 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Pathomic Learning Defines Prognostic Subtypes and Molecular Drivers in Colorectal Cancer
Nov 19, 2025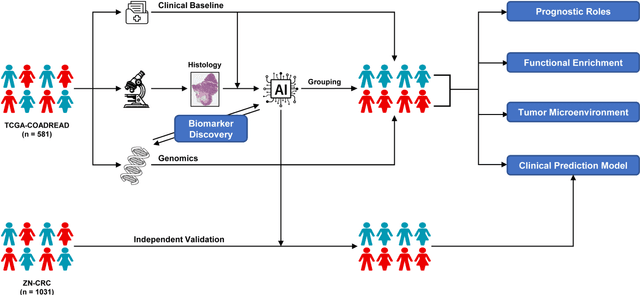
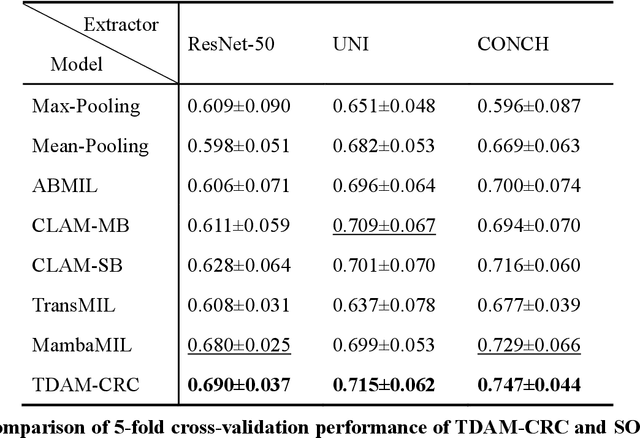
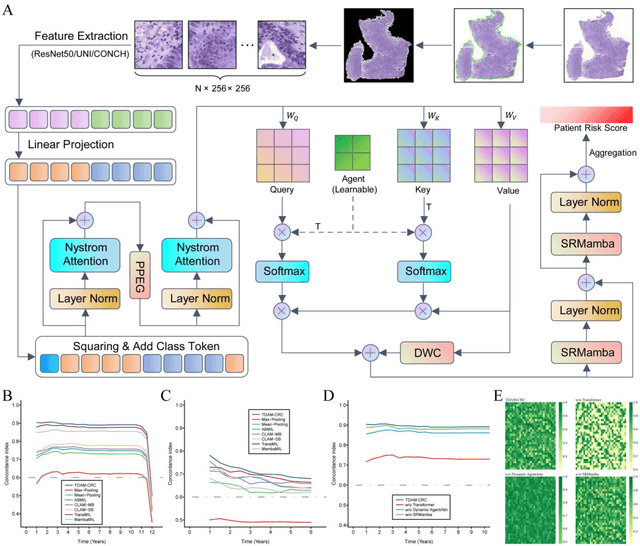
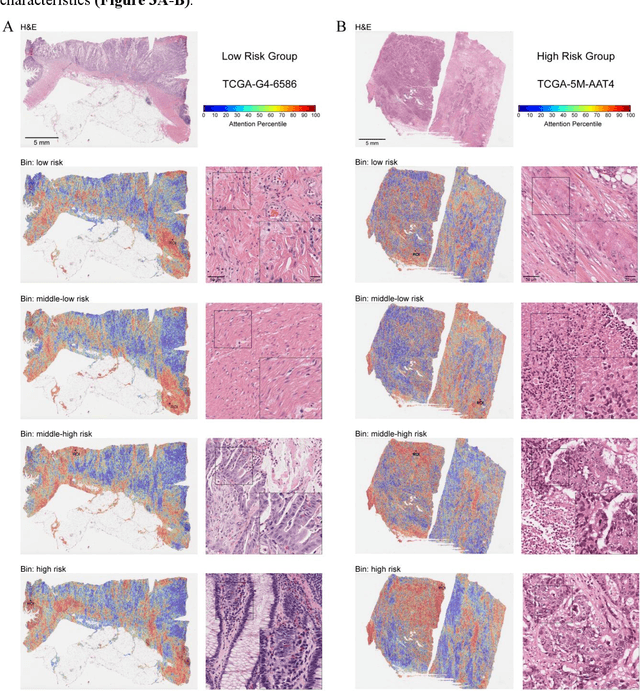
Precise prognostic stratification of colorectal cancer (CRC) remains a major clinical challenge due to its high heterogeneity. The conventional TNM staging system is inadequate for personalized medicine. We aimed to develop and validate a novel multiple instance learning model TDAM-CRC using histopathological whole-slide images for accurate prognostic prediction and to uncover its underlying molecular mechanisms. We trained the model on the TCGA discovery cohort (n=581), validated it in an independent external cohort (n=1031), and further we integrated multi-omics data to improve model interpretability and identify novel prognostic biomarkers. The results demonstrated that the TDAM-CRC achieved robust risk stratification in both cohorts. Its predictive performance significantly outperformed the conventional clinical staging system and multiple state-of-the-art models. The TDAM-CRC risk score was confirmed as an independent prognostic factor in multivariable analysis. Multi-omics analysis revealed that the high-risk subtype is closely associated with metabolic reprogramming and an immunosuppressive tumor microenvironment. Through interaction network analysis, we identified and validated Mitochondrial Ribosomal Protein L37 (MRPL37) as a key hub gene linking deep pathomic features to clinical prognosis. We found that high expression of MRPL37, driven by promoter hypomethylation, serves as an independent biomarker of favorable prognosis. Finally, we constructed a nomogram incorporating the TDAM-CRC risk score and clinical factors to provide a precise and interpretable clinical decision-making tool for CRC patients. Our AI-driven pathological model TDAM-CRC provides a robust tool for improved CRC risk stratification, reveals new molecular targets, and facilitates personalized clinical decision-making.
