 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Forecast After the Forecast: A Post-Processing Shift in Time Series
Jan 28, 2026Time series forecasting has long been dominated by advances in model architecture, with recent progress driven by deep learning and hybrid statistical techniques. However, as forecasting models approach diminishing returns in accuracy, a critical yet underexplored opportunity emerges: the strategic use of post-processing. In this paper, we address the last-mile gap in time-series forecasting, which is to improve accuracy and uncertainty without retraining or modifying a deployed backbone. We propose $δ$-Adapter, a lightweight, architecture-agnostic way to boost deployed time series forecasters without retraining. $δ$-Adapter learns tiny, bounded modules at two interfaces: input nudging (soft edits to covariates) and output residual correction. We provide local descent guarantees, $O(δ)$ drift bounds, and compositional stability for combined adapters. Meanwhile, it can act as a feature selector by learning a sparse, horizon-aware mask over inputs to select important features, thereby improving interpretability. In addition, it can also be used as a distribution calibrator to measure uncertainty. Thus, we introduce a Quantile Calibrator and a Conformal Corrector that together deliver calibrated, personalized intervals with finite-sample coverage. Our experiments across diverse backbones and datasets show that $δ$-Adapter improves accuracy and calibration with negligible compute and no interface changes.
* 30 Pages
DeepBooTS: Dual-Stream Residual Boosting for Drift-Resilient Time-Series Forecasting
Nov 10, 2025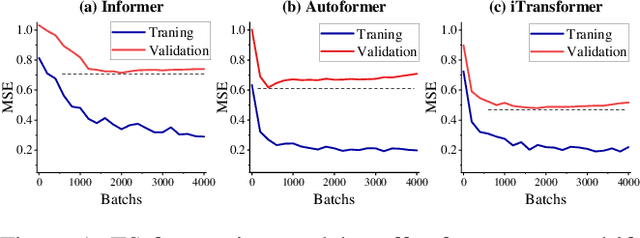
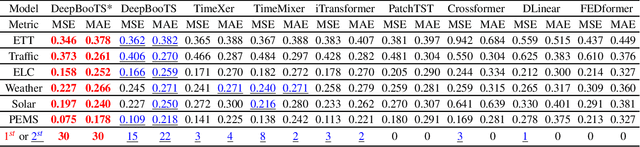
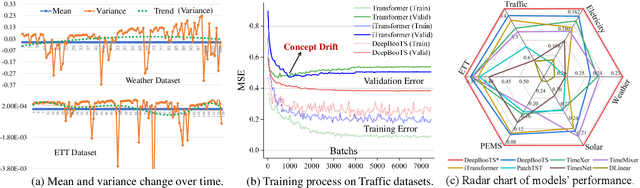
Time-Series (TS) exhibits pronounced non-stationarity. Consequently, most forecasting methods display compromised robustness to concept drift, despite the prevalent application of instance normalization. We tackle this challenge by first analysing concept drift through a bias-variance lens and proving that weighted ensemble reduces variance without increasing bias. These insights motivate DeepBooTS, a novel end-to-end dual-stream residual-decreasing boosting method that progressively reconstructs the intrinsic signal. In our design, each block of a deep model becomes an ensemble of learners with an auxiliary output branch forming a highway to the final prediction. The block-wise outputs correct the residuals of previous blocks, leading to a learning-driven decomposition of both inputs and targets. This method enhances versatility and interpretability while substantially improving robustness to concept drift. Extensive experiments, including those on large-scale datasets, show that the proposed method outperforms existing methods by a large margin, yielding an average performance improvement of 15.8% across various datasets, establishing a new benchmark for TS forecasting.
