 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Frequency-aware Augmentation Network for Mental Disorders Assessment from Audio
Jan 05, 2025



Depression and Attention Deficit Hyperactivity Disorder (ADHD) stand out as the common mental health challenges today. In affective computing, speech signals serve as effective biomarkers for mental disorder assessment. Current research, relying on labor-intensive hand-crafted features or simplistic time-frequency representations, often overlooks critical details by not accounting for the differential impacts of various frequency bands and temporal fluctuations. Therefore, we propose a frequency-aware augmentation network with dynamic convolution for depression and ADHD assessment. In the proposed method, the spectrogram is used as the input feature and adopts a multi-scale convolution to help the network focus on discriminative frequency bands related to mental disorders. A dynamic convolution is also designed to aggregate multiple convolution kernels dynamically based upon their attentions which are input-independent to capture dynamic information. Finally, a feature augmentation block is proposed to enhance the feature representation ability and make full use of the captured information. Experimental results on AVEC 2014 and self-recorded ADHD dataset prove the robustness of our method, an RMSE of 9.23 was attained for estimating depression severity, along with an accuracy of 89.8\% in detecting ADHD.
Efficient Long Speech Sequence Modelling for Time-Domain Depression Level Estimation
Jan 05, 2025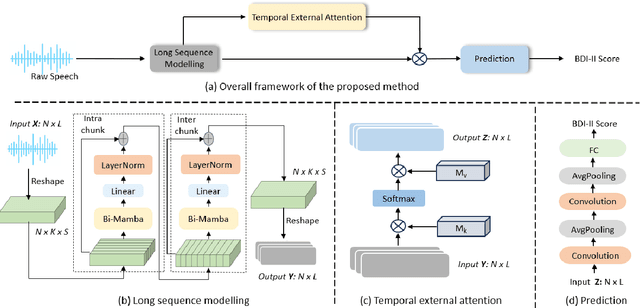
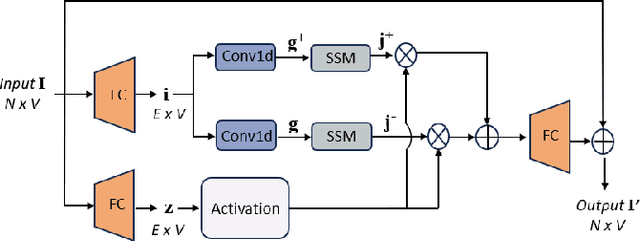
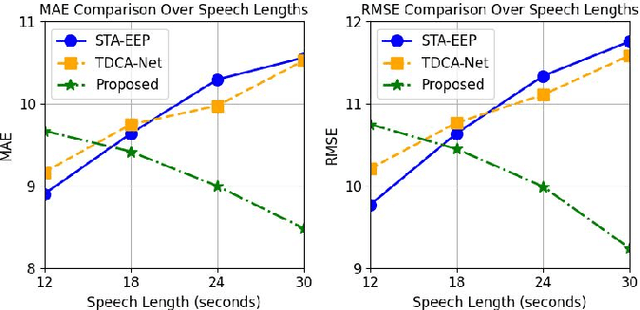
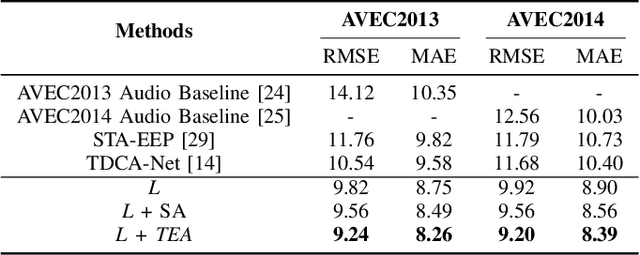
Depression significantly affects emotions, thoughts, and daily activities. Recent research indicates that speech signals contain vital cues about depression, sparking interest in audio-based deep-learning methods for estimating its severity. However, most methods rely on time-frequency representations of speech which have recently been criticized for their limitations due to the loss of information when performing time-frequency projections, e.g. Fourier transform, and Mel-scale transformation. Furthermore, segmenting real-world speech into brief intervals risks losing critical interconnections between recordings. Additionally, such an approach may not adequately reflect real-world scenarios, as individuals with depression often pause and slow down in their conversations and interactions. Building on these observations, we present an efficient method for depression level estimation using long speech signals in the time domain. The proposed method leverages a state space model coupled with the dual-path structure-based long sequence modelling module and temporal external attention module to reconstruct and enhance the detection of depression-related cues hidden in the raw audio waveforms. Experimental results on the AVEC2013 and AVEC2014 datasets show promising results in capturing consequential long-sequence depression cues and demonstrate outstanding performance over the state-of-the-art.
A Novel Audio-Visual Information Fusion System for Mental Disorders Detection
Sep 03, 2024



Mental disorders are among the foremost contributors to the global healthcare challenge. Research indicates that timely diagnosis and intervention are vital in treating various mental disorders. However, the early somatization symptoms of certain mental disorders may not be immediately evident, often resulting in their oversight and misdiagnosis. Additionally, the traditional diagnosis methods incur high time and cost. Deep learning methods based on fMRI and EEG have improved the efficiency of the mental disorder detection process. However, the cost of the equipment and trained staff are generally huge. Moreover, most systems are only trained for a specific mental disorder and are not general-purpose. Recently, physiological studies have shown that there are some speech and facial-related symptoms in a few mental disorders (e.g., depression and ADHD). In this paper, we focus on the emotional expression features of mental disorders and introduce a multimodal mental disorder diagnosis system based on audio-visual information input. Our proposed system is based on spatial-temporal attention networks and innovative uses a less computationally intensive pre-train audio recognition network to fine-tune the video recognition module for better results. We also apply the unified system for multiple mental disorders (ADHD and depression) for the first time. The proposed system achieves over 80\% accuracy on the real multimodal ADHD dataset and achieves state-of-the-art results on the depression dataset AVEC 2014.