 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Long Speech Sequence Modelling for Time-Domain Depression Level Estimation
Jan 05, 2025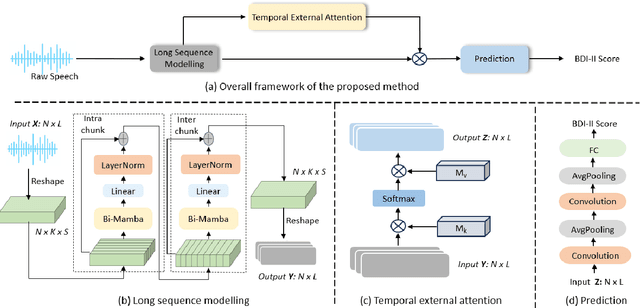
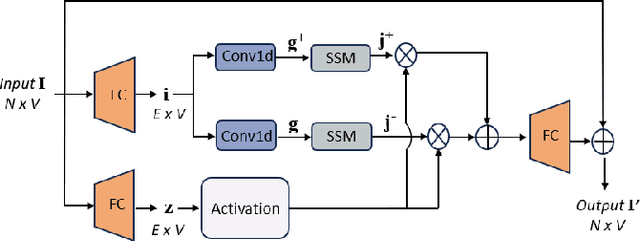
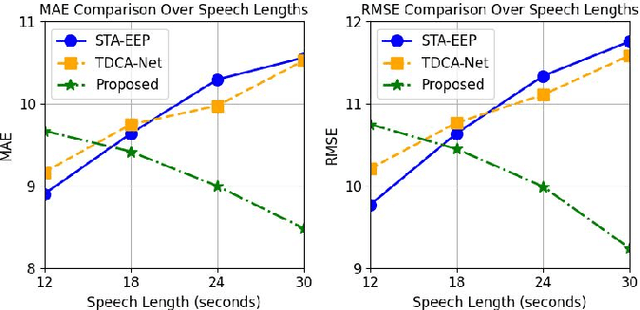
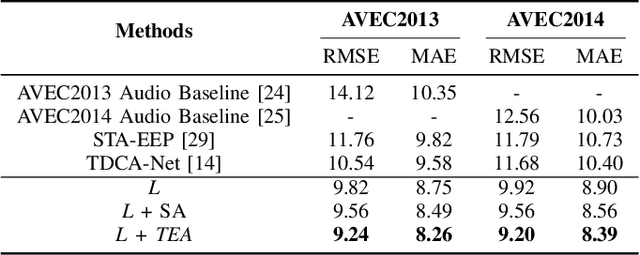
Depression significantly affects emotions, thoughts, and daily activities. Recent research indicates that speech signals contain vital cues about depression, sparking interest in audio-based deep-learning methods for estimating its severity. However, most methods rely on time-frequency representations of speech which have recently been criticized for their limitations due to the loss of information when performing time-frequency projections, e.g. Fourier transform, and Mel-scale transformation. Furthermore, segmenting real-world speech into brief intervals risks losing critical interconnections between recordings. Additionally, such an approach may not adequately reflect real-world scenarios, as individuals with depression often pause and slow down in their conversations and interactions. Building on these observations, we present an efficient method for depression level estimation using long speech signals in the time domain. The proposed method leverages a state space model coupled with the dual-path structure-based long sequence modelling module and temporal external attention module to reconstruct and enhance the detection of depression-related cues hidden in the raw audio waveforms. Experimental results on the AVEC2013 and AVEC2014 datasets show promising results in capturing consequential long-sequence depression cues and demonstrate outstanding performance over the state-of-the-art.
A Frequency-aware Augmentation Network for Mental Disorders Assessment from Audio
Jan 05, 2025



Depression and Attention Deficit Hyperactivity Disorder (ADHD) stand out as the common mental health challenges today. In affective computing, speech signals serve as effective biomarkers for mental disorder assessment. Current research, relying on labor-intensive hand-crafted features or simplistic time-frequency representations, often overlooks critical details by not accounting for the differential impacts of various frequency bands and temporal fluctuations. Therefore, we propose a frequency-aware augmentation network with dynamic convolution for depression and ADHD assessment. In the proposed method, the spectrogram is used as the input feature and adopts a multi-scale convolution to help the network focus on discriminative frequency bands related to mental disorders. A dynamic convolution is also designed to aggregate multiple convolution kernels dynamically based upon their attentions which are input-independent to capture dynamic information. Finally, a feature augmentation block is proposed to enhance the feature representation ability and make full use of the captured information. Experimental results on AVEC 2014 and self-recorded ADHD dataset prove the robustness of our method, an RMSE of 9.23 was attained for estimating depression severity, along with an accuracy of 89.8\% in detecting ADHD.
