 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIncipient Fault Detection in Power Distribution System: A Time-Frequency Embedded Deep Learning Based Approach
Feb 18, 2023Incipient fault detection in power distribution systems is crucial to improve the reliability of the grid. However, the non-stationary nature and the inadequacy of the training dataset due to the self-recovery of the incipient fault signal, make the incipient fault detection in power distribution systems a great challenge. In this paper, we focus on incipient fault detection in power distribution systems and address the above challenges. In particular, we propose an ADaptive Time-Frequency Memory(AD-TFM) cell by embedding wavelet transform into the Long Short-Term Memory (LSTM), to extract features in time and frequency domain from the non-stationary incipient fault signals.We make scale parameters and translation parameters of wavelet transform learnable to adapt to the dynamic input signals. Based on the stacked AD-TFM cells, we design a recurrent neural network with ATtention mechanism, named AD-TFM-AT model, to detect incipient fault with multi-resolution and multi-dimension analysis. In addition, we propose two data augmentation methods, namely phase switching and temporal sliding, to effectively enlarge the training datasets. Experimental results on two open datasets show that our proposed AD-TFM-AT model and data augmentation methods achieve state-of-the-art (SOTA) performance of incipient fault detection in power distribution system. We also disclose one used dataset logged at State Grid Corporation of China to facilitate future research.
3D Matting: A Benchmark Study on Soft Segmentation Method for Pulmonary Nodules Applied in Computed Tomography
Oct 11, 2022
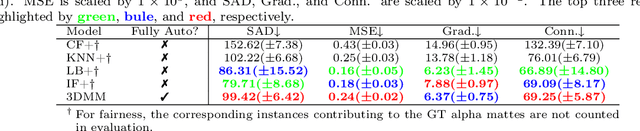
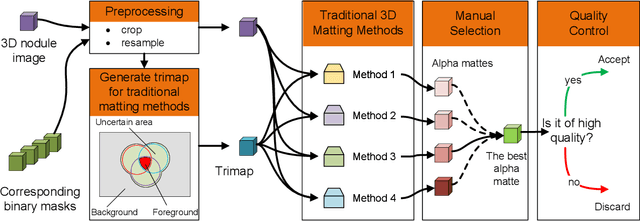
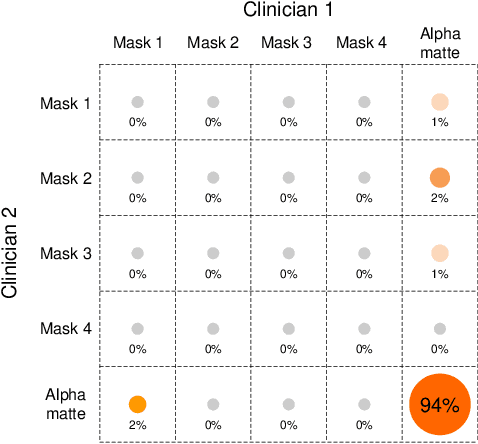
Usually, lesions are not isolated but are associated with the surrounding tissues. For example, the growth of a tumour can depend on or infiltrate into the surrounding tissues. Due to the pathological nature of the lesions, it is challenging to distinguish their boundaries in medical imaging. However, these uncertain regions may contain diagnostic information. Therefore, the simple binarization of lesions by traditional binary segmentation can result in the loss of diagnostic information. In this work, we introduce the image matting into the 3D scenes and use the alpha matte, i.e., a soft mask, to describe lesions in a 3D medical image. The traditional soft mask acted as a training trick to compensate for the easily mislabelled or under-labelled ambiguous regions. In contrast, 3D matting uses soft segmentation to characterize the uncertain regions more finely, which means that it retains more structural information for subsequent diagnosis and treatment. The current study of image matting methods in 3D is limited. To address this issue, we conduct a comprehensive study of 3D matting, including both traditional and deep-learning-based methods. We adapt four state-of-the-art 2D image matting algorithms to 3D scenes and further customize the methods for CT images to calibrate the alpha matte with the radiodensity. Moreover, we propose the first end-to-end deep 3D matting network and implement a solid 3D medical image matting benchmark. Its efficient counterparts are also proposed to achieve a good performance-computation balance. Furthermore, there is no high-quality annotated dataset related to 3D matting, slowing down the development of data-driven deep-learning-based methods. To address this issue, we construct the first 3D medical matting dataset. The validity of the dataset was verified through clinicians' assessments and downstream experiments.
