series nonlinear autoregressive neural network algorithms to enhance both data metrics by taking fewer samples to transmit. The algorithms were tested with a standard heart rate dataset to compare their accuracy and efficiency. The result showed that the Levenbery-Marquardt algorithm was the best performer with an efficiency of 3.33 and accuracy of 79.17%, which is similar to other algorithms accuracy but demonstrates improved efficiency. This proves that machine learning can improve without sacrificing a metric over the other compared to the existing methods with high efficiency.