A Novel Audio-Visual Information Fusion System for Mental Disorders Detection
Sep 03, 2024



Mental disorders are among the foremost contributors to the global healthcare challenge. Research indicates that timely diagnosis and intervention are vital in treating various mental disorders. However, the early somatization symptoms of certain mental disorders may not be immediately evident, often resulting in their oversight and misdiagnosis. Additionally, the traditional diagnosis methods incur high time and cost. Deep learning methods based on fMRI and EEG have improved the efficiency of the mental disorder detection process. However, the cost of the equipment and trained staff are generally huge. Moreover, most systems are only trained for a specific mental disorder and are not general-purpose. Recently, physiological studies have shown that there are some speech and facial-related symptoms in a few mental disorders (e.g., depression and ADHD). In this paper, we focus on the emotional expression features of mental disorders and introduce a multimodal mental disorder diagnosis system based on audio-visual information input. Our proposed system is based on spatial-temporal attention networks and innovative uses a less computationally intensive pre-train audio recognition network to fine-tune the video recognition module for better results. We also apply the unified system for multiple mental disorders (ADHD and depression) for the first time. The proposed system achieves over 80\% accuracy on the real multimodal ADHD dataset and achieves state-of-the-art results on the depression dataset AVEC 2014.
Learning with Noisy Labels for Human Fall Events Classification: Joint Cooperative Training with Trinity Networks
Sep 27, 2023



With the increasing ageing population, fall events classification has drawn much research attention. In the development of deep learning, the quality of data labels is crucial. Most of the datasets are labelled automatically or semi-automatically, and the samples may be mislabeled, which constrains the performance of Deep Neural Networks (DNNs). Recent research on noisy label learning confirms that neural networks first focus on the clean and simple instances and then follow the noisy and hard instances in the training stage. To address the learning with noisy label problem and protect the human subjects' privacy, we propose a simple but effective approach named Joint Cooperative training with Trinity Networks (JoCoT). To mitigate the privacy issue, human skeleton data are used. The robustness and performance of the noisy label learning framework is improved by using the two teacher modules and one student module in the proposed JoCoT. To mitigate the incorrect selections, the predictions from the teacher modules are applied with the consensus-based method to guide the student module training. The performance evaluation on the widely used UP-Fall dataset and comparison with the state-of-the-art, confirms the effectiveness of the proposed JoCoT in high noise rates. Precisely, JoCoT outperforms the state-of-the-art by 5.17% and 3.35% with the averaged pairflip and symmetric noises, respectively.
Position and Orientation-Aware One-Shot Learning for Medical Action Recognition from Signal Data
Sep 27, 2023



In this work, we propose a position and orientation-aware one-shot learning framework for medical action recognition from signal data. The proposed framework comprises two stages and each stage includes signal-level image generation (SIG), cross-attention (CsA), dynamic time warping (DTW) modules and the information fusion between the proposed privacy-preserved position and orientation features. The proposed SIG method aims to transform the raw skeleton data into privacy-preserved features for training. The CsA module is developed to guide the network in reducing medical action recognition bias and more focusing on important human body parts for each specific action, aimed at addressing similar medical action related issues. Moreover, the DTW module is employed to minimize temporal mismatching between instances and further improve model performance. Furthermore, the proposed privacy-preserved orientation-level features are utilized to assist the position-level features in both of the two stages for enhancing medical action recognition performance. Extensive experimental results on the widely-used and well-known NTU RGB+D 60, NTU RGB+D 120, and PKU-MMD datasets all demonstrate the effectiveness of the proposed method, which outperforms the other state-of-the-art methods with general dataset partitioning by 2.7%, 6.2% and 4.1%, respectively.
