 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNetwork Alignment
Apr 15, 2025Complex networks are frequently employed to model physical or virtual complex systems. When certain entities exist across multiple systems simultaneously, unveiling their corresponding relationships across the networks becomes crucial. This problem, known as network alignment, holds significant importance. It enhances our understanding of complex system structures and behaviours, facilitates the validation and extension of theoretical physics research about studying complex systems, and fosters diverse practical applications across various fields. However, due to variations in the structure, characteristics, and properties of complex networks across different fields, the study of network alignment is often isolated within each domain, with even the terminologies and concepts lacking uniformity. This review comprehensively summarizes the latest advancements in network alignment research, focusing on analyzing network alignment characteristics and progress in various domains such as social network analysis, bioinformatics, computational linguistics and privacy protection. It provides a detailed analysis of various methods' implementation principles, processes, and performance differences, including structure consistency-based methods, network embedding-based methods, and graph neural network-based (GNN-based) methods. Additionally, the methods for network alignment under different conditions, such as in attributed networks, heterogeneous networks, directed networks, and dynamic networks, are presented. Furthermore, the challenges and the open issues for future studies are also discussed.
Prompt Packer: Deceiving LLMs through Compositional Instruction with Hidden Attacks
Oct 16, 2023



Recently, Large language models (LLMs) with powerful general capabilities have been increasingly integrated into various Web applications, while undergoing alignment training to ensure that the generated content aligns with user intent and ethics. Unfortunately, they remain the risk of generating harmful content like hate speech and criminal activities in practical applications. Current approaches primarily rely on detecting, collecting, and training against harmful prompts to prevent such risks. However, they typically focused on the "superficial" harmful prompts with a solitary intent, ignoring composite attack instructions with multiple intentions that can easily elicit harmful content in real-world scenarios. In this paper, we introduce an innovative technique for obfuscating harmful instructions: Compositional Instruction Attacks (CIA), which refers to attacking by combination and encapsulation of multiple instructions. CIA hides harmful prompts within instructions of harmless intentions, making it impossible for the model to identify underlying malicious intentions. Furthermore, we implement two transformation methods, known as T-CIA and W-CIA, to automatically disguise harmful instructions as talking or writing tasks, making them appear harmless to LLMs. We evaluated CIA on GPT-4, ChatGPT, and ChatGLM2 with two safety assessment datasets and two harmful prompt datasets. It achieves an attack success rate of 95%+ on safety assessment datasets, and 83%+ for GPT-4, 91%+ for ChatGPT (gpt-3.5-turbo backed) and ChatGLM2-6B on harmful prompt datasets. Our approach reveals the vulnerability of LLMs to such compositional instruction attacks that harbor underlying harmful intentions, contributing significantly to LLM security development. Warning: this paper may contain offensive or upsetting content!
RAUCG: Retrieval-Augmented Unsupervised Counter Narrative Generation for Hate Speech
Oct 09, 2023
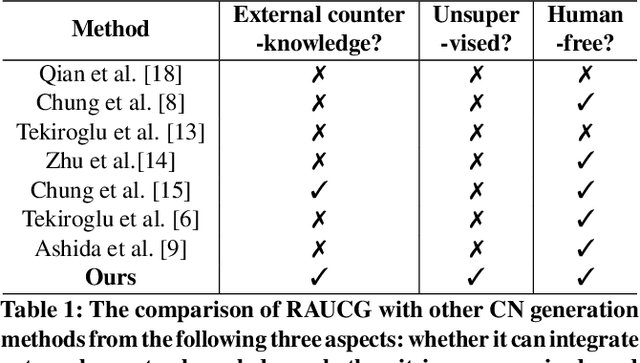

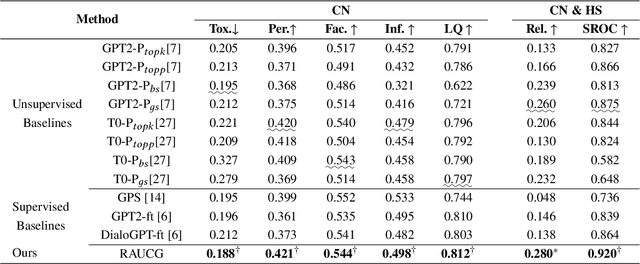
The Counter Narrative (CN) is a promising approach to combat online hate speech (HS) without infringing on freedom of speech. In recent years, there has been a growing interest in automatically generating CNs using natural language generation techniques. However, current automatic CN generation methods mainly rely on expert-authored datasets for training, which are time-consuming and labor-intensive to acquire. Furthermore, these methods cannot directly obtain and extend counter-knowledge from external statistics, facts, or examples. To address these limitations, we propose Retrieval-Augmented Unsupervised Counter Narrative Generation (RAUCG) to automatically expand external counter-knowledge and map it into CNs in an unsupervised paradigm. Specifically, we first introduce an SSF retrieval method to retrieve counter-knowledge from the multiple perspectives of stance consistency, semantic overlap rate, and fitness for HS. Then we design an energy-based decoding mechanism by quantizing knowledge injection, countering and fluency constraints into differentiable functions, to enable the model to build mappings from counter-knowledge to CNs without expert-authored CN data. Lastly, we comprehensively evaluate model performance in terms of language quality, toxicity, persuasiveness, relevance, and success rate of countering HS, etc. Experimental results show that RAUCG outperforms strong baselines on all metrics and exhibits stronger generalization capabilities, achieving significant improvements of +2.0% in relevance and +4.5% in success rate of countering metrics. Moreover, RAUCG enabled GPT2 to outperform T0 in all metrics, despite the latter being approximately eight times larger than the former. Warning: This paper may contain offensive or upsetting content!