Progressive Supervision via Label Decomposition: An Long-Term and Large-Scale Wireless Traffic Forecasting Method
Jan 09, 2025



Long-term and Large-scale Wireless Traffic Forecasting (LL-WTF) is pivotal for strategic network management and comprehensive planning on a macro scale. However, LL-WTF poses greater challenges than short-term ones due to the pronounced non-stationarity of extended wireless traffic and the vast number of nodes distributed at the city scale. To cope with this, we propose a Progressive Supervision method based on Label Decomposition (PSLD). Specifically, we first introduce a Random Subgraph Sampling (RSS) algorithm designed to sample a tractable subset from large-scale traffic data, thereby enabling efficient network training. Then, PSLD employs label decomposition to obtain multiple easy-to-learn components, which are learned progressively at shallow layers and combined at deep layers to effectively cope with the non-stationary problem raised by LL-WTF tasks. Finally, we compare the proposed method with various state-of-the-art (SOTA) methods on three large-scale WT datasets. Extensive experimental results demonstrate that the proposed PSLD significantly outperforms existing methods, with an average 2%, 4%, and 11% performance improvement on three WT datasets, respectively. In addition, we built an open source library for WT forecasting (WTFlib) to facilitate related research, which contains numerous SOTA methods and provides a strong benchmark.Experiments can be reproduced through https://github.com/Anoise/WTFlib.
Multi-Head Encoding for Extreme Label Classification
Dec 13, 2024



The number of categories of instances in the real world is normally huge, and each instance may contain multiple labels. To distinguish these massive labels utilizing machine learning, eXtreme Label Classification (XLC) has been established. However, as the number of categories increases, the number of parameters and nonlinear operations in the classifier also rises. This results in a Classifier Computational Overload Problem (CCOP). To address this, we propose a Multi-Head Encoding (MHE) mechanism, which replaces the vanilla classifier with a multi-head classifier. During the training process, MHE decomposes extreme labels into the product of multiple short local labels, with each head trained on these local labels. During testing, the predicted labels can be directly calculated from the local predictions of each head. This reduces the computational load geometrically. Then, according to the characteristics of different XLC tasks, e.g., single-label, multi-label, and model pretraining tasks, three MHE-based implementations, i.e., Multi-Head Product, Multi-Head Cascade, and Multi-Head Sampling, are proposed to more effectively cope with CCOP. Moreover, we theoretically demonstrate that MHE can achieve performance approximately equivalent to that of the vanilla classifier by generalizing the low-rank approximation problem from Frobenius-norm to Cross-Entropy. Experimental results show that the proposed methods achieve state-of-the-art performance while significantly streamlining the training and inference processes of XLC tasks. The source code has been made public at https://github.com/Anoise/MHE.
Act Now: A Novel Online Forecasting Framework for Large-Scale Streaming Data
Nov 28, 2024



In this paper, we find that existing online forecasting methods have the following issues: 1) They do not consider the update frequency of streaming data and directly use labels (future signals) to update the model, leading to information leakage. 2) Eliminating information leakage can exacerbate concept drift and online parameter updates can damage prediction accuracy. 3) Leaving out a validation set cuts off the model's continued learning. 4) Existing GPU devices cannot support online learning of large-scale streaming data. To address the above issues, we propose a novel online learning framework, Act-Now, to improve the online prediction on large-scale streaming data. Firstly, we introduce a Random Subgraph Sampling (RSS) algorithm designed to enable efficient model training. Then, we design a Fast Stream Buffer (FSB) and a Slow Stream Buffer (SSB) to update the model online. FSB updates the model immediately with the consistent pseudo- and partial labels to avoid information leakage. SSB updates the model in parallel using complete labels from earlier times. Further, to address concept drift, we propose a Label Decomposition model (Lade) with statistical and normalization flows. Lade forecasts both the statistical variations and the normalized future values of the data, integrating them through a combiner to produce the final predictions. Finally, we propose to perform online updates on the validation set to ensure the consistency of model learning on streaming data. Extensive experiments demonstrate that the proposed Act-Now framework performs well on large-scale streaming data, with an average 28.4% and 19.5% performance improvement, respectively. Experiments can be reproduced via https://github.com/Anoise/Act-Now.