Unmasking the Shadows: Pinpoint the Implementations of Anti-Dynamic Analysis Techniques in Malware Using LLM
Nov 08, 2024



Sandboxes and other dynamic analysis processes are prevalent in malware detection systems nowadays to enhance the capability of detecting 0-day malware. Therefore, techniques of anti-dynamic analysis (TADA) are prevalent in modern malware samples, and sandboxes can suffer from false negatives and analysis failures when analyzing the samples with TADAs. In such cases, human reverse engineers will get involved in conducting dynamic analysis manually (i.e., debugging, patching), which in turn also gets obstructed by TADAs. In this work, we propose a Large Language Model (LLM) based workflow that can pinpoint the location of the TADA implementation in the code, to help reverse engineers place breakpoints used in debugging. Our evaluation shows that we successfully identified the locations of 87.80% known TADA implementations adopted from public repositories. In addition, we successfully pinpoint the locations of TADAs in 4 well-known malware samples that are documented in online malware analysis blogs.
Hide Your Malicious Goal Into Benign Narratives: Jailbreak Large Language Models through Neural Carrier Articles
Aug 20, 2024



Jailbreak attacks on Language Model Models (LLMs) entail crafting prompts aimed at exploiting the models to generate malicious content. This paper proposes a new type of jailbreak attacks which shift the attention of the LLM by inserting a prohibited query into a carrier article. The proposed attack leverage the knowledge graph and a composer LLM to automatically generating a carrier article that is similar to the topic of the prohibited query but does not violate LLM's safeguards. By inserting the malicious query to the carrier article, the assembled attack payload can successfully jailbreak LLM. To evaluate the effectiveness of our method, we leverage 4 popular categories of ``harmful behaviors'' adopted by related researches to attack 6 popular LLMs. Our experiment results show that the proposed attacking method can successfully jailbreak all the target LLMs which high success rate, except for Claude-3.
