 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeature Learning and Ensemble Pre-Tasks Based Self-Supervised Speech Denoising and Dereverberation
Jun 10, 2022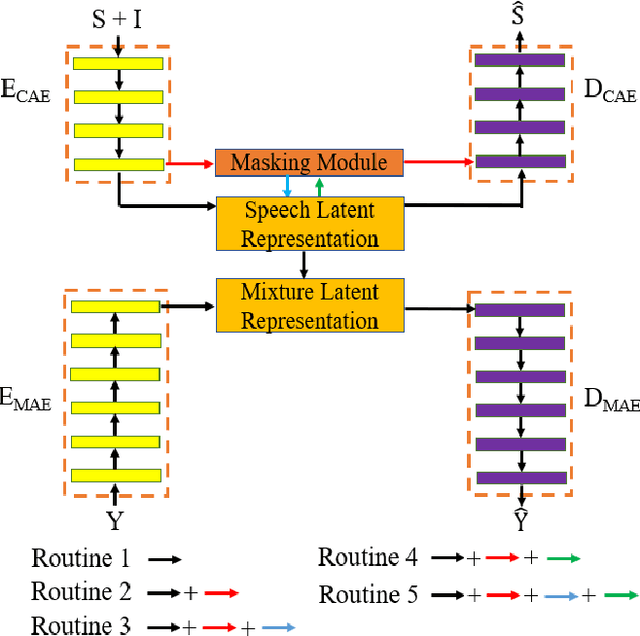
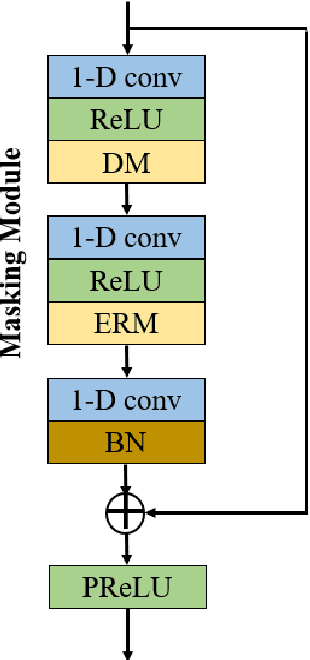
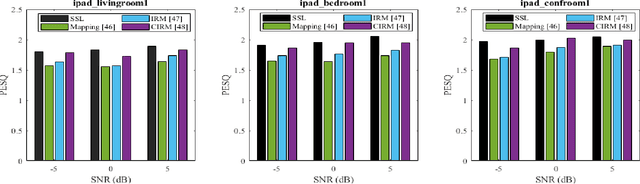
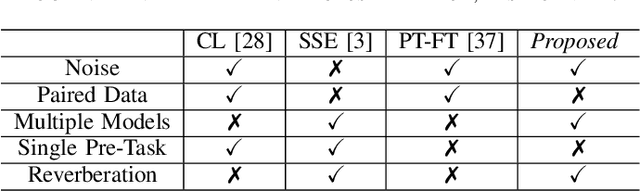
Self-supervised learning (SSL) achieves great success in monaural speech enhancement, while the accuracy of the target speech estimation, particularly for unseen speakers, remains inadequate with existing pre-tasks. As speech signal contains multi-faceted information including speaker identity, paralinguistics, and spoken content, the latent representation for speech enhancement becomes a tough task. In this paper, we study the effectiveness of each feature which is commonly used in speech enhancement and exploit the feature combination in the SSL case. Besides, we propose an ensemble training strategy. The latent representation of the clean speech signal is learned, meanwhile, the dereverberated mask and the estimated ratio mask are exploited to denoise and dereverberate the mixture. The latent representation learning and the masks estimation are considered as two pre-tasks in the training stage. In addition, to study the effectiveness between the pre-tasks, we compare different training routines to train the model and further refine the performance. The NOISEX and DAPS corpora are used to evaluate the efficacy of the proposed method, which also outperforms the state-of-the-art methods.