 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnlearning Information Bottleneck: Machine Unlearning of Systematic Patterns and Biases
May 22, 2024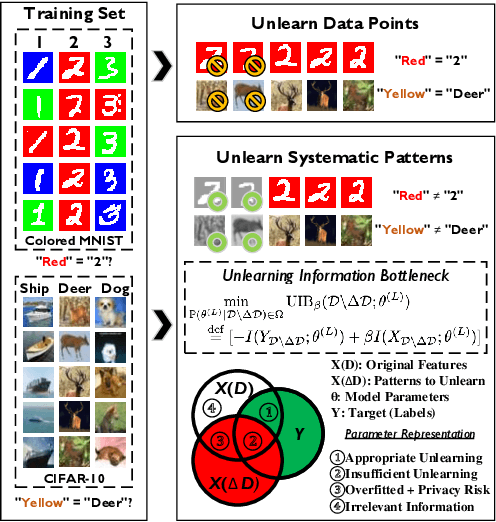
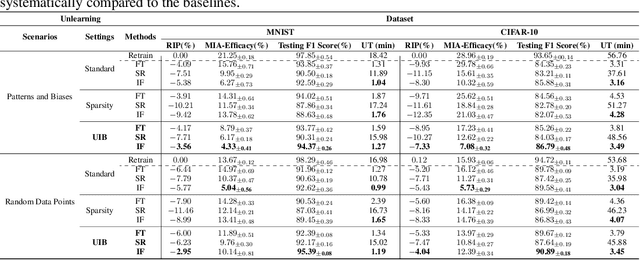
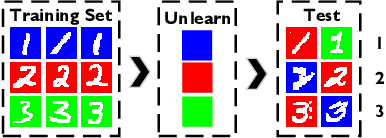

Effective adaptation to distribution shifts in training data is pivotal for sustaining robustness in neural networks, especially when removing specific biases or outdated information, a process known as machine unlearning. Traditional approaches typically assume that data variations are random, which makes it difficult to adjust the model parameters accurately to remove patterns and characteristics from unlearned data. In this work, we present Unlearning Information Bottleneck (UIB), a novel information-theoretic framework designed to enhance the process of machine unlearning that effectively leverages the influence of systematic patterns and biases for parameter adjustment. By proposing a variational upper bound, we recalibrate the model parameters through a dynamic prior that integrates changes in data distribution with an affordable computational cost, allowing efficient and accurate removal of outdated or unwanted data patterns and biases. Our experiments across various datasets, models, and unlearning methods demonstrate that our approach effectively removes systematic patterns and biases while maintaining the performance of models post-unlearning.
Towards Independence Criterion in Machine Unlearning of Features and Labels
Mar 12, 2024



This work delves into the complexities of machine unlearning in the face of distributional shifts, particularly focusing on the challenges posed by non-uniform feature and label removal. With the advent of regulations like the GDPR emphasizing data privacy and the right to be forgotten, machine learning models face the daunting task of unlearning sensitive information without compromising their integrity or performance. Our research introduces a novel approach that leverages influence functions and principles of distributional independence to address these challenges. By proposing a comprehensive framework for machine unlearning, we aim to ensure privacy protection while maintaining model performance and adaptability across varying distributions. Our method not only facilitates efficient data removal but also dynamically adjusts the model to preserve its generalization capabilities. Through extensive experimentation, we demonstrate the efficacy of our approach in scenarios characterized by significant distributional shifts, making substantial contributions to the field of machine unlearning. This research paves the way for developing more resilient and adaptable unlearning techniques, ensuring models remain robust and accurate in the dynamic landscape of data privacy and machine learning.
Spherical Convolution empowered FoV Prediction in 360-degree Video Multicast with Limited FoV Feedback
Jan 29, 2022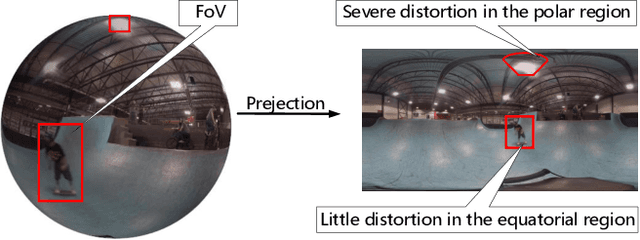