RAUCG: Retrieval-Augmented Unsupervised Counter Narrative Generation for Hate Speech
Oct 09, 2023

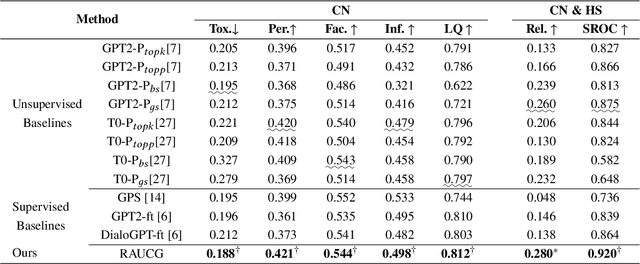
The Counter Narrative (CN) is a promising approach to combat online hate speech (HS) without infringing on freedom of speech. In recent years, there has been a growing interest in automatically generating CNs using natural language generation techniques. However, current automatic CN generation methods mainly rely on expert-authored datasets for training, which are time-consuming and labor-intensive to acquire. Furthermore, these methods cannot directly obtain and extend counter-knowledge from external statistics, facts, or examples. To address these limitations, we propose Retrieval-Augmented Unsupervised Counter Narrative Generation (RAUCG) to automatically expand external counter-knowledge and map it into CNs in an unsupervised paradigm. Specifically, we first introduce an SSF retrieval method to retrieve counter-knowledge from the multiple perspectives of stance consistency, semantic overlap rate, and fitness for HS. Then we design an energy-based decoding mechanism by quantizing knowledge injection, countering and fluency constraints into differentiable functions, to enable the model to build mappings from counter-knowledge to CNs without expert-authored CN data. Lastly, we comprehensively evaluate model performance in terms of language quality, toxicity, persuasiveness, relevance, and success rate of countering HS, etc. Experimental results show that RAUCG outperforms strong baselines on all metrics and exhibits stronger generalization capabilities, achieving significant improvements of +2.0% in relevance and +4.5% in success rate of countering metrics. Moreover, RAUCG enabled GPT2 to outperform T0 in all metrics, despite the latter being approximately eight times larger than the former. Warning: This paper may contain offensive or upsetting content!
Multimodal Short Video Rumor Detection System Based on Contrastive Learning
Apr 18, 2023



With short video platforms becoming one of the important channels for news sharing, major short video platforms in China have gradually become new breeding grounds for fake news. However, it is not easy to distinguish short video rumors due to the great amount of information and features contained in short videos, as well as the serious homogenization and similarity of features among videos. In order to mitigate the spread of short video rumors, our group decides to detect short video rumors by constructing multimodal feature fusion and introducing external knowledge after considering the advantages and disadvantages of each algorithm. The ideas of detection are as follows: (1) dataset creation: to build a short video dataset with multiple features; (2) multimodal rumor detection model: firstly, we use TSN (Temporal Segment Networks) video coding model to extract video features; then, we use OCR (Optical Character Recognition) and ASR (Automatic Character Recognition) to extract video features. Recognition) and ASR (Automatic Speech Recognition) fusion to extract text, and then use the BERT model to fuse text features with video features (3) Finally, use contrast learning to achieve distinction: first crawl external knowledge, then use the vector database to achieve the introduction of external knowledge and the final structure of the classification output. Our research process is always oriented to practical needs, and the related knowledge results will play an important role in many practical scenarios such as short video rumor identification and social opinion control.
ClueGraphSum: Let Key Clues Guide the Cross-Lingual Abstractive Summarization
Mar 09, 2022
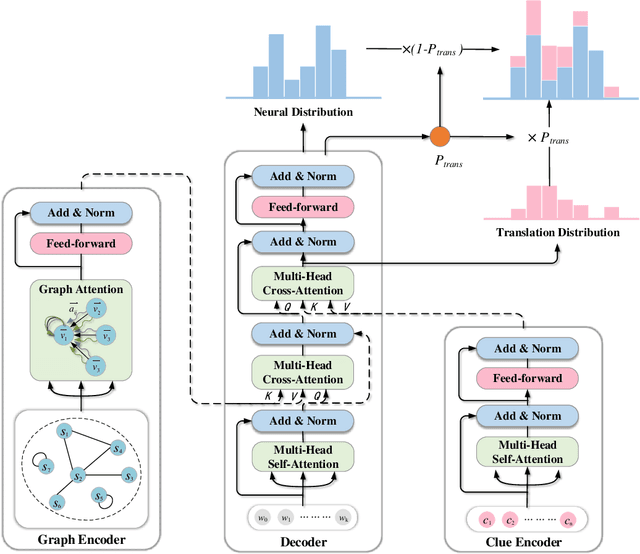
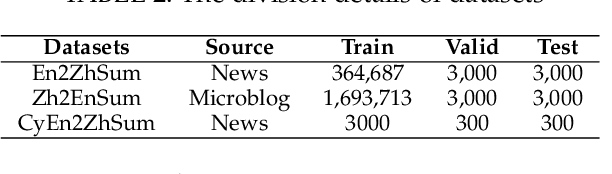
Cross-Lingual Summarization (CLS) is the task to generate a summary in one language for an article in a different language. Previous studies on CLS mainly take pipeline methods or train the end-to-end model using the translated parallel data. However, the quality of generated cross-lingual summaries needs more further efforts to improve, and the model performance has never been evaluated on the hand-written CLS dataset. Therefore, we first propose a clue-guided cross-lingual abstractive summarization method to improve the quality of cross-lingual summaries, and then construct a novel hand-written CLS dataset for evaluation. Specifically, we extract keywords, named entities, etc. of the input article as key clues for summarization and then design a clue-guided algorithm to transform an article into a graph with less noisy sentences. One Graph encoder is built to learn sentence semantics and article structures and one Clue encoder is built to encode and translate key clues, ensuring the information of important parts are reserved in the generated summary. These two encoders are connected by one decoder to directly learn cross-lingual semantics. Experimental results show that our method has stronger robustness for longer inputs and substantially improves the performance over the strong baseline, achieving an improvement of 8.55 ROUGE-1 (English-to-Chinese summarization) and 2.13 MoverScore (Chinese-to-English summarization) scores over the existing SOTA.
