 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoes Long-Term Series Forecasting Need Complex Attention and Extra Long Inputs?
Paper and Code
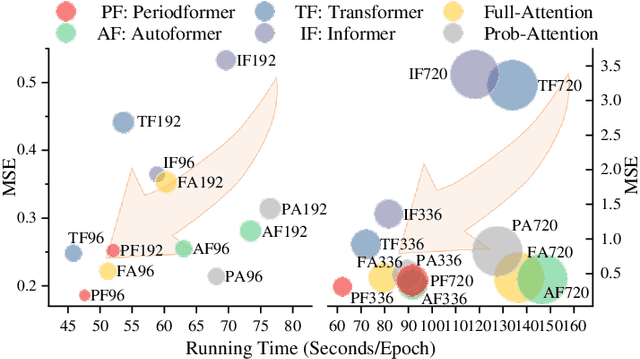
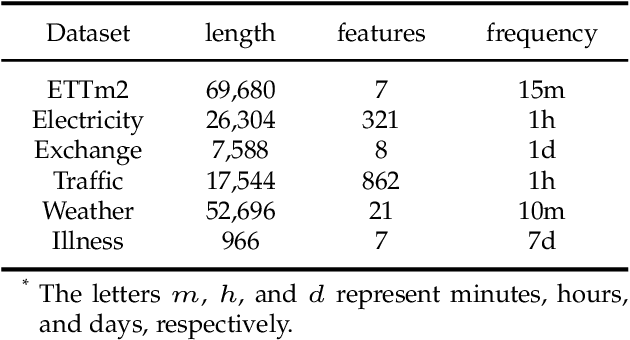
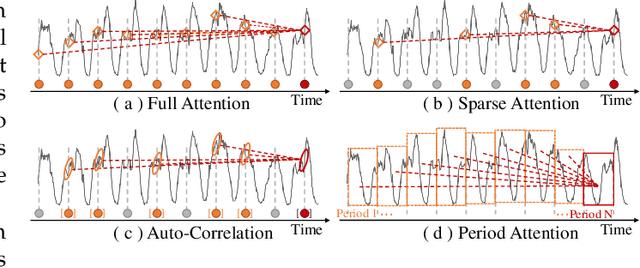
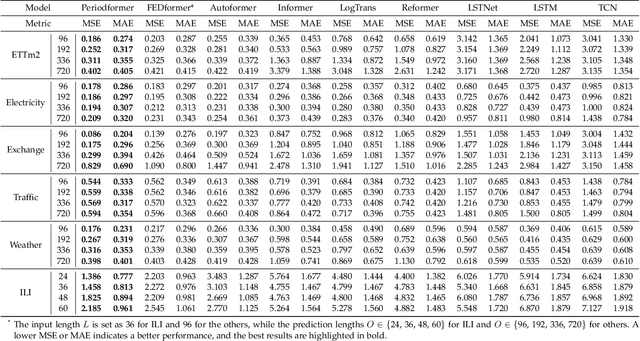
As Transformer-based models have achieved impressive performance on various time series tasks, Long-Term Series Forecasting (LTSF) tasks have also received extensive attention in recent years. However, due to the inherent computational complexity and long sequences demanding of Transformer-based methods, its application on LTSF tasks still has two major issues that need to be further investigated: 1) Whether the sparse attention mechanism designed by these methods actually reduce the running time on real devices; 2) Whether these models need extra long input sequences to guarantee their performance? The answers given in this paper are negative. Therefore, to better copy with these two issues, we design a lightweight Period-Attention mechanism (Periodformer), which renovates the aggregation of long-term subseries via explicit periodicity and short-term subseries via built-in proximity. Meanwhile, a gating mechanism is embedded into Periodformer to regulate the influence of the attention module on the prediction results. Furthermore, to take full advantage of GPUs for fast hyperparameter optimization (e.g., finding the suitable input length), a Multi-GPU Asynchronous parallel algorithm based on Bayesian Optimization (MABO) is presented. MABO allocates a process to each GPU via a queue mechanism, and then creates multiple trials at a time for asynchronous parallel search, which greatly reduces the search time. Compared with the state-of-the-art methods, the prediction error of Periodformer reduced by 13% and 26% for multivariate and univariate forecasting, respectively. In addition, MABO reduces the average search time by 46% while finding better hyperparameters. As a conclusion, this paper indicates that LTSF may not need complex attention and extra long input sequences. The code has been open sourced on Github.