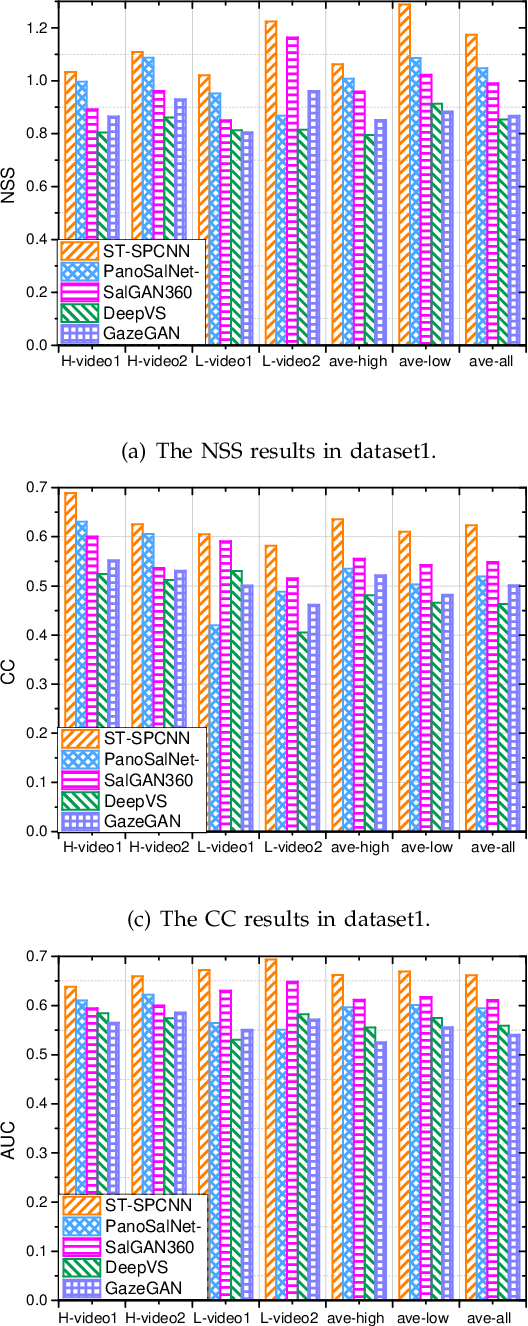
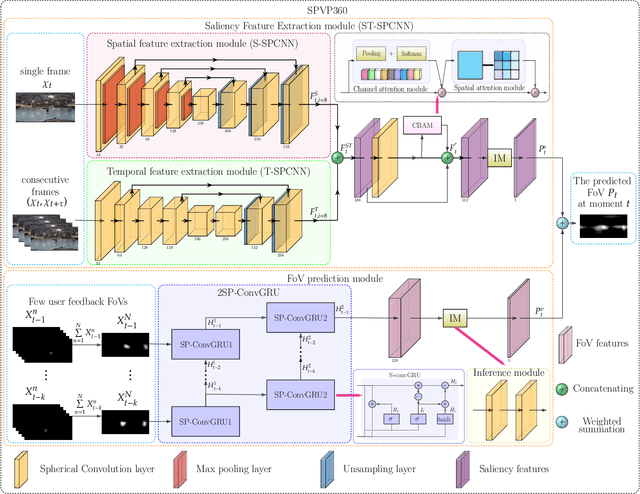
Field of view (FoV) prediction is critical in 360-degree video multicast, which is a key component of the emerging Virtual Reality (VR) and Augmented Reality (AR) applications. Most of the current prediction methods combining saliency detection and FoV information neither take into account that the distortion of projected 360-degree videos can invalidate the weight sharing of traditional convolutional networks, nor do they adequately consider the difficulty of obtaining complete multi-user FoV information, which degrades the prediction performance. This paper proposes a spherical convolution-empowered FoV prediction method, which is a multi-source prediction framework combining salient features extracted from 360-degree video with limited FoV feedback information. A spherical convolution neural network (CNN) is used instead of a traditional two-dimensional CNN to eliminate the problem of weight sharing failure caused by video projection distortion. Specifically, salient spatial-temporal features are extracted through a spherical convolution-based saliency detection model, after which the limited feedback FoV information is represented as a time-series model based on a spherical convolution-empowered gated recurrent unit network. Finally, the extracted salient video features are combined to predict future user FoVs. The experimental results show that the performance of the proposed method is better than other prediction methods.