 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnlearning Imperative: Securing Trustworthy and Responsible LLMs through Engineered Forgetting
Nov 13, 2025The growing use of large language models in sensitive domains has exposed a critical weakness: the inability to ensure that private information can be permanently forgotten. Yet these systems still lack reliable mechanisms to guarantee that sensitive information can be permanently removed once it has been used. Retraining from the beginning is prohibitively costly, and existing unlearning methods remain fragmented, difficult to verify, and often vulnerable to recovery. This paper surveys recent research on machine unlearning for LLMs and considers how far current approaches can address these challenges. We review methods for evaluating whether forgetting has occurred, the resilience of unlearned models against adversarial attacks, and mechanisms that can support user trust when model complexity or proprietary limits restrict transparency. Technical solutions such as differential privacy, homomorphic encryption, federated learning, and ephemeral memory are examined alongside institutional safeguards including auditing practices and regulatory frameworks. The review finds steady progress, but robust and verifiable unlearning is still unresolved. Efficient techniques that avoid costly retraining, stronger defenses against adversarial recovery, and governance structures that reinforce accountability are needed if LLMs are to be deployed safely in sensitive applications. By integrating technical and organizational perspectives, this study outlines a pathway toward AI systems that can be required to forget, while maintaining both privacy and public trust.
Enhancement of Healthcare Data Transmission using the Levenberg-Marquardt Algorithm
Jun 09, 2022
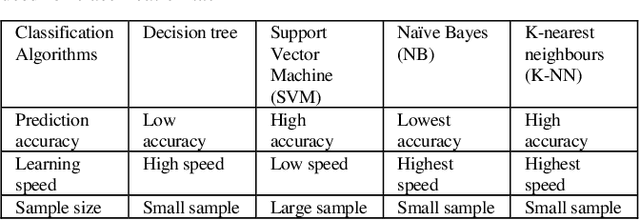
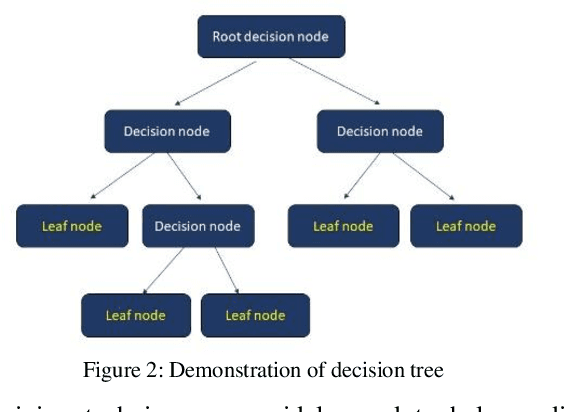

In the healthcare system, patients are required to use wearable devices for the remote data collection and real-time monitoring of health data and the status of health conditions. This adoption of wearables results in a significant increase in the volume of data that is collected and transmitted. As the devices are run by small battery power, they can be quickly diminished due to the high processing requirements of the device for data collection and transmission. Given the importance attached to medical data, it is imperative that all transmitted data adhere to strict integrity and availability requirements. Reducing the volume of healthcare data and the frequency of transmission will improve the device battery life via using inference algorithm. There is an issue of improving transmission metrics with accuracy and efficiency, which trade-off each other such as increasing accuracy reduces the efficiency. This paper demonstrates that machine learning can be used to analyze complex health data metrics such as the accuracy and efficiency of data transmission to overcome the trade-off problem using the Levenberg-Marquardt algorithm to enhance both metrics by taking fewer samples to transmit whilst maintaining the accuracy. The algorithm is tested with a standard heart rate dataset to compare the metrics. The result shows that the LMA has best performed with an efficiency of 3.33 times for reduced sample data size and accuracy of 79.17%, which has the similar accuracies in 7 different sampling cases adopted for testing but demonstrates improved efficiency. These proposed methods significantly improved both metrics using machine learning without sacrificing a metric over the other compared to the existing methods with high efficiency.
Enhancement of Healthcare Data Performance Metrics using Neural Network Machine Learning Algorithms
Jan 16, 2022Patients are often encouraged to make use of wearable devices for remote collection and monitoring of health data. This adoption of wearables results in a significant increase in the volume of data collected and transmitted. The battery life of the devices is then quickly diminished due to the high processing requirements of the devices. Given the importance attached to medical data, it is imperative that all transmitted data adhere to strict integrity and availability requirements. Reducing the volume of healthcare data for network transmission may improve sensor battery life without compromising accuracy. There is a trade-off between efficiency and accuracy which can be controlled by adjusting the sampling and transmission rates. This paper demonstrates that machine learning can be used to analyse complex health data metrics such as the accuracy and efficiency of data transmission to overcome the trade-off problem. The study uses time series nonlinear autoregressive neural network algorithms to enhance both data metrics by taking fewer samples to transmit. The algorithms were tested with a standard heart rate dataset to compare their accuracy and efficiency. The result showed that the Levenbery-Marquardt algorithm was the best performer with an efficiency of 3.33 and accuracy of 79.17%, which is similar to other algorithms accuracy but demonstrates improved efficiency. This proves that machine learning can improve without sacrificing a metric over the other compared to the existing methods with high efficiency.