 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProgressive Supervision via Label Decomposition: An Long-Term and Large-Scale Wireless Traffic Forecasting Method
Jan 09, 2025



Long-term and Large-scale Wireless Traffic Forecasting (LL-WTF) is pivotal for strategic network management and comprehensive planning on a macro scale. However, LL-WTF poses greater challenges than short-term ones due to the pronounced non-stationarity of extended wireless traffic and the vast number of nodes distributed at the city scale. To cope with this, we propose a Progressive Supervision method based on Label Decomposition (PSLD). Specifically, we first introduce a Random Subgraph Sampling (RSS) algorithm designed to sample a tractable subset from large-scale traffic data, thereby enabling efficient network training. Then, PSLD employs label decomposition to obtain multiple easy-to-learn components, which are learned progressively at shallow layers and combined at deep layers to effectively cope with the non-stationary problem raised by LL-WTF tasks. Finally, we compare the proposed method with various state-of-the-art (SOTA) methods on three large-scale WT datasets. Extensive experimental results demonstrate that the proposed PSLD significantly outperforms existing methods, with an average 2%, 4%, and 11% performance improvement on three WT datasets, respectively. In addition, we built an open source library for WT forecasting (WTFlib) to facilitate related research, which contains numerous SOTA methods and provides a strong benchmark.Experiments can be reproduced through https://github.com/Anoise/WTFlib.
Multi-Head Encoding for Extreme Label Classification
Dec 13, 2024



The number of categories of instances in the real world is normally huge, and each instance may contain multiple labels. To distinguish these massive labels utilizing machine learning, eXtreme Label Classification (XLC) has been established. However, as the number of categories increases, the number of parameters and nonlinear operations in the classifier also rises. This results in a Classifier Computational Overload Problem (CCOP). To address this, we propose a Multi-Head Encoding (MHE) mechanism, which replaces the vanilla classifier with a multi-head classifier. During the training process, MHE decomposes extreme labels into the product of multiple short local labels, with each head trained on these local labels. During testing, the predicted labels can be directly calculated from the local predictions of each head. This reduces the computational load geometrically. Then, according to the characteristics of different XLC tasks, e.g., single-label, multi-label, and model pretraining tasks, three MHE-based implementations, i.e., Multi-Head Product, Multi-Head Cascade, and Multi-Head Sampling, are proposed to more effectively cope with CCOP. Moreover, we theoretically demonstrate that MHE can achieve performance approximately equivalent to that of the vanilla classifier by generalizing the low-rank approximation problem from Frobenius-norm to Cross-Entropy. Experimental results show that the proposed methods achieve state-of-the-art performance while significantly streamlining the training and inference processes of XLC tasks. The source code has been made public at https://github.com/Anoise/MHE.
Act Now: A Novel Online Forecasting Framework for Large-Scale Streaming Data
Nov 28, 2024



In this paper, we find that existing online forecasting methods have the following issues: 1) They do not consider the update frequency of streaming data and directly use labels (future signals) to update the model, leading to information leakage. 2) Eliminating information leakage can exacerbate concept drift and online parameter updates can damage prediction accuracy. 3) Leaving out a validation set cuts off the model's continued learning. 4) Existing GPU devices cannot support online learning of large-scale streaming data. To address the above issues, we propose a novel online learning framework, Act-Now, to improve the online prediction on large-scale streaming data. Firstly, we introduce a Random Subgraph Sampling (RSS) algorithm designed to enable efficient model training. Then, we design a Fast Stream Buffer (FSB) and a Slow Stream Buffer (SSB) to update the model online. FSB updates the model immediately with the consistent pseudo- and partial labels to avoid information leakage. SSB updates the model in parallel using complete labels from earlier times. Further, to address concept drift, we propose a Label Decomposition model (Lade) with statistical and normalization flows. Lade forecasts both the statistical variations and the normalized future values of the data, integrating them through a combiner to produce the final predictions. Finally, we propose to perform online updates on the validation set to ensure the consistency of model learning on streaming data. Extensive experiments demonstrate that the proposed Act-Now framework performs well on large-scale streaming data, with an average 28.4% and 19.5% performance improvement, respectively. Experiments can be reproduced via https://github.com/Anoise/Act-Now.
DistPred: A Distribution-Free Probabilistic Inference Method for Regression and Forecasting
Jun 17, 2024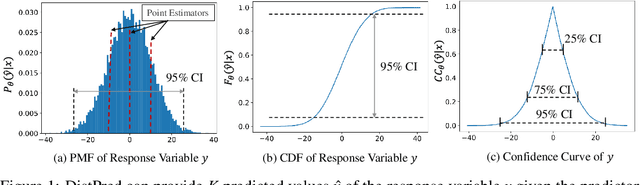
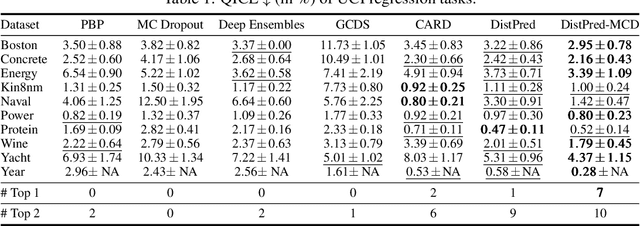

