 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSEMINAR: Search Enhanced Multi-modal Interest Network and Approximate Retrieval for Lifelong Sequential Recommendation
Jul 15, 2024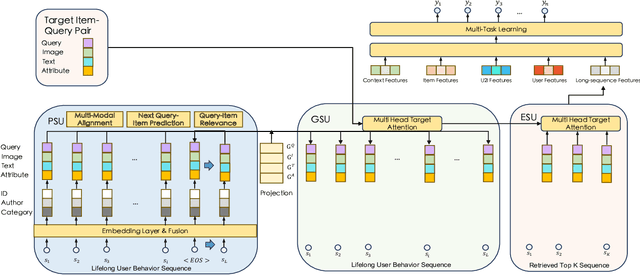

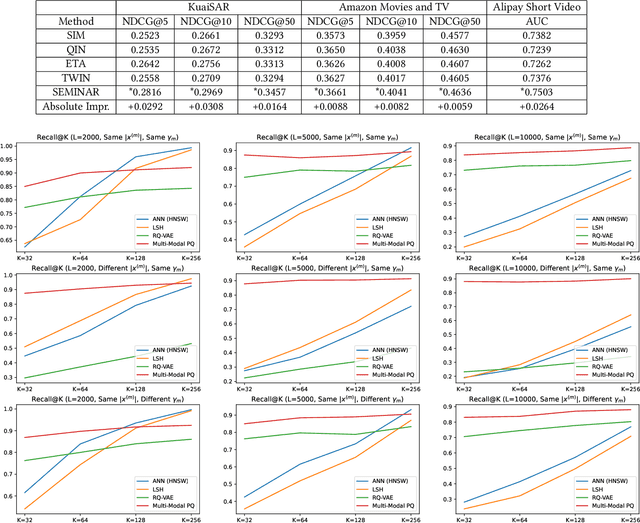
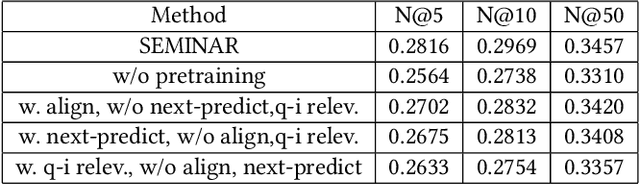
The modeling of users' behaviors is crucial in modern recommendation systems. A lot of research focuses on modeling users' lifelong sequences, which can be extremely long and sometimes exceed thousands of items. These models use the target item to search for the most relevant items from the historical sequence. However, training lifelong sequences in click through rate (CTR) prediction or personalized search ranking (PSR) is extremely difficult due to the insufficient learning problem of ID embedding, especially when the IDs in the lifelong sequence features do not exist in the samples of training dataset. Additionally, existing target attention mechanisms struggle to learn the multi-modal representations of items in the sequence well. The distribution of multi-modal embedding (text, image and attributes) output of user's interacted items are not properly aligned and there exist divergence across modalities. We also observe that users' search query sequences and item browsing sequences can fully depict users' intents and benefit from each other. To address these challenges, we propose a unified lifelong multi-modal sequence model called SEMINAR-Search Enhanced Multi-Modal Interest Network and Approximate Retrieval. Specifically, a network called Pretraining Search Unit (PSU) learns the lifelong sequences of multi-modal query-item pairs in a pretraining-finetuning manner with multiple objectives: multi-modal alignment, next query-item pair prediction, query-item relevance prediction, etc. After pretraining, the downstream model restores the pretrained embedding as initialization and finetunes the network. To accelerate the online retrieval speed of multi-modal embedding, we propose a multi-modal codebook-based product quantization strategy to approximate the exact attention calculati
An Unified Search and Recommendation Foundation Model for Cold-Start Scenario
Sep 16, 2023


In modern commercial search engines and recommendation systems, data from multiple domains is available to jointly train the multi-domain model. Traditional methods train multi-domain models in the multi-task setting, with shared parameters to learn the similarity of multiple tasks, and task-specific parameters to learn the divergence of features, labels, and sample distributions of individual tasks. With the development of large language models, LLM can extract global domain-invariant text features that serve both search and recommendation tasks. We propose a novel framework called S\&R Multi-Domain Foundation, which uses LLM to extract domain invariant features, and Aspect Gating Fusion to merge the ID feature, domain invariant text features and task-specific heterogeneous sparse features to obtain the representations of query and item. Additionally, samples from multiple search and recommendation scenarios are trained jointly with Domain Adaptive Multi-Task module to obtain the multi-domain foundation model. We apply the S\&R Multi-Domain foundation model to cold start scenarios in the pretrain-finetune manner, which achieves better performance than other SOTA transfer learning methods. The S\&R Multi-Domain Foundation model has been successfully deployed in Alipay Mobile Application's online services, such as content query recommendation and service card recommendation, etc.