Skeleton-based action analysis for ADHD diagnosis
Apr 14, 2023



Attention Deficit Hyperactivity Disorder (ADHD) is a common neurobehavioral disorder worldwide. While extensive research has focused on machine learning methods for ADHD diagnosis, most research relies on high-cost equipment, e.g., MRI machine and EEG patch. Therefore, low-cost diagnostic methods based on the action characteristics of ADHD are desired. Skeleton-based action recognition has gained attention due to the action-focused nature and robustness. In this work, we propose a novel ADHD diagnosis system with a skeleton-based action recognition framework, utilizing a real multi-modal ADHD dataset and state-of-the-art detection algorithms. Compared to conventional methods, the proposed method shows cost-efficiency and significant performance improvement, making it more accessible for a broad range of initial ADHD diagnoses. Through the experiment results, the proposed method outperforms the conventional methods in accuracy and AUC. Meanwhile, our method is widely applicable for mass screening.
Two-stage Fall Events Classification with Human Skeleton Data
Aug 25, 2022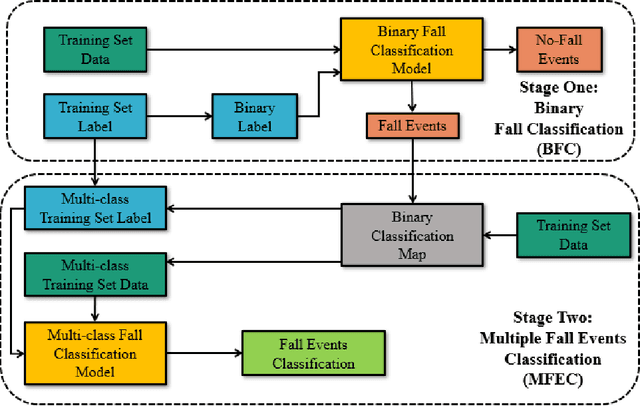
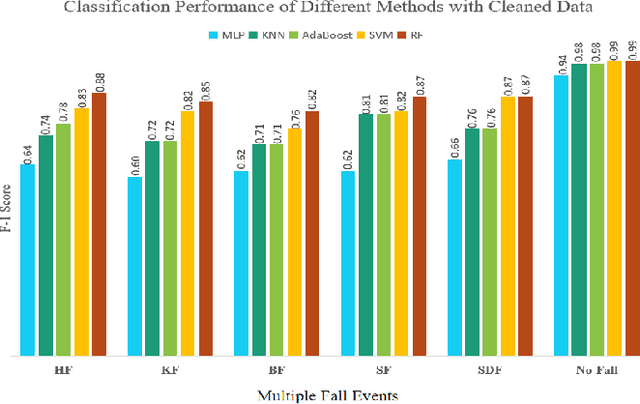


Fall detection and classification become an imper- ative problem for healthcare applications particularity with the increasingly ageing population. Currently, most of the fall clas- sification algorithms provide binary fall or no-fall classification. For better healthcare, it is thus not enough to do binary fall classification but to extend it to multiple fall events classification. In this work, we utilize the privacy mitigating human skeleton data for multiple fall events classification. The skeleton features are extracted from the original RGB images to not only mitigate the personal privacy, but also to reduce the impact of the dynamic illuminations. The proposed fall events classification method is divided into two stages. In the first stage, the model is trained to achieve the binary classification to filter out the no-fall events. Then, in the second stage, the deep neural network (DNN) model is trained to further classify the five types of fall events. In order to confirm the efficiency of the proposed method, the experiments on the UP-Fall dataset outperform the state-of-the-art.
