 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHistory-Enhanced Two-Stage Transformer for Aerial Vision-and-Language Navigation
Dec 17, 2025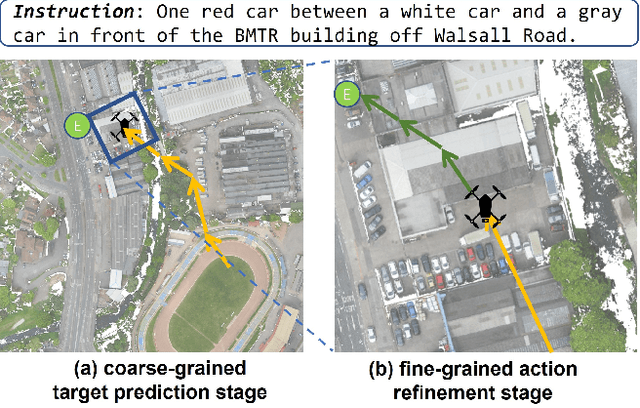


Aerial Vision-and-Language Navigation (AVLN) requires Unmanned Aerial Vehicle (UAV) agents to localize targets in large-scale urban environments based on linguistic instructions. While successful navigation demands both global environmental reasoning and local scene comprehension, existing UAV agents typically adopt mono-granularity frameworks that struggle to balance these two aspects. To address this limitation, this work proposes a History-Enhanced Two-Stage Transformer (HETT) framework, which integrates the two aspects through a coarse-to-fine navigation pipeline. Specifically, HETT first predicts coarse-grained target positions by fusing spatial landmarks and historical context, then refines actions via fine-grained visual analysis. In addition, a historical grid map is designed to dynamically aggregate visual features into a structured spatial memory, enhancing comprehensive scene awareness. Additionally, the CityNav dataset annotations are manually refined to enhance data quality. Experiments on the refined CityNav dataset show that HETT delivers significant performance gains, while extensive ablation studies further verify the effectiveness of each component.
MCPToolBench++: A Large Scale AI Agent Model Context Protocol MCP Tool Use Benchmark
Aug 11, 2025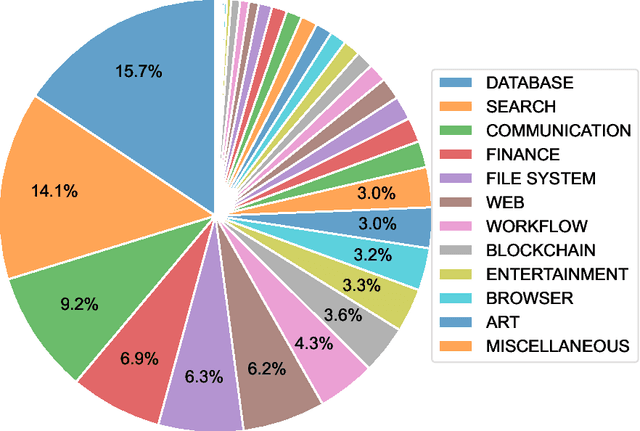
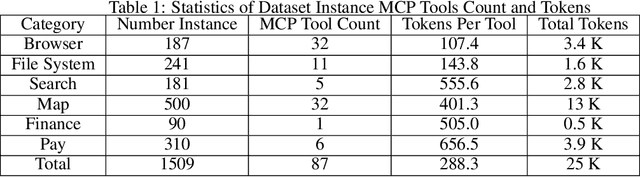
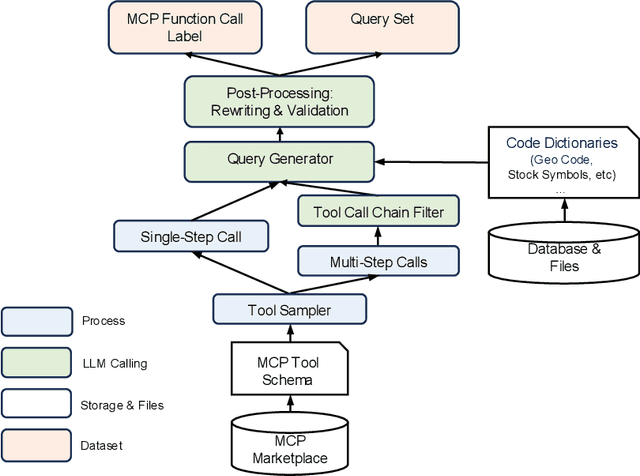
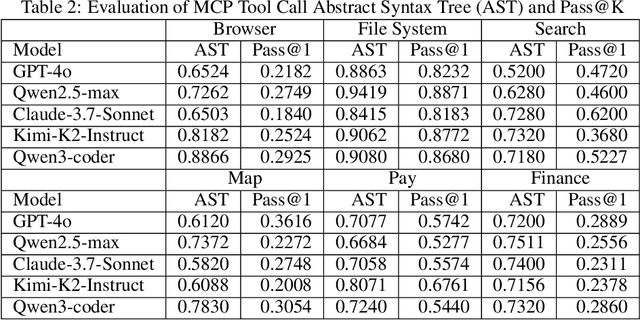
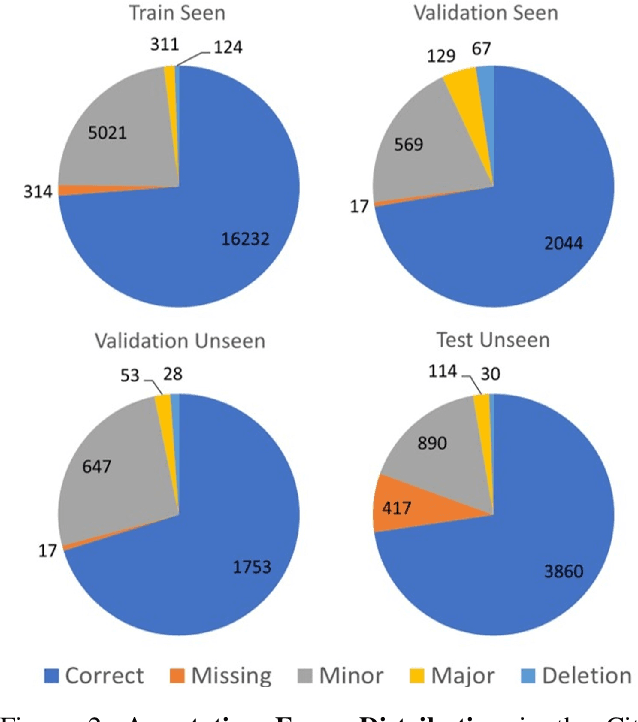