Treatment Outcome Prediction for Intracerebral Hemorrhage via Generative Prognostic Model with Imaging and Tabular Data
Jul 24, 2023


Intracerebral hemorrhage (ICH) is the second most common and deadliest form of stroke. Despite medical advances, predicting treat ment outcomes for ICH remains a challenge. This paper proposes a novel prognostic model that utilizes both imaging and tabular data to predict treatment outcome for ICH. Our model is trained on observational data collected from non-randomized controlled trials, providing reliable predictions of treatment success. Specifically, we propose to employ a variational autoencoder model to generate a low-dimensional prognostic score, which can effectively address the selection bias resulting from the non-randomized controlled trials. Importantly, we develop a variational distributions combination module that combines the information from imaging data, non-imaging clinical data, and treatment assignment to accurately generate the prognostic score. We conducted extensive experiments on a real-world clinical dataset of intracerebral hemorrhage. Our proposed method demonstrates a substantial improvement in treatment outcome prediction compared to existing state-of-the-art approaches. Code is available at https://github.com/med-air/TOP-GPM
Diffusion Model based Semi-supervised Learning on Brain Hemorrhage Images for Efficient Midline Shift Quantification
Jan 01, 2023



Brain midline shift (MLS) is one of the most critical factors to be considered for clinical diagnosis and treatment decision-making for intracranial hemorrhage. Existing computational methods on MLS quantification not only require intensive labeling in millimeter-level measurement but also suffer from poor performance due to their dependence on specific landmarks or simplified anatomical assumptions. In this paper, we propose a novel semi-supervised framework to accurately measure the scale of MLS from head CT scans. We formulate the MLS measurement task as a deformation estimation problem and solve it using a few MLS slices with sparse labels. Meanwhile, with the help of diffusion models, we are able to use a great number of unlabeled MLS data and 2793 non-MLS cases for representation learning and regularization. The extracted representation reflects how the image is different from a non-MLS image and regularization serves an important role in the sparse-to-dense refinement of the deformation field. Our experiment on a real clinical brain hemorrhage dataset has achieved state-of-the-art performance and can generate interpretable deformation fields.
SM+: Refined Scale Match for Tiny Person Detection
Feb 06, 2021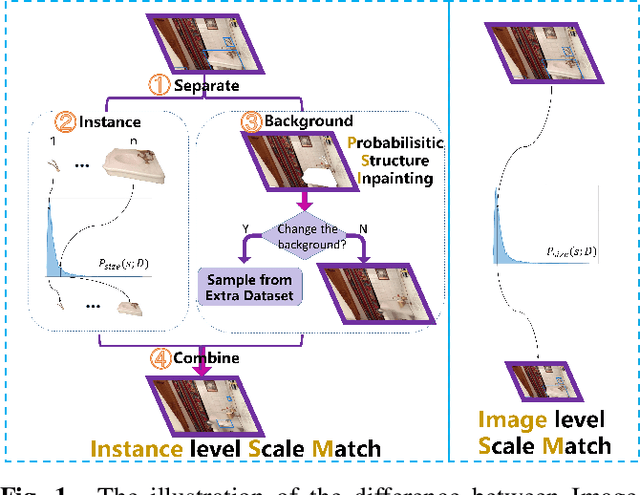
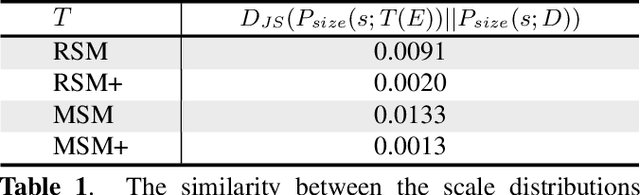

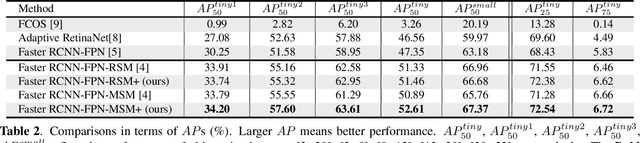
Detecting tiny objects ( e.g., less than 20 x 20 pixels) in large-scale images is an important yet open problem. Modern CNN-based detectors are challenged by the scale mismatch between the dataset for network pre-training and the target dataset for detector training. In this paper, we investigate the scale alignment between pre-training and target datasets, and propose a new refined Scale Match method (termed SM+) for tiny person detection. SM+ improves the scale match from image level to instance level, and effectively promotes the similarity between pre-training and target dataset. Moreover, considering SM+ possibly destroys the image structure, a new probabilistic structure inpainting (PSI) method is proposed for the background processing. Experiments conducted across various detectors show that SM+ noticeably improves the performance on TinyPerson, and outperforms the state-of-the-art detectors with a significant margin.