FasterX: Real-Time Object Detection Based on Edge GPUs for UAV Applications
Sep 07, 2022


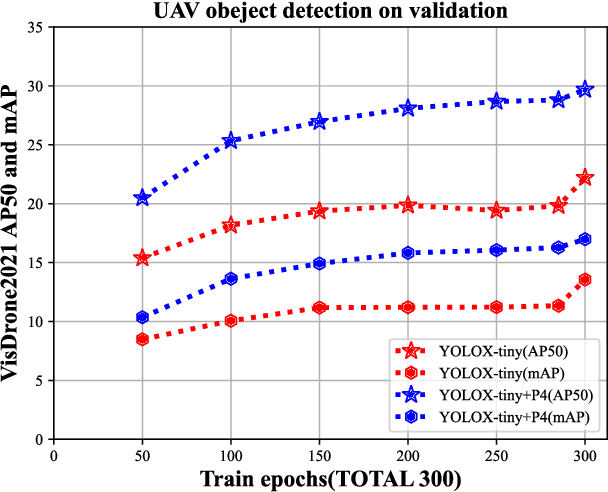
Real-time object detection on Unmanned Aerial Vehicles (UAVs) is a challenging issue due to the limited computing resources of edge GPU devices as Internet of Things (IoT) nodes. To solve this problem, in this paper, we propose a novel lightweight deep learning architectures named FasterX based on YOLOX model for real-time object detection on edge GPU. First, we design an effective and lightweight PixSF head to replace the original head of YOLOX to better detect small objects, which can be further embedded in the depthwise separable convolution (DS Conv) to achieve a lighter head. Then, a slimmer structure in the Neck layer termed as SlimFPN is developed to reduce parameters of the network, which is a trade-off between accuracy and speed. Furthermore, we embed attention module in the Head layer to improve the feature extraction effect of the prediction head. Meanwhile, we also improve the label assignment strategy and loss function to alleviate category imbalance and box optimization problems of the UAV dataset. Finally, auxiliary heads are presented for online distillation to improve the ability of position embedding and feature extraction in PixSF head. The performance of our lightweight models are validated experimentally on the NVIDIA Jetson NX and Jetson Nano GPU embedded platforms.Extensive experiments show that FasterX models achieve better trade-off between accuracy and latency on VisDrone2021 dataset compared to state-of-the-art models.
The 1st Tiny Object Detection Challenge:Methods and Results
Oct 06, 2020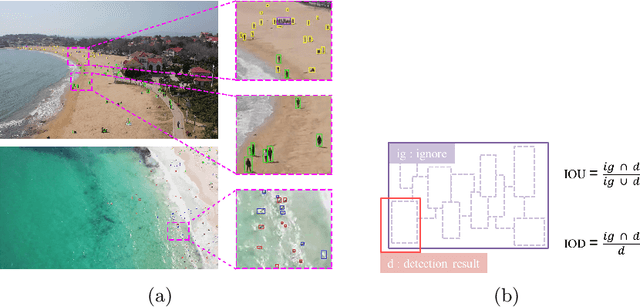
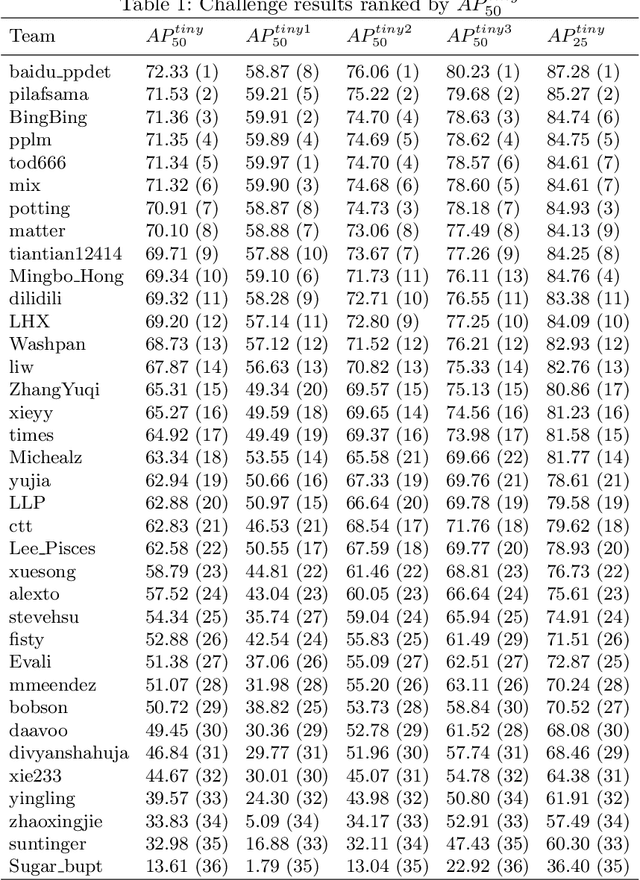
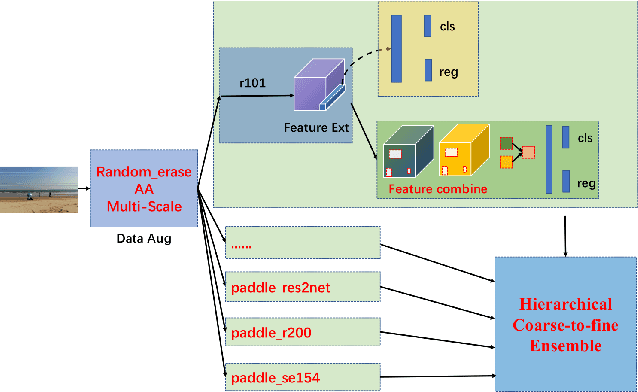

The 1st Tiny Object Detection (TOD) Challenge aims to encourage research in developing novel and accurate methods for tiny object detection in images which have wide views, with a current focus on tiny person detection. The TinyPerson dataset was used for the TOD Challenge and is publicly released. It has 1610 images and 72651 box-levelannotations. Around 36 participating teams from the globe competed inthe 1st TOD Challenge. In this paper, we provide a brief summary of the1st TOD Challenge including brief introductions to the top three methods.The submission leaderboard will be reopened for researchers that areinterested in the TOD challenge. The benchmark dataset and other information can be found at: https://github.com/ucas-vg/TinyBenchmark.