LLMs' capabilities are enhanced by using function calls to integrate various data sources or API results into the context window. Typical tools include search, web crawlers, maps, financial data, file systems, and browser usage, etc. Integrating these data sources or functions requires a standardized method. The Model Context Protocol (MCP) provides a standardized way to supply context to LLMs. However, the evaluation of LLMs and AI Agents' MCP tool use abilities suffer from several issues. First, there's a lack of comprehensive datasets or benchmarks to evaluate various MCP tools. Second, the diverse formats of response from MCP tool call execution further increase the difficulty of evaluation. Additionally, unlike existing tool-use benchmarks with high success rates in functions like programming and math functions, the success rate of real-world MCP tool is not guaranteed and varies across different MCP servers. Furthermore, the LLMs' context window also limits the number of available tools that can be called in a single run, because the textual descriptions of tool and the parameters have long token length for an LLM to process all at once. To help address the challenges of evaluating LLMs' performance on calling MCP tools, we propose MCPToolBench++, a large-scale, multi-domain AI Agent tool use benchmark. As of July 2025, this benchmark is build upon marketplace of over 4k MCP servers from more than 40 categories, collected from the MCP marketplaces and GitHub communities. The datasets consist of both single-step and multi-step tool calls across different categories. We evaluated SOTA LLMs with agentic abilities on this benchmark and reported the results.