Feature Learning and Ensemble Pre-Tasks Based Self-Supervised Speech Denoising and Dereverberation
Jun 10, 2022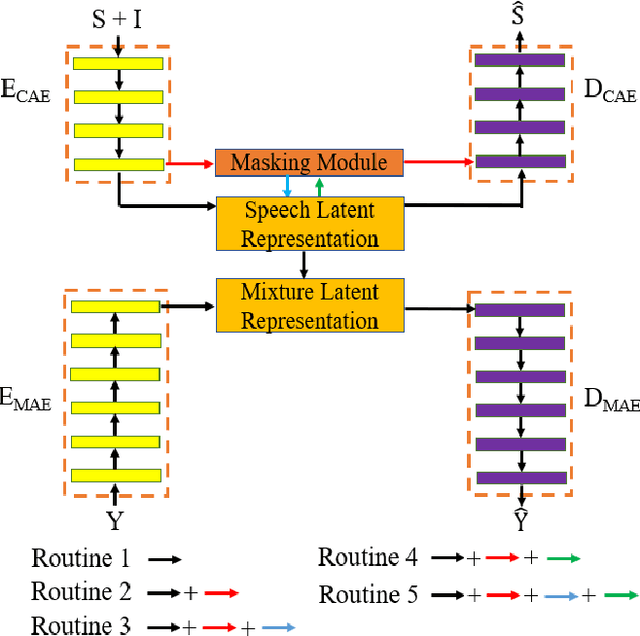
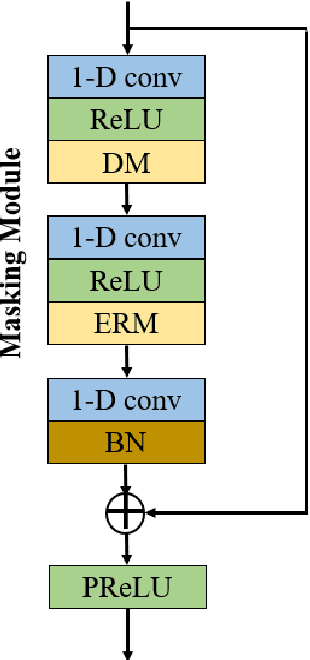
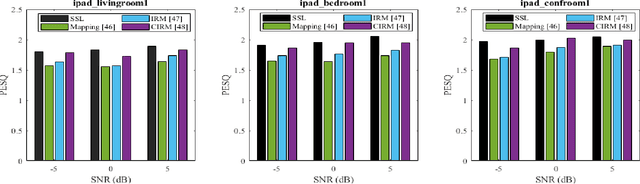
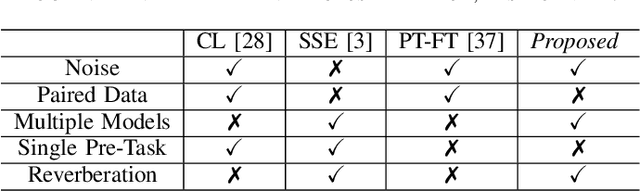
Self-supervised learning (SSL) achieves great success in monaural speech enhancement, while the accuracy of the target speech estimation, particularly for unseen speakers, remains inadequate with existing pre-tasks. As speech signal contains multi-faceted information including speaker identity, paralinguistics, and spoken content, the latent representation for speech enhancement becomes a tough task. In this paper, we study the effectiveness of each feature which is commonly used in speech enhancement and exploit the feature combination in the SSL case. Besides, we propose an ensemble training strategy. The latent representation of the clean speech signal is learned, meanwhile, the dereverberated mask and the estimated ratio mask are exploited to denoise and dereverberate the mixture. The latent representation learning and the masks estimation are considered as two pre-tasks in the training stage. In addition, to study the effectiveness between the pre-tasks, we compare different training routines to train the model and further refine the performance. The NOISEX and DAPS corpora are used to evaluate the efficacy of the proposed method, which also outperforms the state-of-the-art methods.
Self-Supervised Learning based Monaural Speech Enhancement with Multi-Task Pre-Training
Dec 21, 2021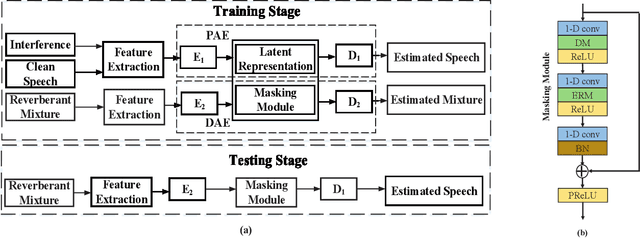
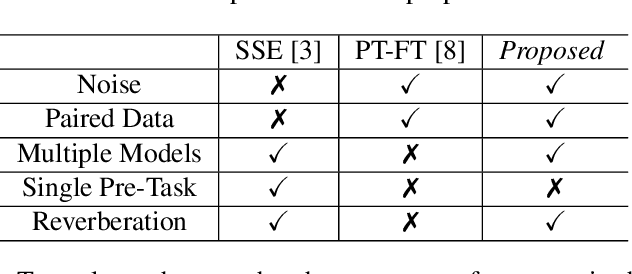

In self-supervised learning, it is challenging to reduce the gap between the enhancement performance on the estimated and target speech signals with existed pre-tasks. In this paper, we propose a multi-task pre-training method to improve the speech enhancement performance with self-supervised learning. Within the pre-training autoencoder (PAE), only a limited set of clean speech signals are required to learn their latent representations. Meanwhile, to solve the limitation of single pre-task, the proposed masking module exploits the dereverberated mask and estimated ratio mask to denoise the mixture as the second pre-task. Different from the PAE, where the target speech signals are estimated, the downstream task autoencoder (DAE) utilizes a large number of unlabeled and unseen reverberant mixtures to generate the estimated mixtures. The trained DAE is shared by the learned representations and masks. Experimental results on a benchmark dataset demonstrate that the proposed method outperforms the state-of-the-art approaches.