Detecting Offensive Language on Social Networks: An End-to-end Detection Method based on Graph Attention Networks
Mar 04, 2022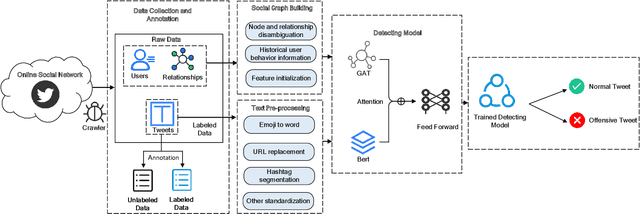
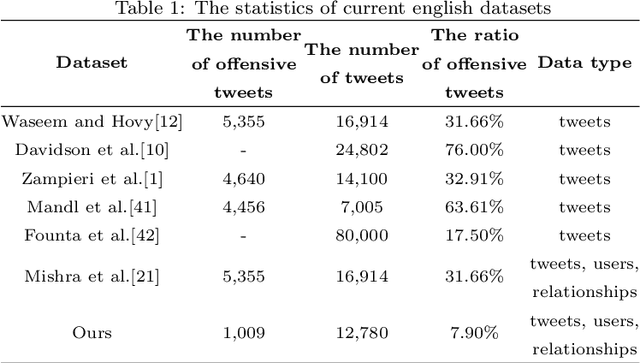

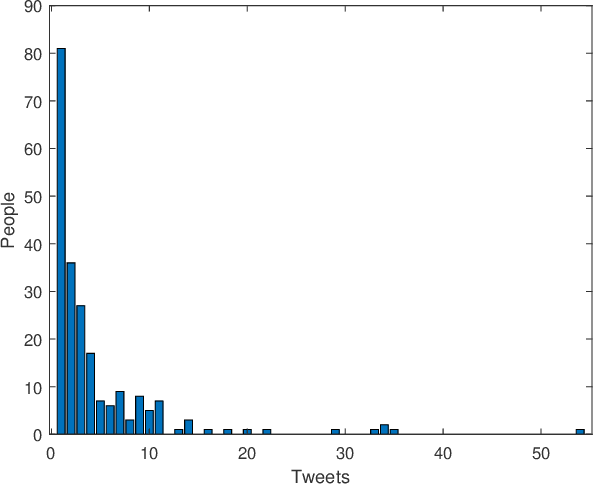
The pervasiveness of offensive language on the social network has caused adverse effects on society, such as abusive behavior online. It is urgent to detect offensive language and curb its spread. Existing research shows that methods with community structure features effectively improve the performance of offensive language detection. However, the existing models deal with community structure independently, which seriously affects the effectiveness of detection models. In this paper, we propose an end-to-end method based on community structure and text features for offensive language detection (CT-OLD). Specifically, the community structure features are directly captured by the graph attention network layer, and the text embeddings are taken from the last hidden layer of BERT. Attention mechanisms and position encoding are used to fuse these features. Meanwhile, we add user opinion to the community structure for representing user features. The user opinion is represented by user historical behavior information, which outperforms that represented by text information. Besides the above point, the distribution of users and tweets is unbalanced in the popular datasets, which limits the generalization ability of the model. To address this issue, we construct and release a dataset with reasonable user distribution. Our method outperforms baselines with the F1 score of 89.94%. The results show that the end-to-end model effectively learns the potential information of community structure and text, and user historical behavior information is more suitable for user opinion representation.