SEMINAR: Search Enhanced Multi-modal Interest Network and Approximate Retrieval for Lifelong Sequential Recommendation
Jul 15, 2024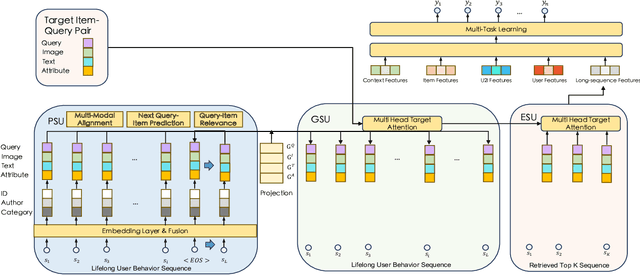

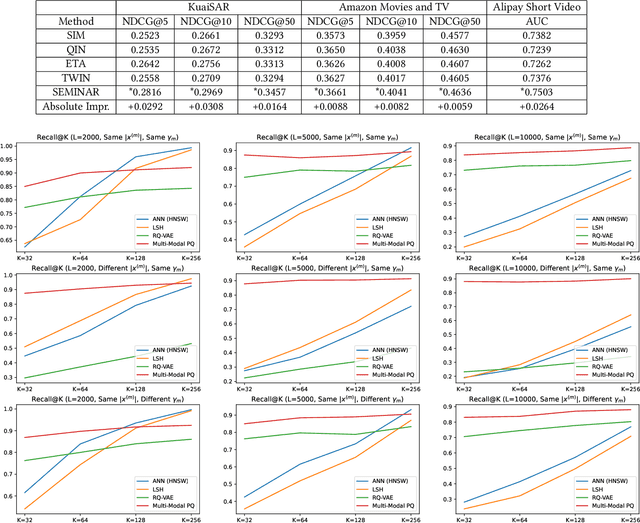
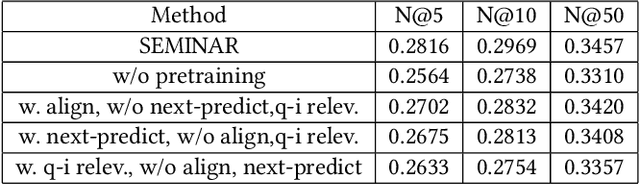
The modeling of users' behaviors is crucial in modern recommendation systems. A lot of research focuses on modeling users' lifelong sequences, which can be extremely long and sometimes exceed thousands of items. These models use the target item to search for the most relevant items from the historical sequence. However, training lifelong sequences in click through rate (CTR) prediction or personalized search ranking (PSR) is extremely difficult due to the insufficient learning problem of ID embedding, especially when the IDs in the lifelong sequence features do not exist in the samples of training dataset. Additionally, existing target attention mechanisms struggle to learn the multi-modal representations of items in the sequence well. The distribution of multi-modal embedding (text, image and attributes) output of user's interacted items are not properly aligned and there exist divergence across modalities. We also observe that users' search query sequences and item browsing sequences can fully depict users' intents and benefit from each other. To address these challenges, we propose a unified lifelong multi-modal sequence model called SEMINAR-Search Enhanced Multi-Modal Interest Network and Approximate Retrieval. Specifically, a network called Pretraining Search Unit (PSU) learns the lifelong sequences of multi-modal query-item pairs in a pretraining-finetuning manner with multiple objectives: multi-modal alignment, next query-item pair prediction, query-item relevance prediction, etc. After pretraining, the downstream model restores the pretrained embedding as initialization and finetunes the network. To accelerate the online retrieval speed of multi-modal embedding, we propose a multi-modal codebook-based product quantization strategy to approximate the exact attention calculati
An Unified Search and Recommendation Foundation Model for Cold-Start Scenario
Sep 16, 2023


In modern commercial search engines and recommendation systems, data from multiple domains is available to jointly train the multi-domain model. Traditional methods train multi-domain models in the multi-task setting, with shared parameters to learn the similarity of multiple tasks, and task-specific parameters to learn the divergence of features, labels, and sample distributions of individual tasks. With the development of large language models, LLM can extract global domain-invariant text features that serve both search and recommendation tasks. We propose a novel framework called S\&R Multi-Domain Foundation, which uses LLM to extract domain invariant features, and Aspect Gating Fusion to merge the ID feature, domain invariant text features and task-specific heterogeneous sparse features to obtain the representations of query and item. Additionally, samples from multiple search and recommendation scenarios are trained jointly with Domain Adaptive Multi-Task module to obtain the multi-domain foundation model. We apply the S\&R Multi-Domain foundation model to cold start scenarios in the pretrain-finetune manner, which achieves better performance than other SOTA transfer learning methods. The S\&R Multi-Domain Foundation model has been successfully deployed in Alipay Mobile Application's online services, such as content query recommendation and service card recommendation, etc.