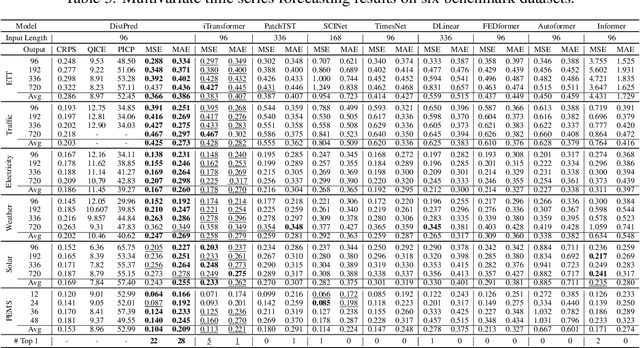
Traditional regression and prediction tasks often only provide deterministic point estimates. To estimate the uncertainty or distribution information of the response variable, methods such as Bayesian inference, model ensembling, or MC Dropout are typically used. These methods either assume that the posterior distribution of samples follows a Gaussian process or require thousands of forward passes for sample generation. We propose a novel approach called DistPred for regression and forecasting tasks, which overcomes the limitations of existing methods while remaining simple and powerful. Specifically, we transform proper scoring rules that measure the discrepancy between the predicted distribution and the target distribution into a differentiable discrete form and use it as a loss function to train the model end-to-end. This allows the model to sample numerous samples in a single forward pass to estimate the potential distribution of the response variable. We have compared our method with several existing approaches on multiple datasets and achieved state-of-the-art performance. Additionally, our method significantly improves computational efficiency. For example, compared to state-of-the-art models, DistPred has a 90x faster inference speed. Experimental results can be reproduced through https://github.com/Anoise/DistPred.
Minusformer: Improving Time Series Forecasting by Progressively Learning Residuals
Feb 04, 2024



In this paper, we find that ubiquitous time series (TS) forecasting models are prone to severe overfitting. To cope with this problem, we embrace a de-redundancy approach to progressively reinstate the intrinsic values of TS for future intervals. Specifically, we renovate the vanilla Transformer by reorienting the information aggregation mechanism from addition to subtraction. Then, we incorporate an auxiliary output branch into each block of the original model to construct a highway leading to the ultimate prediction. The output of subsequent modules in this branch will subtract the previously learned results, enabling the model to learn the residuals of the supervision signal, layer by layer. This designing facilitates the learning-driven implicit progressive decomposition of the input and output streams, empowering the model with heightened versatility, interpretability, and resilience against overfitting. Since all aggregations in the model are minus signs, which is called Minusformer. Extensive experiments demonstrate the proposed method outperform existing state-of-the-art methods, yielding an average performance improvement of 11.9% across various datasets.
Joint Service Caching, Communication and Computing Resource Allocation in Collaborative MEC Systems: A DRL-based Two-timescale Approach
Jul 19, 2023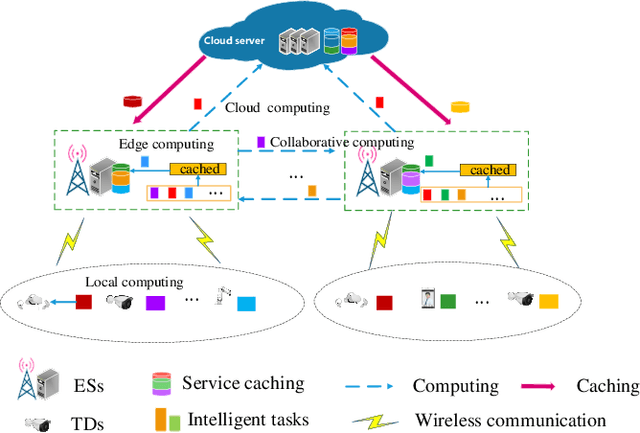