Effective Fusion Factor in FPN for Tiny Object Detection
Nov 09, 2020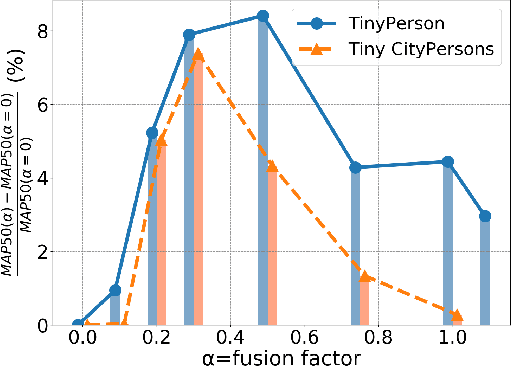
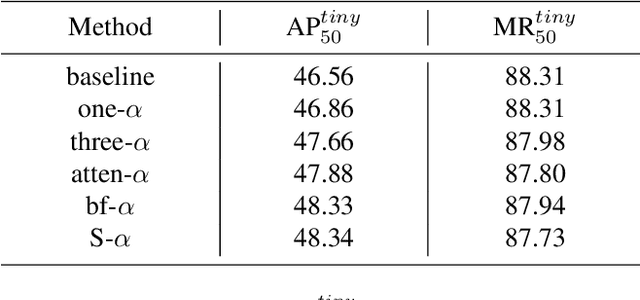
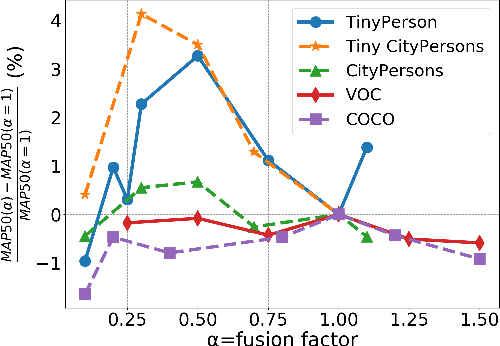
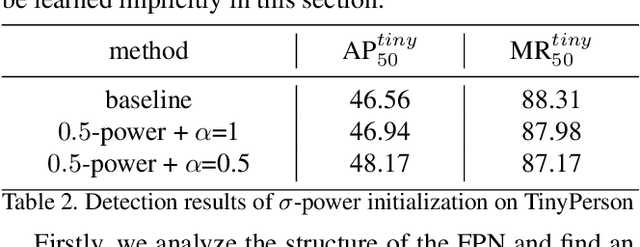
FPN-based detectors have made significant progress in general object detection, e.g., MS COCO and PASCAL VOC. However, these detectors fail in certain application scenarios, e.g., tiny object detection. In this paper, we argue that the top-down connections between adjacent layers in FPN bring two-side influences for tiny object detection, not only positive. We propose a novel concept, fusion factor, to control information that deep layers deliver to shallow layers, for adapting FPN to tiny object detection. After series of experiments and analysis, we explore how to estimate an effective value of fusion factor for a particular dataset by a statistical method. The estimation is dependent on the number of objects distributed in each layer. Comprehensive experiments are conducted on tiny object detection datasets, e.g., TinyPerson and Tiny CityPersons. Our results show that when configuring FPN with a proper fusion factor, the network is able to achieve significant performance gains over the baseline on tiny object detection datasets. Codes and models will be released.
