 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting Offensive Language on Social Networks: An End-to-end Detection Method based on Graph Attention Networks
Mar 04, 2022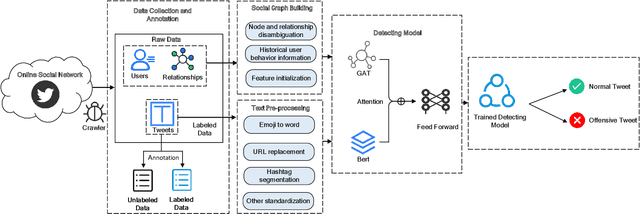
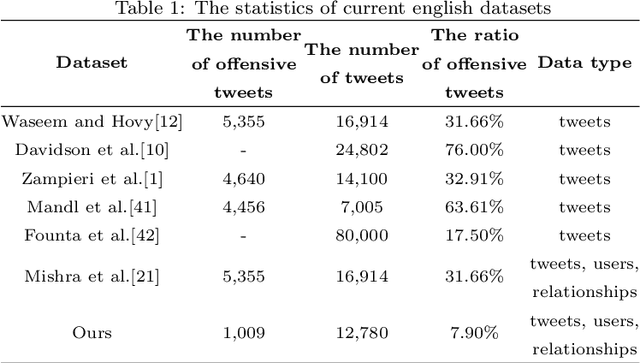

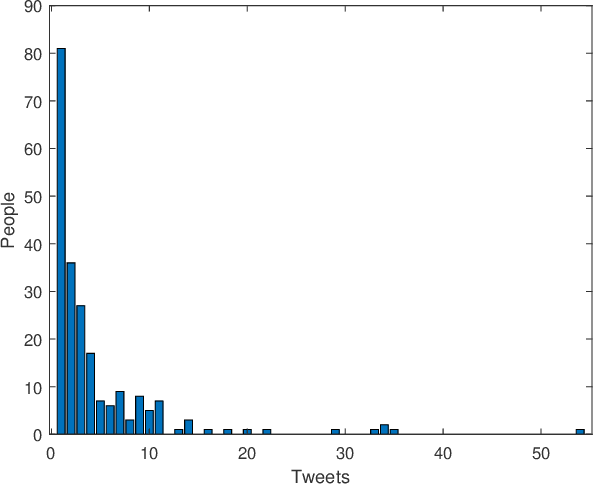
The pervasiveness of offensive language on the social network has caused adverse effects on society, such as abusive behavior online. It is urgent to detect offensive language and curb its spread. Existing research shows that methods with community structure features effectively improve the performance of offensive language detection. However, the existing models deal with community structure independently, which seriously affects the effectiveness of detection models. In this paper, we propose an end-to-end method based on community structure and text features for offensive language detection (CT-OLD). Specifically, the community structure features are directly captured by the graph attention network layer, and the text embeddings are taken from the last hidden layer of BERT. Attention mechanisms and position encoding are used to fuse these features. Meanwhile, we add user opinion to the community structure for representing user features. The user opinion is represented by user historical behavior information, which outperforms that represented by text information. Besides the above point, the distribution of users and tweets is unbalanced in the popular datasets, which limits the generalization ability of the model. To address this issue, we construct and release a dataset with reasonable user distribution. Our method outperforms baselines with the F1 score of 89.94%. The results show that the end-to-end model effectively learns the potential information of community structure and text, and user historical behavior information is more suitable for user opinion representation.