DistPred: A Distribution-Free Probabilistic Inference Method for Regression and Forecasting
Jun 17, 2024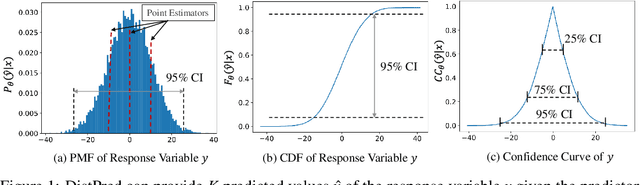
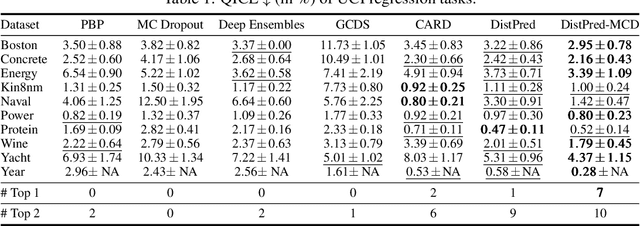

Traditional regression and prediction tasks often only provide deterministic point estimates. To estimate the uncertainty or distribution information of the response variable, methods such as Bayesian inference, model ensembling, or MC Dropout are typically used. These methods either assume that the posterior distribution of samples follows a Gaussian process or require thousands of forward passes for sample generation. We propose a novel approach called DistPred for regression and forecasting tasks, which overcomes the limitations of existing methods while remaining simple and powerful. Specifically, we transform proper scoring rules that measure the discrepancy between the predicted distribution and the target distribution into a differentiable discrete form and use it as a loss function to train the model end-to-end. This allows the model to sample numerous samples in a single forward pass to estimate the potential distribution of the response variable. We have compared our method with several existing approaches on multiple datasets and achieved state-of-the-art performance. Additionally, our method significantly improves computational efficiency. For example, compared to state-of-the-art models, DistPred has a 90x faster inference speed. Experimental results can be reproduced through https://github.com/Anoise/DistPred.
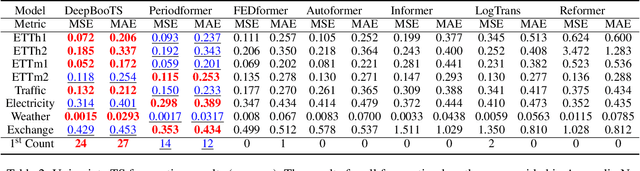
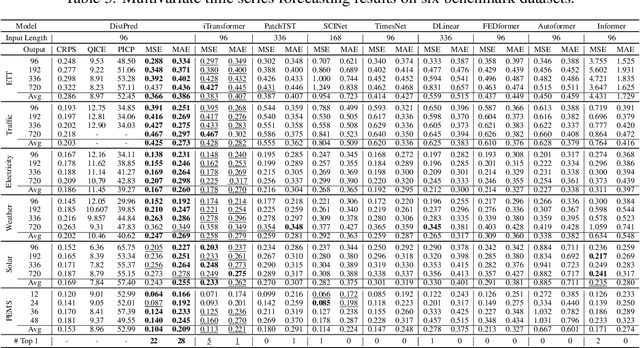
Minusformer: Improving Time Series Forecasting by Progressively Learning Residuals
Feb 04, 2024



In this paper, we find that ubiquitous time series (TS) forecasting models are prone to severe overfitting. To cope with this problem, we embrace a de-redundancy approach to progressively reinstate the intrinsic values of TS for future intervals. Specifically, we renovate the vanilla Transformer by reorienting the information aggregation mechanism from addition to subtraction. Then, we incorporate an auxiliary output branch into each block of the original model to construct a highway leading to the ultimate prediction. The output of subsequent modules in this branch will subtract the previously learned results, enabling the model to learn the residuals of the supervision signal, layer by layer. This designing facilitates the learning-driven implicit progressive decomposition of the input and output streams, empowering the model with heightened versatility, interpretability, and resilience against overfitting. Since all aggregations in the model are minus signs, which is called Minusformer. Extensive experiments demonstrate the proposed method outperform existing state-of-the-art methods, yielding an average performance improvement of 11.9% across various datasets.
Does Long-Term Series Forecasting Need Complex Attention and Extra Long Inputs?