Prototypical Contrastive Learning and Adaptive Interest Selection for Candidate Generation in Recommendations
Nov 23, 2022



Deep Candidate Generation plays an important role in large-scale recommender systems. It takes user history behaviors as inputs and learns user and item latent embeddings for candidate generation. In the literature, conventional methods suffer from two problems. First, a user has multiple embeddings to reflect various interests, and such number is fixed. However, taking into account different levels of user activeness, a fixed number of interest embeddings is sub-optimal. For example, for less active users, they may need fewer embeddings to represent their interests compared to active users. Second, the negative samples are often generated by strategies with unobserved supervision, and similar items could have different labels. Such a problem is termed as class collision. In this paper, we aim to advance the typical two-tower DNN candidate generation model. Specifically, an Adaptive Interest Selection Layer is designed to learn the number of user embeddings adaptively in an end-to-end way, according to the level of their activeness. Furthermore, we propose a Prototypical Contrastive Learning Module to tackle the class collision problem introduced by negative sampling. Extensive experimental evaluations show that the proposed scheme remarkably outperforms competitive baselines on multiple benchmarks.
Device-Cloud Collaborative Recommendation via Meta Controller
Jul 07, 2022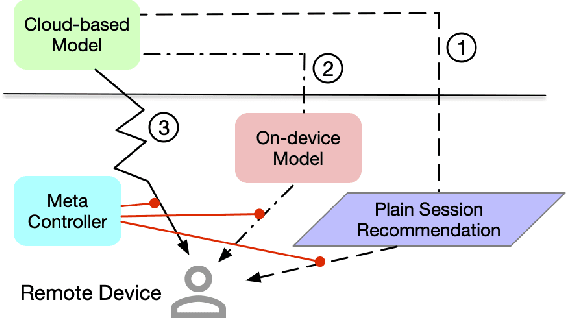
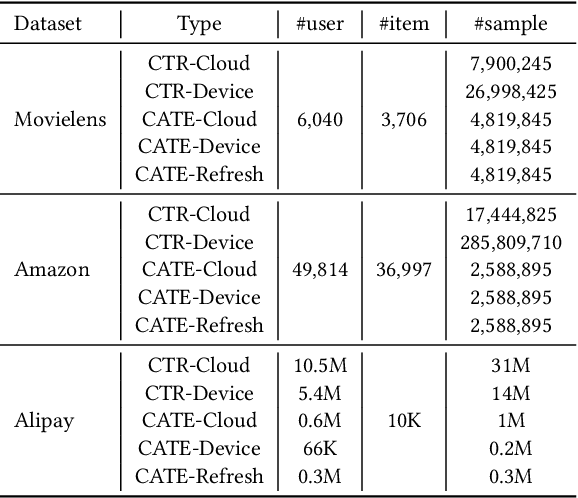
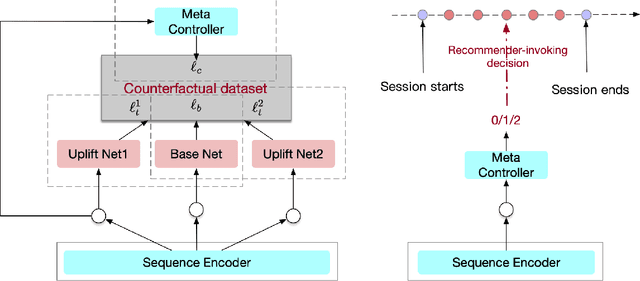
On-device machine learning enables the lightweight deployment of recommendation models in local clients, which reduces the burden of the cloud-based recommenders and simultaneously incorporates more real-time user features. Nevertheless, the cloud-based recommendation in the industry is still very important considering its powerful model capacity and the efficient candidate generation from the billion-scale item pool. Previous attempts to integrate the merits of both paradigms mainly resort to a sequential mechanism, which builds the on-device recommender on top of the cloud-based recommendation. However, such a design is inflexible when user interests dramatically change: the on-device model is stuck by the limited item cache while the cloud-based recommendation based on the large item pool do not respond without the new re-fresh feedback. To overcome this issue, we propose a meta controller to dynamically manage the collaboration between the on-device recommender and the cloud-based recommender, and introduce a novel efficient sample construction from the causal perspective to solve the dataset absence issue of meta controller. On the basis of the counterfactual samples and the extended training, extensive experiments in the industrial recommendation scenarios show the promise of meta controller in the device-cloud collaboration.