A Multitask Deep Learning Approach for User Depression Detection on Sina Weibo
Aug 26, 2020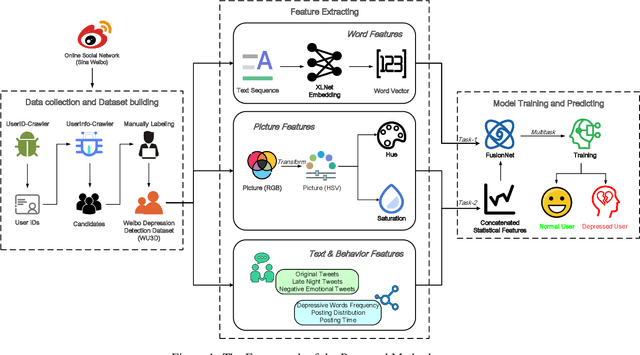
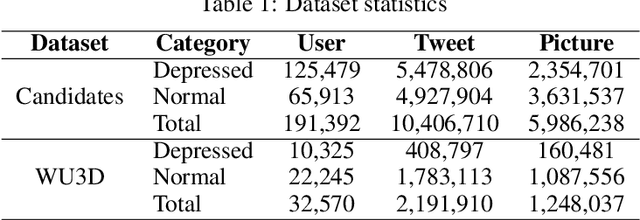
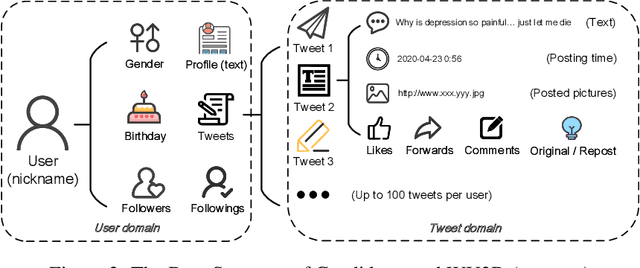
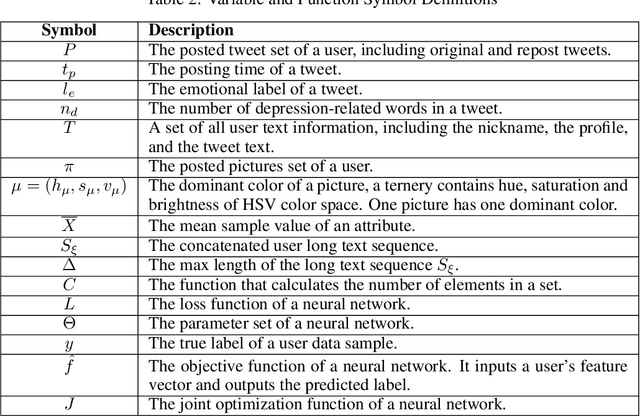
In recent years, due to the mental burden of depression, the number of people who endanger their lives has been increasing rapidly. The online social network (OSN) provides researchers with another perspective for detecting individuals suffering from depression. However, existing studies of depression detection based on machine learning still leave relatively low classification performance, suggesting that there is significant improvement potential for improvement in their feature engineering. In this paper, we manually build a large dataset on Sina Weibo (a leading OSN with the largest number of active users in the Chinese community), namely Weibo User Depression Detection Dataset (WU3D). It includes more than 20,000 normal users and more than 10,000 depressed users, both of which are manually labeled and rechecked by professionals. By analyzing the user's text, social behavior, and posted pictures, ten statistical features are concluded and proposed. In the meantime, text-based word features are extracted using the popular pretrained model XLNet. Moreover, a novel deep neural network classification model, i.e. FusionNet (FN), is proposed and simultaneously trained with the above-extracted features, which are seen as multiple classification tasks. The experimental results show that FusionNet achieves the highest F1-Score of 0.9772 on the test dataset. Compared to existing studies, our proposed method has better classification performance and robustness for unbalanced training samples. Our work also provides a new way to detect depression on other OSN platforms.
