 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeViewport Prediction for Volumetric Video Streaming by Exploring Video Saliency and Trajectory Information
Nov 28, 2023Volumetric video, also known as hologram video, is a novel medium that portrays natural content in Virtual Reality (VR), Augmented Reality (AR), and Mixed Reality (MR). It is expected to be the next-gen video technology and a prevalent use case for 5G and beyond wireless communication. Considering that each user typically only watches a section of the volumetric video, known as the viewport, it is essential to have precise viewport prediction for optimal performance. However, research on this topic is still in its infancy. In the end, this paper presents and proposes a novel approach, named Saliency and Trajectory Viewport Prediction (STVP), which aims to improve the precision of viewport prediction in volumetric video streaming. The STVP extensively utilizes video saliency information and viewport trajectory. To our knowledge, this is the first comprehensive study of viewport prediction in volumetric video streaming. In particular, we introduce a novel sampling method, Uniform Random Sampling (URS), to reduce computational complexity while still preserving video features in an efficient manner. Then we present a saliency detection technique that incorporates both spatial and temporal information for detecting static, dynamic geometric, and color salient regions. Finally, we intelligently fuse saliency and trajectory information to achieve more accurate viewport prediction. We conduct extensive simulations to evaluate the effectiveness of our proposed viewport prediction methods using state-of-the-art volumetric video sequences. The experimental results show the superiority of the proposed method over existing schemes. The dataset and source code will be publicly accessible after acceptance.
Diffusion Action Segmentation
Mar 31, 2023Temporal action segmentation is crucial for understanding long-form videos. Previous works on this task commonly adopt an iterative refinement paradigm by using multi-stage models. Our paper proposes an essentially different framework via denoising diffusion models, which nonetheless shares the same inherent spirit of such iterative refinement. In this framework, action predictions are progressively generated from random noise with input video features as conditions. To enhance the modeling of three striking characteristics of human actions, including the position prior, the boundary ambiguity, and the relational dependency, we devise a unified masking strategy for the conditioning inputs in our framework. Extensive experiments on three benchmark datasets, i.e., GTEA, 50Salads, and Breakfast, are performed and the proposed method achieves superior or comparable results to state-of-the-art methods, showing the effectiveness of a generative approach for action segmentation. Our codes will be made available.
Incipient Fault Detection in Power Distribution System: A Time-Frequency Embedded Deep Learning Based Approach
Feb 18, 2023Incipient fault detection in power distribution systems is crucial to improve the reliability of the grid. However, the non-stationary nature and the inadequacy of the training dataset due to the self-recovery of the incipient fault signal, make the incipient fault detection in power distribution systems a great challenge. In this paper, we focus on incipient fault detection in power distribution systems and address the above challenges. In particular, we propose an ADaptive Time-Frequency Memory(AD-TFM) cell by embedding wavelet transform into the Long Short-Term Memory (LSTM), to extract features in time and frequency domain from the non-stationary incipient fault signals.We make scale parameters and translation parameters of wavelet transform learnable to adapt to the dynamic input signals. Based on the stacked AD-TFM cells, we design a recurrent neural network with ATtention mechanism, named AD-TFM-AT model, to detect incipient fault with multi-resolution and multi-dimension analysis. In addition, we propose two data augmentation methods, namely phase switching and temporal sliding, to effectively enlarge the training datasets. Experimental results on two open datasets show that our proposed AD-TFM-AT model and data augmentation methods achieve state-of-the-art (SOTA) performance of incipient fault detection in power distribution system. We also disclose one used dataset logged at State Grid Corporation of China to facilitate future research.