Meeting the strict Quality of Service (QoS) requirements of terminals has imposed a signiffcant challenge on Multiaccess Edge Computing (MEC) systems, due to the limited multidimensional resources. To address this challenge, we propose a collaborative MEC framework that facilitates resource sharing between the edge servers, and with the aim to maximize the long-term QoS and reduce the cache switching cost through joint optimization of service caching, collaborative offfoading, and computation and communication resource allocation. The dual timescale feature and temporal recurrence relationship between service caching and other resource allocation make solving the problem even more challenging. To solve it, we propose a deep reinforcement learning (DRL)-based dual timescale scheme, called DGL-DDPG, which is composed of a short-term genetic algorithm (GA) and a long short-term memory network-based deep deterministic policy gradient (LSTM-DDPG). In doing so, we reformulate the optimization problem as a Markov decision process (MDP) where the small-timescale resource allocation decisions generated by an improved GA are taken as the states and input into a centralized LSTM-DDPG agent to generate the service caching decision for the large-timescale. Simulation results demonstrate that our proposed algorithm outperforms the baseline algorithms in terms of the average QoS and cache switching cost.
Social-Mobility-Aware Joint Communication and Computation Resource Management in NOMA-Enabled Vehicular Networks
Jul 08, 2023



The existing computation and communication (2C) optimization schemes for vehicular edge computing (VEC) networks mainly focus on the physical domain without considering the influence from the social domain. This may greatly limit the potential of task offloading, making it difficult to fully boom the task offloading rate with given power, resulting in low energy efficiency (EE). To address the issue, this letter devotes itself to investigate social-mobility-aware VEC framework and proposes a novel EE-oriented 2C assignment scheme. In doing so, we assume that the task vehicular user (T-VU) can offload computation tasks to the service vehicular user (S-VU) and the road side unit (RSU) by non-orthogonal multiple access (NOMA). An optimization problem is formulated to jointly assign the 2C resources to maximize the system EE, which turns out to be a mixed integer non-convex objective function. To solve the problem, we transform it into separated computation and communication resource allocation subproblems. Dealing with the first subproblem, we propose a social-mobility-aware edge server selection and task splitting