The 1st Tiny Object Detection Challenge:Methods and Results
Oct 06, 2020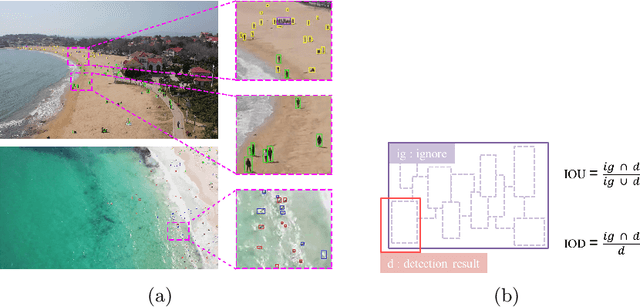
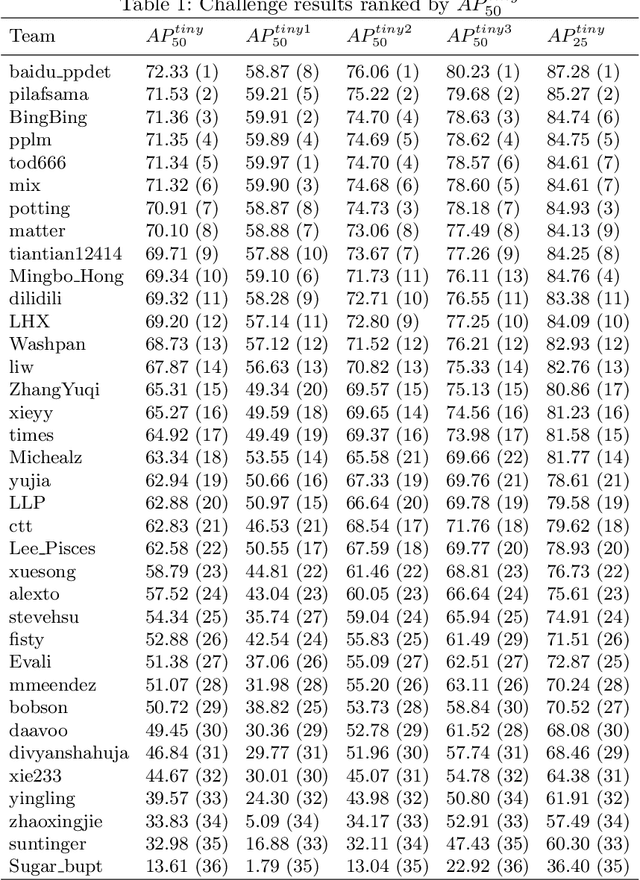
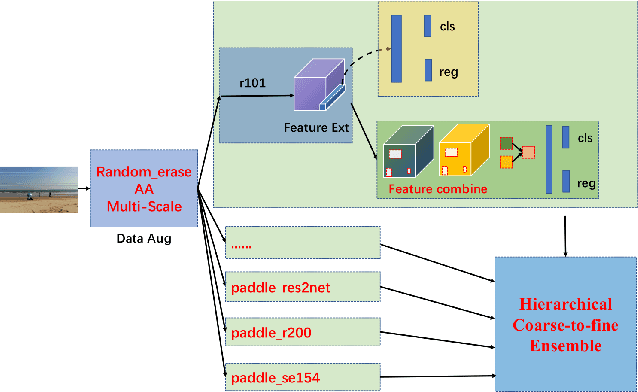

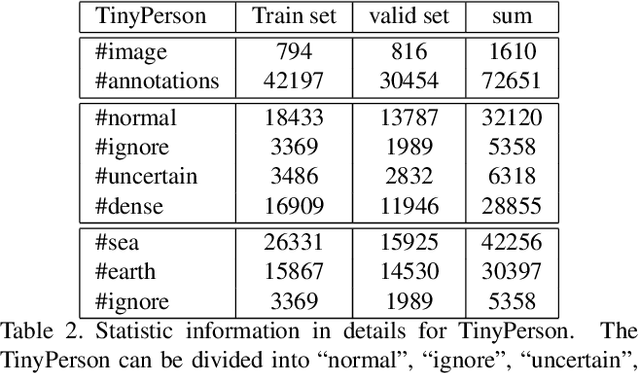
The 1st Tiny Object Detection (TOD) Challenge aims to encourage research in developing novel and accurate methods for tiny object detection in images which have wide views, with a current focus on tiny person detection. The TinyPerson dataset was used for the TOD Challenge and is publicly released. It has 1610 images and 72651 box-levelannotations. Around 36 participating teams from the globe competed inthe 1st TOD Challenge. In this paper, we provide a brief summary of the1st TOD Challenge including brief introductions to the top three methods.The submission leaderboard will be reopened for researchers that areinterested in the TOD challenge. The benchmark dataset and other information can be found at: https://github.com/ucas-vg/TinyBenchmark.