Spherical Convolution empowered FoV Prediction in 360-degree Video Multicast with Limited FoV Feedback
Jan 29, 2022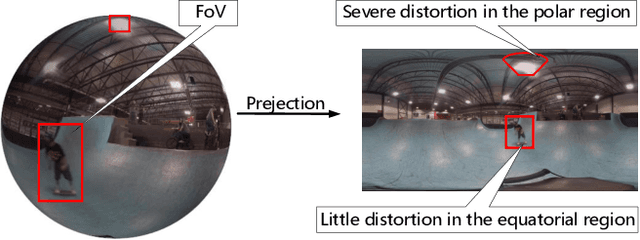

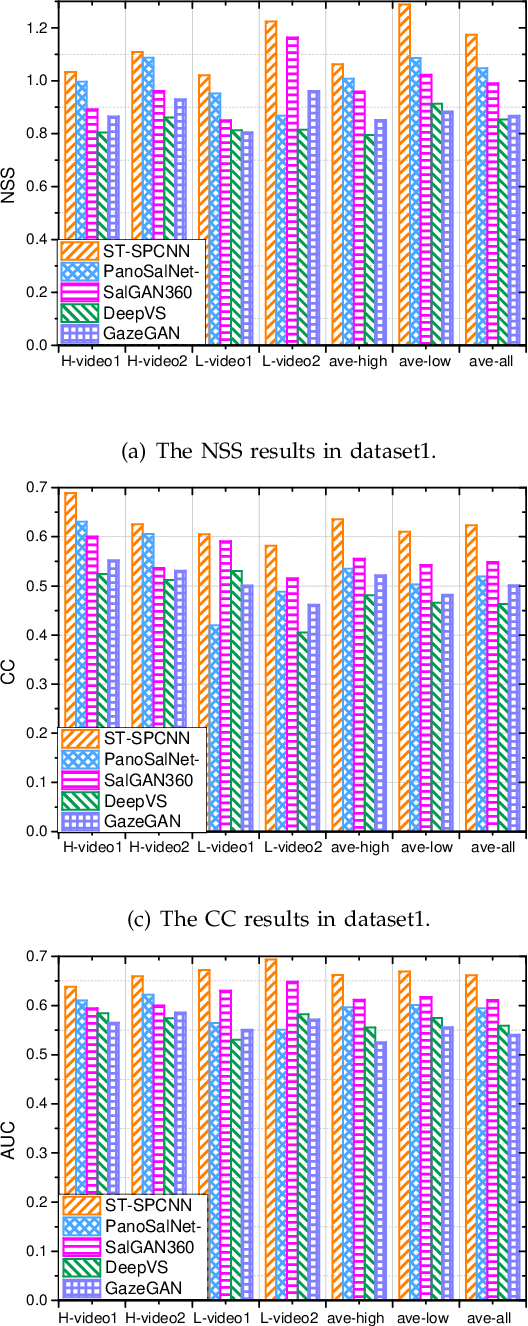
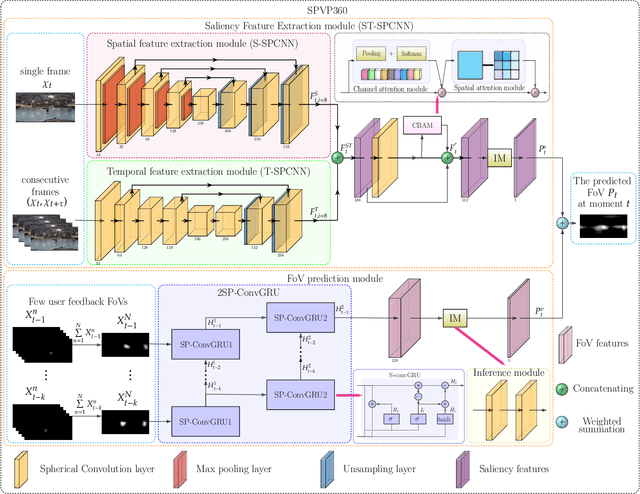
Field of view (FoV) prediction is critical in 360-degree video multicast, which is a key component of the emerging Virtual Reality (VR) and Augmented Reality (AR) applications. Most of the current prediction methods combining saliency detection and FoV information neither take into account that the distortion of projected 360-degree videos can invalidate the weight sharing of traditional convolutional networks, nor do they adequately consider the difficulty of obtaining complete multi-user FoV information, which degrades the prediction performance. This paper proposes a spherical convolution-empowered FoV prediction method, which is a multi-source prediction framework combining salient features extracted from 360-degree video with limited FoV feedback information. A spherical convolution neural network (CNN) is used instead of a traditional two-dimensional CNN to eliminate the problem of weight sharing failure caused by video projection distortion. Specifically, salient spatial-temporal features are extracted through a spherical convolution-based saliency detection model, after which the limited feedback FoV information is represented as a time-series model based on a spherical convolution-empowered gated recurrent unit network. Finally, the extracted salient video features are combined to predict future user FoVs. The experimental results show that the performance of the proposed method is better than other prediction methods.