algorithm (SM-SSTSA) to achieve edge server selection and task splitting. Then, by solving the second subproblem, the power allocation and spectrum assignment solutions are obtained utilizing a tightening lower bound method and a Kuhn-Munkres algorithm. Finally, we solve the original problem through an iterative method. Simulation results demonstrate the superior EE performance of the proposed scheme.
Does Long-Term Series Forecasting Need Complex Attention and Extra Long Inputs?
Jun 13, 2023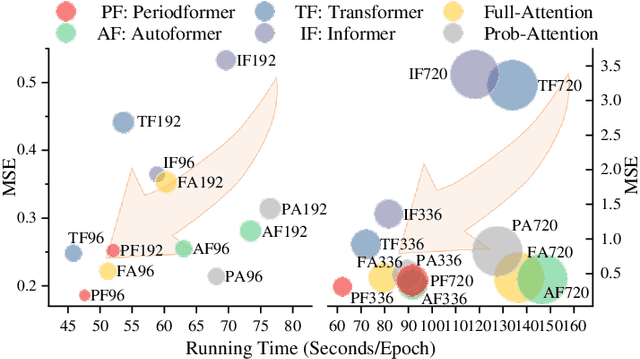
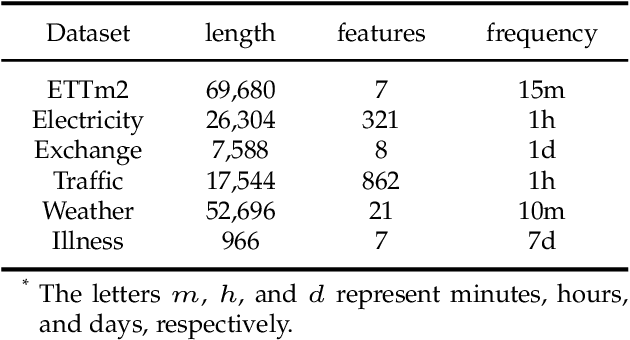
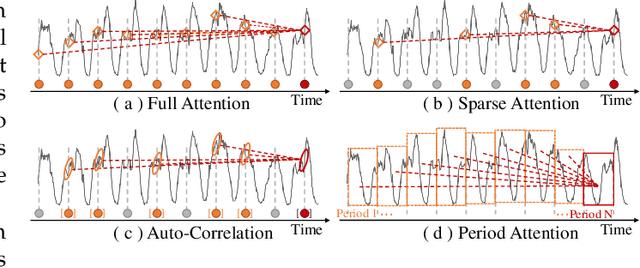
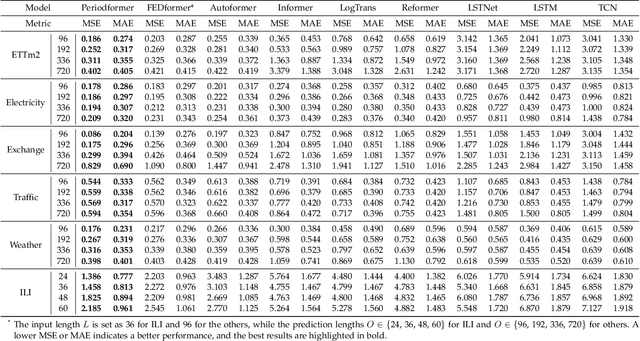
As Transformer-based models have achieved impressive performance on various time series tasks, Long-Term Series Forecasting (LTSF) tasks have also received extensive attention in recent years. However, due to the inherent computational complexity and long sequences demanding of Transformer-based methods, its application on LTSF tasks still has two major issues that need to be further investigated: 1) Whether the sparse attention mechanism designed by these methods actually reduce the running time on real devices; 2) Whether these models need extra long input sequences to guarantee their performance? The answers given in this paper are negative. Therefore, to better copy with these two issues, we design a lightweight Period-Attention mechanism (Periodformer), which renovates the aggregation of long-term subseries via explicit periodicity and short-term subseries via built-in proximity. Meanwhile, a gating mechanism is embedded into Periodformer to regulate the influence of the attention module on the prediction results. Furthermore, to take full advantage of GPUs for fast hyperparameter optimization (e.g., finding the suitable input length), a Multi-GPU Asynchronous parallel algorithm based on Bayesian Optimization (MABO) is presented. MABO allocates a process to each GPU via a queue mechanism, and then creates multiple trials at a time for asynchronous parallel search, which greatly reduces the search time. Compared with the state-of-the-art methods, the prediction error of Periodformer reduced by 13% and 26% for multivariate and univariate forecasting, respectively. In addition, MABO reduces the average search time by 46% while finding better hyperparameters. As a conclusion, this paper indicates that LTSF may not need complex attention and extra long input sequences. The code has been open sourced on Github.
Cooperative Beamforming Design for Multiple RIS-Assisted Communication Systems
Sep 30, 2022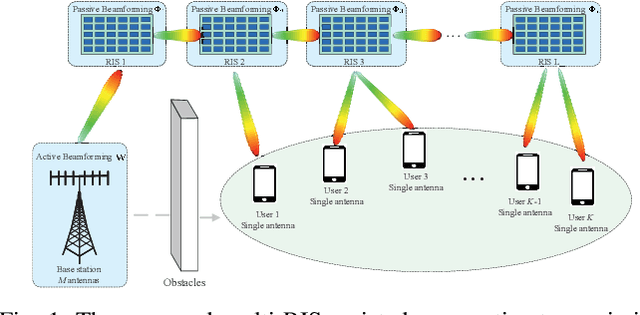
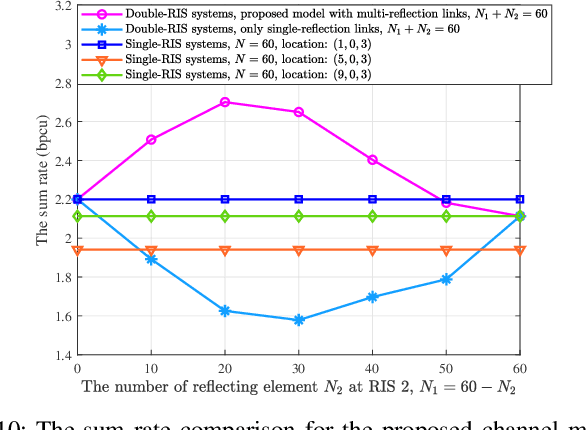

