 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnmasking the Shadows: Pinpoint the Implementations of Anti-Dynamic Analysis Techniques in Malware Using LLM
Nov 08, 2024



Sandboxes and other dynamic analysis processes are prevalent in malware detection systems nowadays to enhance the capability of detecting 0-day malware. Therefore, techniques of anti-dynamic analysis (TADA) are prevalent in modern malware samples, and sandboxes can suffer from false negatives and analysis failures when analyzing the samples with TADAs. In such cases, human reverse engineers will get involved in conducting dynamic analysis manually (i.e., debugging, patching), which in turn also gets obstructed by TADAs. In this work, we propose a Large Language Model (LLM) based workflow that can pinpoint the location of the TADA implementation in the code, to help reverse engineers place breakpoints used in debugging. Our evaluation shows that we successfully identified the locations of 87.80% known TADA implementations adopted from public repositories. In addition, we successfully pinpoint the locations of TADAs in 4 well-known malware samples that are documented in online malware analysis blogs.
Hide Your Malicious Goal Into Benign Narratives: Jailbreak Large Language Models through Neural Carrier Articles
Aug 20, 2024



Jailbreak attacks on Language Model Models (LLMs) entail crafting prompts aimed at exploiting the models to generate malicious content. This paper proposes a new type of jailbreak attacks which shift the attention of the LLM by inserting a prohibited query into a carrier article. The proposed attack leverage the knowledge graph and a composer LLM to automatically generating a carrier article that is similar to the topic of the prohibited query but does not violate LLM's safeguards. By inserting the malicious query to the carrier article, the assembled attack payload can successfully jailbreak LLM. To evaluate the effectiveness of our method, we leverage 4 popular categories of ``harmful behaviors'' adopted by related researches to attack 6 popular LLMs. Our experiment results show that the proposed attacking method can successfully jailbreak all the target LLMs which high success rate, except for Claude-3.
Towards Independence Criterion in Machine Unlearning of Features and Labels
Mar 12, 2024



This work delves into the complexities of machine unlearning in the face of distributional shifts, particularly focusing on the challenges posed by non-uniform feature and label removal. With the advent of regulations like the GDPR emphasizing data privacy and the right to be forgotten, machine learning models face the daunting task of unlearning sensitive information without compromising their integrity or performance. Our research introduces a novel approach that leverages influence functions and principles of distributional independence to address these challenges. By proposing a comprehensive framework for machine unlearning, we aim to ensure privacy protection while maintaining model performance and adaptability across varying distributions. Our method not only facilitates efficient data removal but also dynamically adjusts the model to preserve its generalization capabilities. Through extensive experimentation, we demonstrate the efficacy of our approach in scenarios characterized by significant distributional shifts, making substantial contributions to the field of machine unlearning. This research paves the way for developing more resilient and adaptable unlearning techniques, ensuring models remain robust and accurate in the dynamic landscape of data privacy and machine learning.
DPlis: Boosting Utility of Differentially Private Deep Learning via Randomized Smoothing
Mar 02, 2021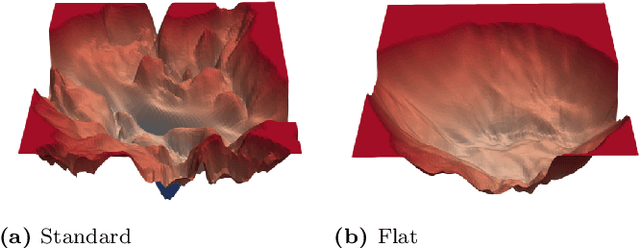
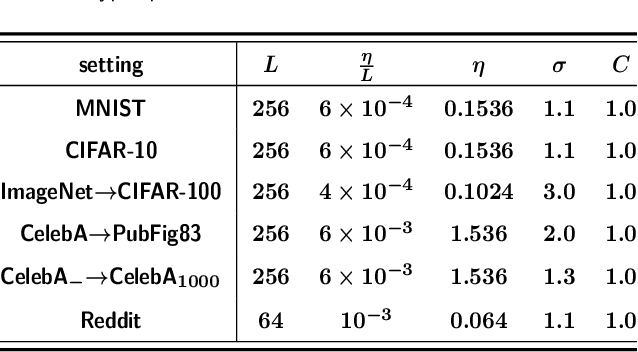

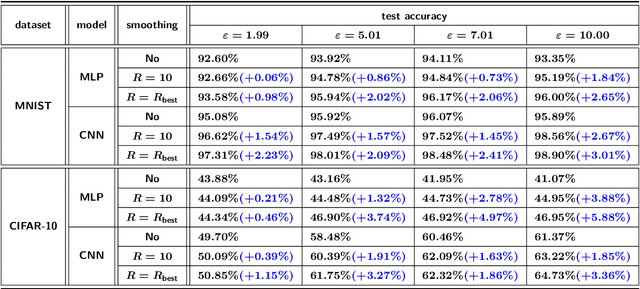
Deep learning techniques have achieved remarkable performance in wide-ranging tasks. However, when trained on privacy-sensitive datasets, the model parameters may expose private information in training data. Prior attempts for differentially private training, although offering rigorous privacy guarantees, lead to much lower model performance than the non-private ones. Besides, different runs of the same training algorithm produce models with large performance variance. To address these issues, we propose DPlis--Differentially Private Learning wIth Smoothing. The core idea of DPlis is to construct a smooth loss function that favors noise-resilient models lying in large flat regions of the loss landscape. We provide theoretical justification for the utility improvements of DPlis. Extensive experiments also demonstrate that DPlis can effectively boost model quality and training stability under a given privacy budget.