Jun 13, 2023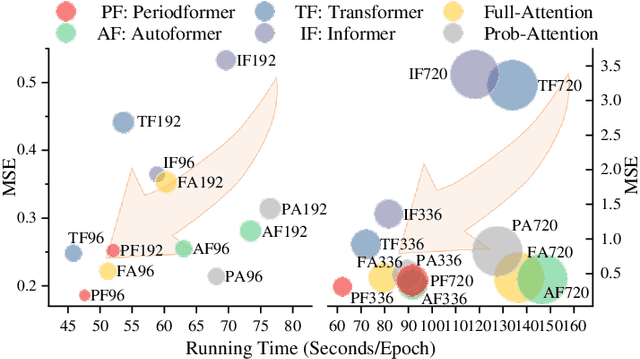
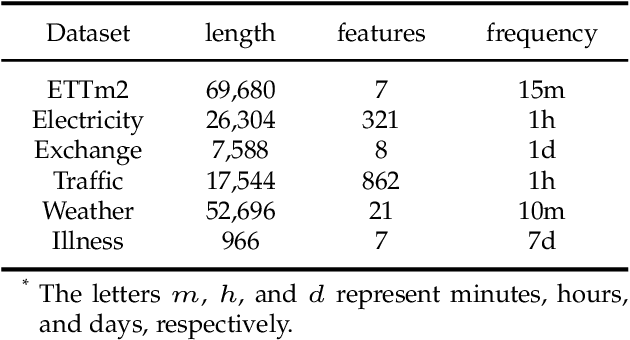
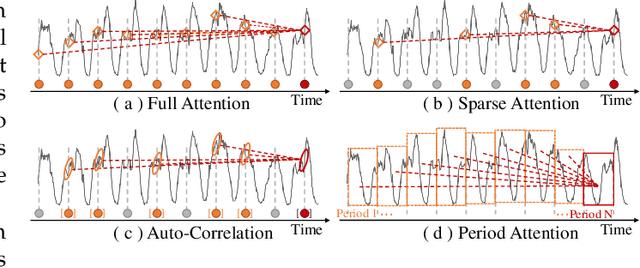
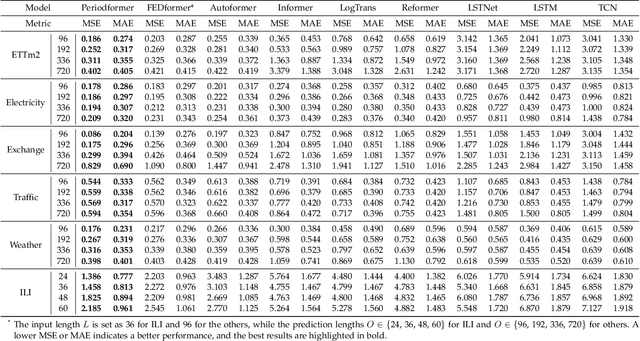
As Transformer-based models have achieved impressive performance on various time series tasks, Long-Term Series Forecasting (LTSF) tasks have also received extensive attention in recent years. However, due to the inherent computational complexity and long sequences demanding of Transformer-based methods, its application on LTSF tasks still has two major issues that need to be further investigated: 1) Whether the sparse attention mechanism designed by these methods actually reduce the running time on real devices; 2) Whether these models need extra long input sequences to guarantee their performance? The answers given in this paper are negative. Therefore, to better copy with these two issues, we design a lightweight Period-Attention mechanism (Periodformer), which renovates the aggregation of long-term subseries via explicit periodicity and short-term subseries via built-in proximity. Meanwhile, a gating mechanism is embedded into Periodformer to regulate the influence of the attention module on the prediction results. Furthermore, to take full advantage of GPUs for fast hyperparameter optimization (e.g., finding the suitable input length), a Multi-GPU Asynchronous parallel algorithm based on Bayesian Optimization (MABO) is presented. MABO allocates a process to each GPU via a queue mechanism, and then creates multiple trials at a time for asynchronous parallel search, which greatly reduces the search time. Compared with the state-of-the-art methods, the prediction error of Periodformer reduced by 13% and 26% for multivariate and univariate forecasting, respectively. In addition, MABO reduces the average search time by 46% while finding better hyperparameters. As a conclusion, this paper indicates that LTSF may not need complex attention and extra long input sequences. The code has been open sourced on Github.