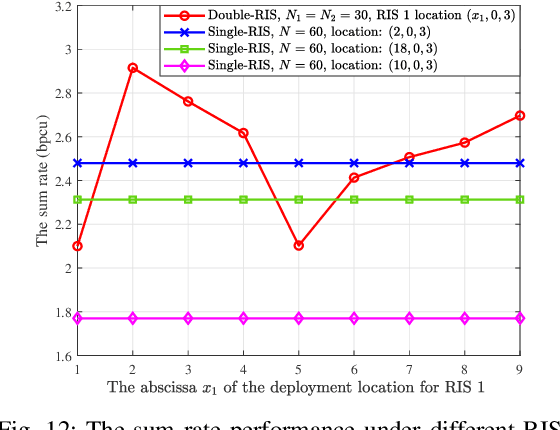
Reconfigurable intelligent surface (RIS) provides a promising way to build programmable wireless transmission environments. Owing to the massive number of controllable reflecting elements on the surface, RIS is capable of providing considerable passive beamforming gains. At present, most related works mainly consider the modeling, design, performance analysis and optimization of single-RIS-assisted systems. Although there are a few of works that investigate multiple RISs individually serving their associated users, the cooperation among multiple RISs is not well considered as yet. To fill the gap, this paper studies a cooperative beamforming design for multi-RIS-assisted communication systems, where multiple RISs are deployed to assist the downlink communications from a base station to its users. To do so, we first model the general channel from the base station to the users for arbitrary number of reflection links. Then, we formulate an optimization problem to maximize the sum rate of all users. Analysis shows that the formulated problem is difficult to solve due to its non-convexity and the interactions among the decision variables. To solve it effectively, we first decouple the problem into three disjoint subproblems. Then, by introducing appropriate auxiliary variables, we derive the closed-form expressions for the decision variables and propose a low-complexity cooperative beamforming algorithm. Simulation results have verified the effectiveness of the proposed algorithm through comparison with various baseline methods. Furthermore, these results also unveil that, for the sum rate maximization, distributing the reflecting elements among multiple RISs is superior to deploying them at one single RIS.
Robust Beamforming and Rate-Splitting Design for Next Generation Ultra-Reliable and Low-Latency Communications
Sep 19, 2022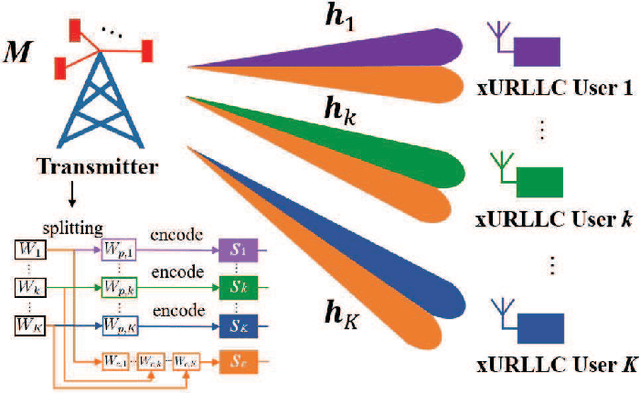
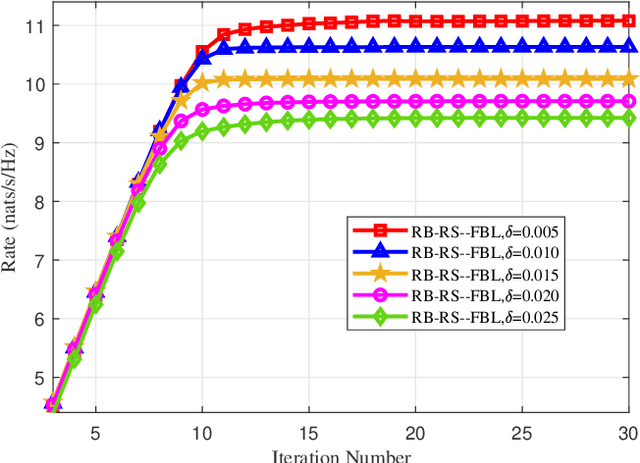


The next generation ultra-reliable and low-latency communications (xURLLC) need novel design to provide satisfactory services to the emerging mission-critical applications. To improve the spectrum efficiency and enhance the robustness of xURLLC, this paper proposes a robust beamforming and rate-splitting design in the finite blocklength (FBL) regime for downlink multi-user multi-antenna xURLLC systems. In the design, adaptive rate-splitting is introduced to flexibly handle the complex inter-user interference and thus improve the spectrum efficiency. Taking the imperfection of the channel state information at the transmitter (CSIT) into consideration, a max-min user rate problem is formulated to optimize the common and private beamforming vectors and the rate-splitting vector under the premise of ensuring the requirements of transmission latency and reliability of all the users. The optimization problem is intractable due to the non-convexity of the constraint set and the infinite constraints caused by CSIT uncertainties. To solve it, we convert the infinite constraints into finite ones by the S-Procedure method and transform the original problem into a difference of convex (DC) programming. A constrained concave convex procedure (CCCP) and the Gaussian randomization based iterative algorithm is proposed to obtain a local minimum. Simulation results confirm the convergence, robustness and effectiveness of the proposed robust beamforming and rate-splitting design in the FBL regime. It is also shown that the proposed robust design achieves considerable performance gain in the worst user rate compared with existing transmission schemes under various blocklength and block error rate requirements.