A QoE Model in Point Cloud Video Streaming
Nov 09, 2021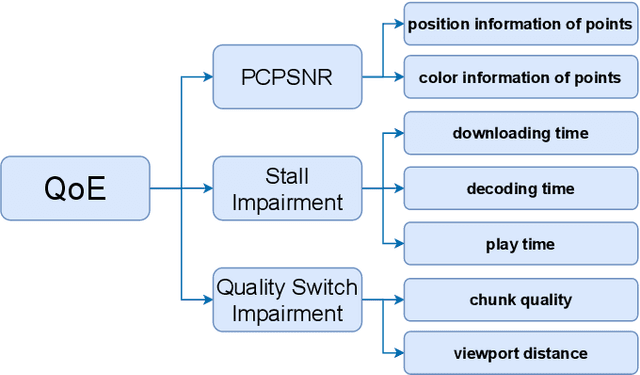
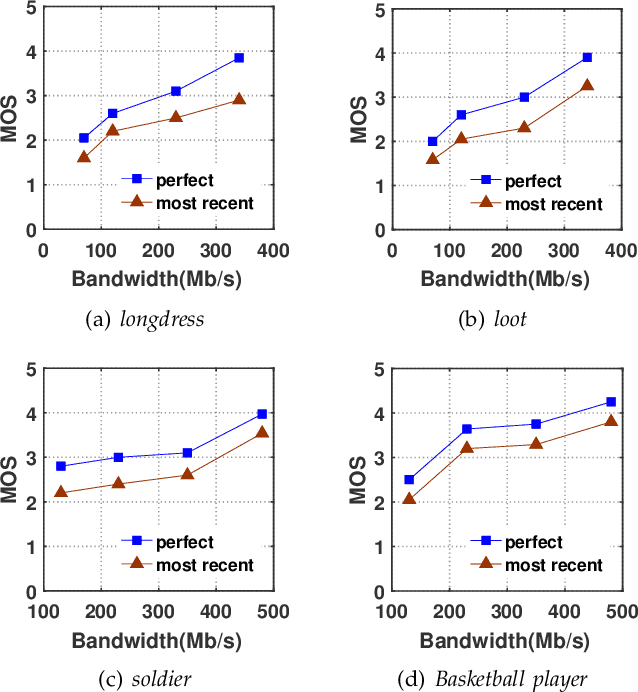
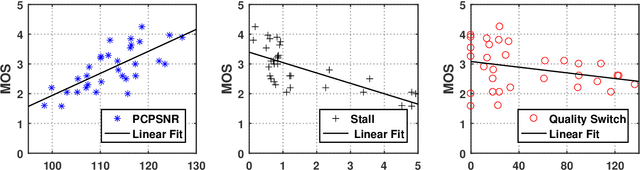
Point cloud video has been widely used by augmented reality (AR) and virtual reality (VR) applications as it allows users to have an immersive experience of six degrees of freedom (6DoFs). Yet there is still a lack of research on quality of experience (QoE) model of point cloud video streaming, which cannot provide optimization metric for streaming systems. Besides, position and color information contained in each pixel of point cloud video, and viewport distance effect caused by 6DoFs viewing procedure make the traditional objective quality evaluation metric cannot be directly used in point cloud video streaming system. In this paper we first analyze the subjective and objective factors related to QoE model. Then an experimental system to simulate point cloud video streaming is setup and detailed subjective quality evaluation experiments are carried out. Based on collected mean opinion score (MOS) data, we propose a QoE model for point cloud video streaming. We also verify the model by actual subjective scoring, and the results show that the proposed QoE model can accurately reflect users' visual perception. We also make the experimental database public to promote the QoE research of point cloud video streaming.
Towards Unified Surgical Skill Assessment
Jun 02, 2021



Surgical skills have a great influence on surgical safety and patients' well-being. Traditional assessment of surgical skills involves strenuous manual efforts, which lacks efficiency and repeatability. Therefore, we attempt to automatically predict how well the surgery is performed using the surgical video. In this paper, a unified multi-path framework for automatic surgical skill assessment is proposed, which takes care of multiple composing aspects of surgical skills, including surgical tool usage, intraoperative event pattern, and other skill proxies. The dependency relationships among these different aspects are specially modeled by a path dependency module in the framework. We conduct extensive experiments on the JIGSAWS dataset of simulated surgical tasks, and a new clinical dataset of real laparoscopic surgeries. The proposed framework achieves promising results on both datasets, with the state-of-the-art on the simulated dataset advanced from 0.71 Spearman's correlation to 0.80. It is also shown that combining multiple skill aspects yields better performance than relying on a single aspect.