Scale Match for Tiny Person Detection
Dec 23, 2019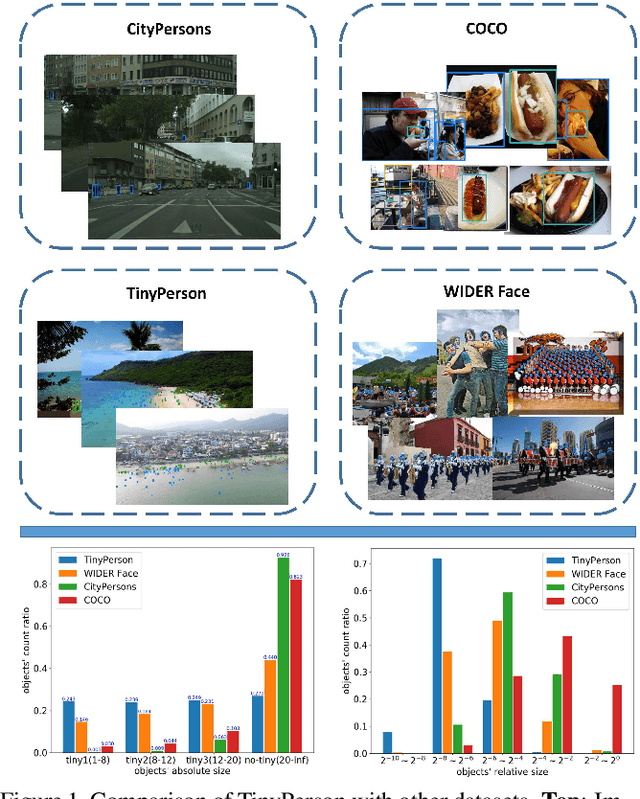
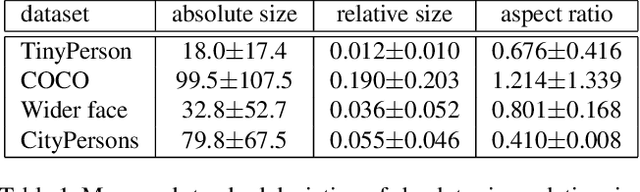

Visual object detection has achieved unprecedented ad-vance with the rise of deep convolutional neural networks.However, detecting tiny objects (for example tiny per-sons less than 20 pixels) in large-scale images remainsnot well investigated. The extremely small objects raisea grand challenge about feature representation while themassive and complex backgrounds aggregate the risk offalse alarms. In this paper, we introduce a new benchmark,referred to as TinyPerson, opening up a promising directionfor tiny object detection in a long distance and with mas-sive backgrounds. We experimentally find that the scale mis-match between the dataset for network pre-training and thedataset for detector learning could deteriorate the featurerepresentation and the detectors. Accordingly, we proposea simple yet effective Scale Match approach to align theobject scales between the two datasets for favorable tiny-object representation. Experiments show the significantperformance gain of our proposed approach over state-of-the-art detectors, and the challenging aspects of TinyPersonrelated to real-world scenarios. The TinyPerson benchmarkand the code for our approach will be publicly available(https://github.com/ucas-vg/TinyBenchmark).(Attention: evaluation rules of AP have updated in benchmark after this paper accepted, So this paper use old rules. we will keep old rules of AP in benchmark, but we recommand the new and we will use the new in latter research.)