An End-to-End Attack on Text-based CAPTCHAs Based on Cycle-Consistent Generative Adversarial Network
Aug 26, 2020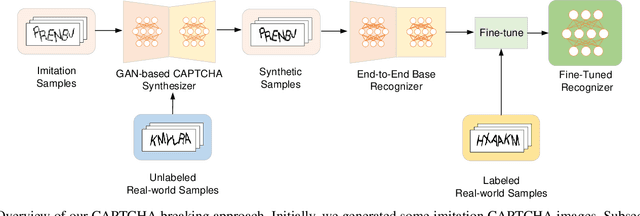
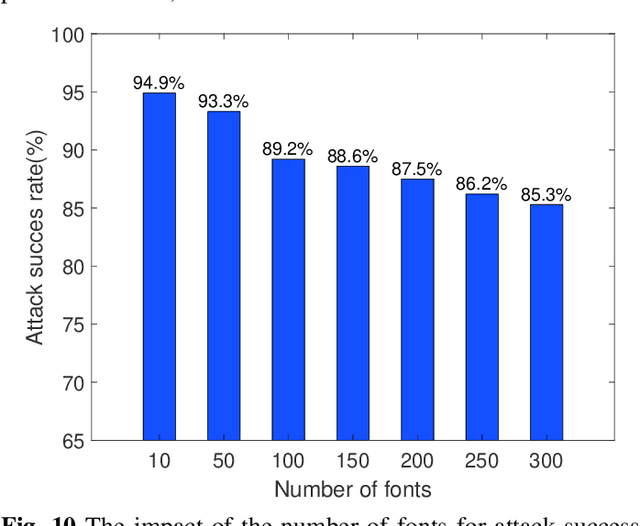
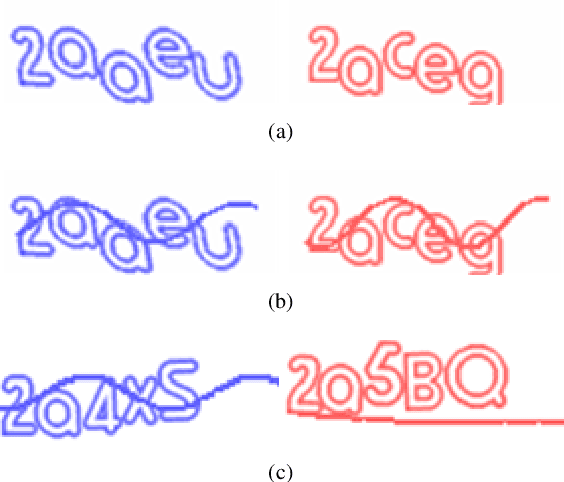
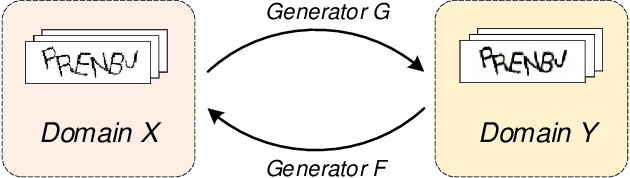
As a widely deployed security scheme, text-based CAPTCHAs have become more and more difficult to resist machine learning-based attacks. So far, many researchers have conducted attacking research on text-based CAPTCHAs deployed by different companies (such as Microsoft, Amazon, and Apple) and achieved certain results.However, most of these attacks have some shortcomings, such as poor portability of attack methods, requiring a series of data preprocessing steps, and relying on large amounts of labeled CAPTCHAs. In this paper, we propose an efficient and simple end-to-end attack method based on cycle-consistent generative adversarial networks. Compared with previous studies, our method greatly reduces the cost of data labeling. In addition, this method has high portability. It can attack common text-based CAPTCHA schemes only by modifying a few configuration parameters, which makes the attack easier. Firstly, we train CAPTCHA synthesizers based on the cycle-GAN to generate some fake samples. Basic recognizers based on the convolutional recurrent neural network are trained with the fake data. Subsequently, an active transfer learning method is employed to optimize the basic recognizer utilizing tiny amounts of labeled real-world CAPTCHA samples. Our approach efficiently cracked the CAPTCHA schemes deployed by 10 popular websites, indicating that our attack is likely very general. Additionally, we analyzed the current most popular anti-recognition mechanisms. The results show that the combination of more anti-recognition mechanisms can improve the security of CAPTCHA, but the improvement is limited. Conversely, generating more complex CAPTCHAs may cost more resources and reduce the availability of CAPTCHAs.