 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised Learning based Monaural Speech Enhancement with Complex-Cycle-Consistent
Paper and Code
Dec 21, 2021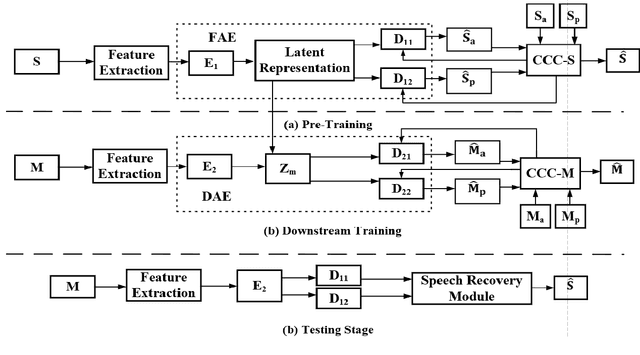
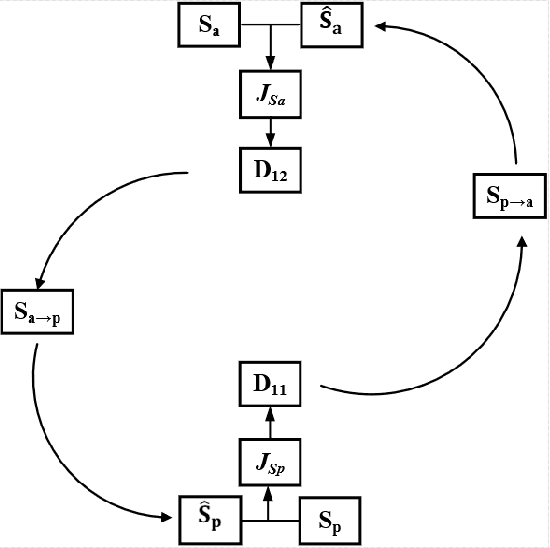
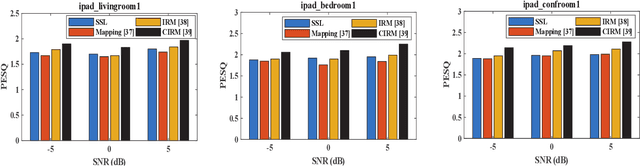

Recently, self-supervised learning (SSL) techniques have been introduced to solve the monaural speech enhancement problem. Due to the lack of using clean phase information, the enhancement performance is limited in most SSL methods. Therefore, in this paper, we propose a phase-aware self-supervised learning based monaural speech enhancement method. The latent representations of both amplitude and phase are studied in two decoders of the foundation autoencoder (FAE) with only a limited set of clean speech signals independently. Then, the downstream autoencoder (DAE) learns a shared latent space between the clean speech and mixture representations with a large number of unseen mixtures. A complex-cycle-consistent (CCC) mechanism is proposed to minimize the reconstruction loss between the amplitude and phase domains. Besides, it is noticed that if the speech features are extracted as the multi-resolution spectra, the desired information distributed in spectra of different scales can be studied to further boost the performance. The NOISEX and DAPS corpora are used to generate mixtures with different interferences to evaluate the efficacy of the proposed method. It is highlighted that the clean speech and mixtures fed in FAE and DAE are not paired. Both ablation and comparison experimental results show that the proposed method clearly outperforms the state-of-the-art approaches.