ClueGraphSum: Let Key Clues Guide the Cross-Lingual Abstractive Summarization
Mar 09, 2022
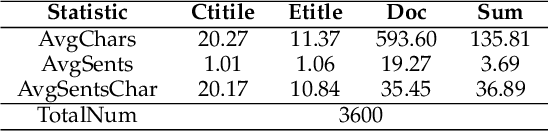
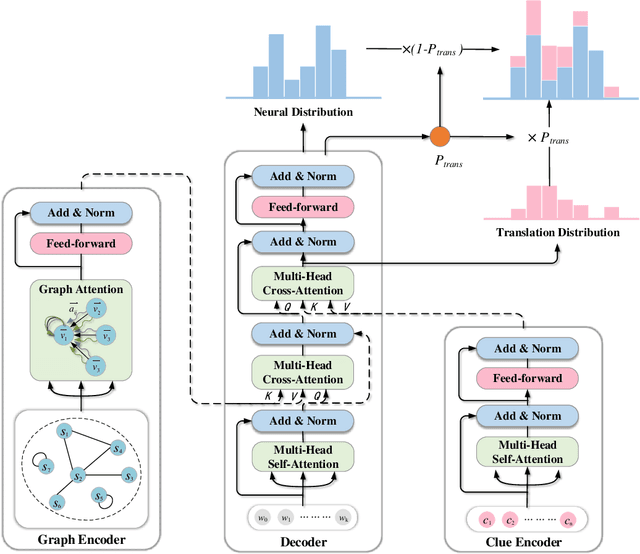
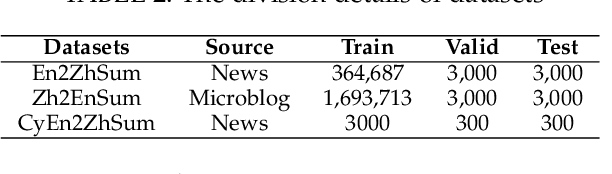
Cross-Lingual Summarization (CLS) is the task to generate a summary in one language for an article in a different language. Previous studies on CLS mainly take pipeline methods or train the end-to-end model using the translated parallel data. However, the quality of generated cross-lingual summaries needs more further efforts to improve, and the model performance has never been evaluated on the hand-written CLS dataset. Therefore, we first propose a clue-guided cross-lingual abstractive summarization method to improve the quality of cross-lingual summaries, and then construct a novel hand-written CLS dataset for evaluation. Specifically, we extract keywords, named entities, etc. of the input article as key clues for summarization and then design a clue-guided algorithm to transform an article into a graph with less noisy sentences. One Graph encoder is built to learn sentence semantics and article structures and one Clue encoder is built to encode and translate key clues, ensuring the information of important parts are reserved in the generated summary. These two encoders are connected by one decoder to directly learn cross-lingual semantics. Experimental results show that our method has stronger robustness for longer inputs and substantially improves the performance over the strong baseline, achieving an improvement of 8.55 ROUGE-1 (English-to-Chinese summarization) and 2.13 MoverScore (Chinese-to-English summarization) scores over the existing SOTA.