Infer Implicit Contexts in Real-time Online-to-Offline Recommendation
Jul 08, 2019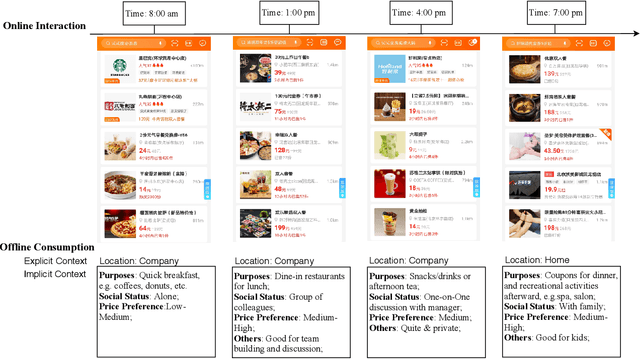
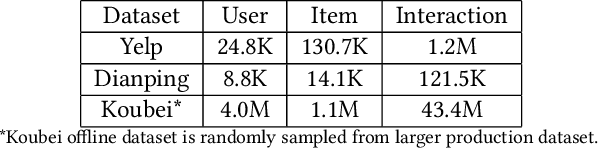
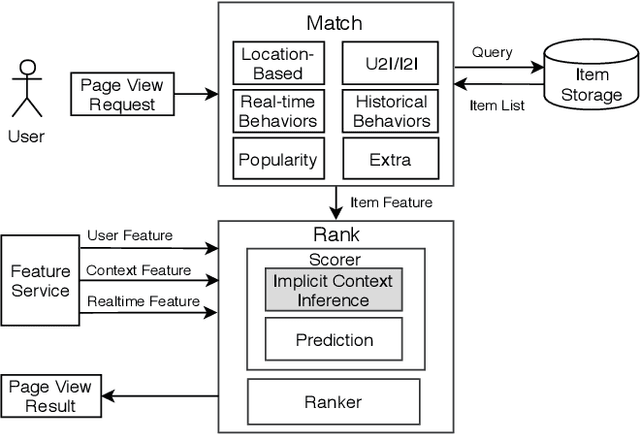
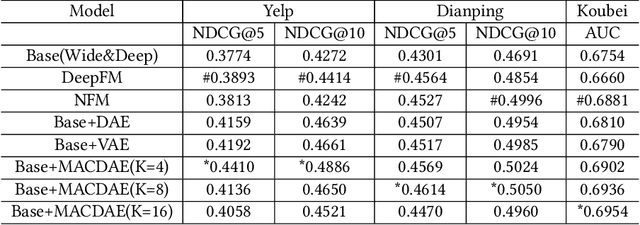
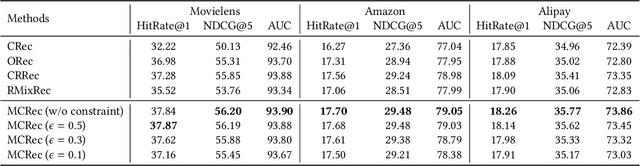
Understanding users' context is essential for successful recommendations, especially for Online-to-Offline (O2O) recommendation, such as Yelp, Groupon, and Koubei. Different from traditional recommendation where individual preference is mostly static, O2O recommendation should be dynamic to capture variation of users' purposes across time and location. However, precisely inferring users' real-time contexts information, especially those implicit ones, is extremely difficult, and it is a central challenge for O2O recommendation. In this paper, we propose a new approach, called Mixture Attentional Constrained Denoise AutoEncoder (MACDAE), to infer implicit contexts and consequently, to improve the quality of real-time O2O recommendation. In MACDAE, we first leverage the interaction among users, items, and explicit contexts to infer users' implicit contexts, then combine the learned implicit-context representation into an end-to-end model to make the recommendation. MACDAE works quite well in the real system. We conducted both offline and online evaluations of the proposed approach. Experiments on several real-world datasets (Yelp, Dianping, and Koubei) show our approach could achieve significant improvements over state-of-the-arts. Furthermore, online A/B test suggests a 2.9% increase for click-through rate and 5.6% improvement for conversion rate in real-world traffic. Our model has been deployed in the product of "Guess You Like" recommendation in Koubei.