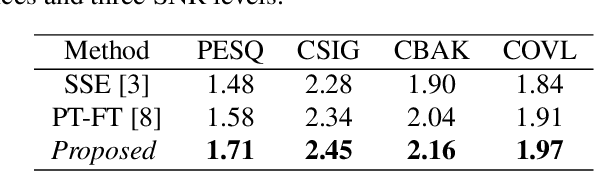
Self-Supervised Learning based Monaural Speech Enhancement with Complex-Cycle-Consistent
Dec 21, 2021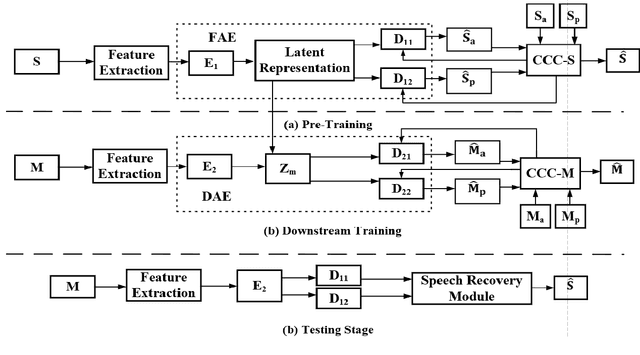
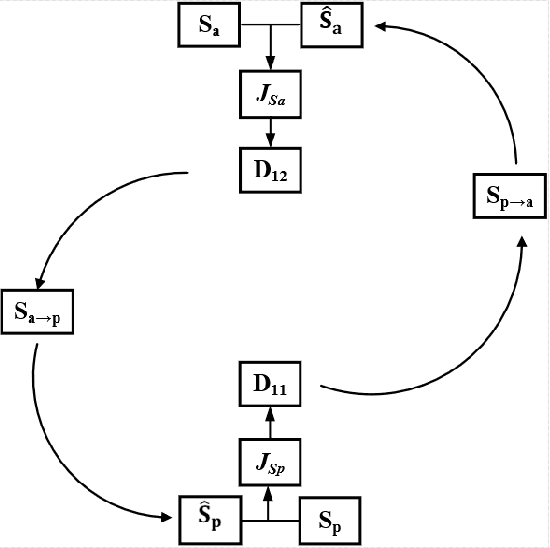
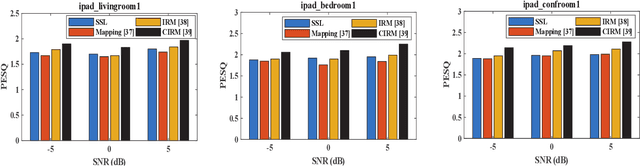

Recently, self-supervised learning (SSL) techniques have been introduced to solve the monaural speech enhancement problem. Due to the lack of using clean phase information, the enhancement performance is limited in most SSL methods. Therefore, in this paper, we propose a phase-aware self-supervised learning based monaural speech enhancement method. The latent representations of both amplitude and phase are studied in two decoders of the foundation autoencoder (FAE) with only a limited set of clean speech signals independently. Then, the downstream autoencoder (DAE) learns a shared latent space between the clean speech and mixture representations with a large number of unseen mixtures. A complex-cycle-consistent (CCC) mechanism is proposed to minimize the reconstruction loss between the amplitude and phase domains. Besides, it is noticed that if the speech features are extracted as the multi-resolution spectra, the desired information distributed in spectra of different scales can be studied to further boost the performance. The NOISEX and DAPS corpora are used to generate mixtures with different interferences to evaluate the efficacy of the proposed method. It is highlighted that the clean speech and mixtures fed in FAE and DAE are not paired. Both ablation and comparison experimental results show that the proposed method clearly outperforms the state-of-the-art approaches.