 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHallE-Switch: Rethinking and Controlling Object Existence Hallucinations in Large Vision Language Models for Detailed Caption
Oct 03, 2023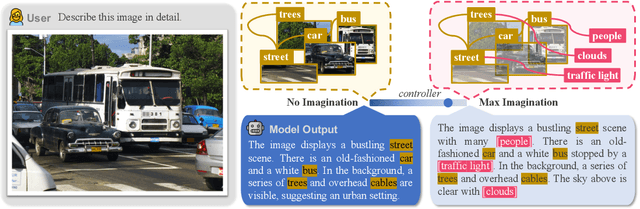
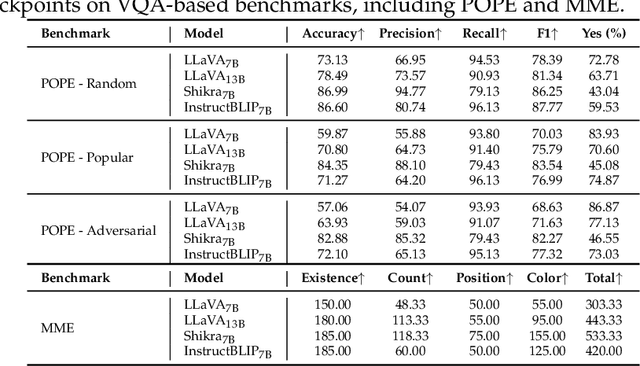

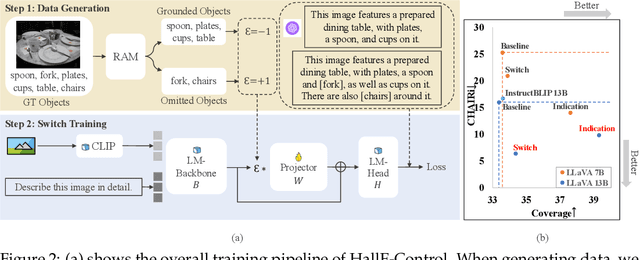
Current large vision-language models (LVLMs) achieve remarkable progress, yet there remains significant uncertainty regarding their ability to accurately apprehend visual details, that is, in performing detailed captioning. To address this, we introduce \textit{CCEval}, a GPT-4 assisted evaluation method tailored for detailed captioning. Interestingly, while LVLMs demonstrate minimal object existence hallucination in existing VQA benchmarks, our proposed evaluation reveals continued susceptibility to such hallucinations. In this paper, we make the first attempt to investigate and attribute such hallucinations, including image resolution, the language decoder size, and instruction data amount, quality, granularity. Our findings underscore the unwarranted inference when the language description includes details at a finer object granularity than what the vision module can ground or verify, thus inducing hallucination. To control such hallucinations, we further attribute the reliability of captioning to contextual knowledge (involving only contextually grounded objects) and parametric knowledge (containing inferred objects by the model). Thus, we introduce $\textit{HallE-Switch}$, a controllable LVLM in terms of $\textbf{Hall}$ucination in object $\textbf{E}$xistence. HallE-Switch can condition the captioning to shift between (i) exclusively depicting contextual knowledge for grounded objects and (ii) blending it with parametric knowledge to imagine inferred objects. Our method reduces hallucination by 44% compared to LLaVA$_{7B}$ and maintains the same object coverage.
Incorporating Causal Analysis into Diversified and Logical Response Generation
Oct 11, 2022
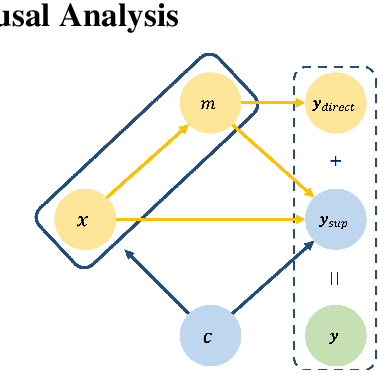
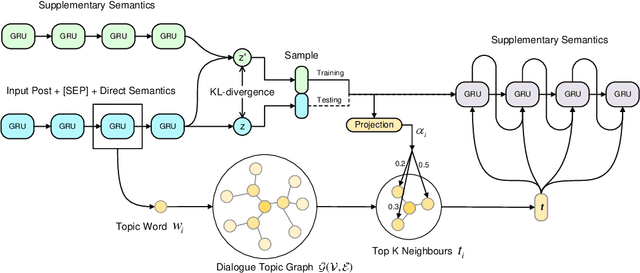
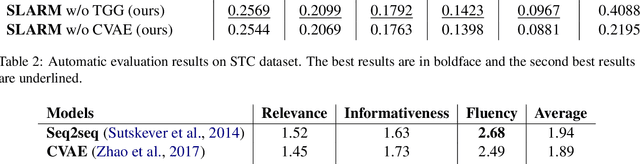
Although the Conditional Variational AutoEncoder (CVAE) model can generate more diversified responses than the traditional Seq2Seq model, the responses often have low relevance with the input words or are illogical with the question. A causal analysis is carried out to study the reasons behind, and a methodology of searching for the mediators and mitigating the confounding bias in dialogues is provided. Specifically, we propose to predict the mediators to preserve relevant information and auto-regressively incorporate the mediators into generating process. Besides, a dynamic topic graph guided conditional variational autoencoder (TGG-CVAE) model is utilized to complement the semantic space and reduce the confounding bias in responses. Extensive experiments demonstrate that the proposed model is able to generate both relevant and informative responses, and outperforms the state-of-the-art in terms of automatic metrics and human evaluations.
Hierarchical Capsule Prediction Network for Marketing Campaigns Effect
Aug 22, 2022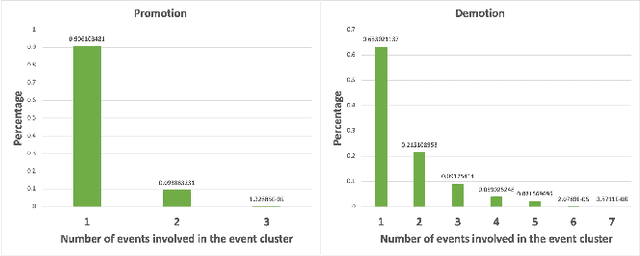
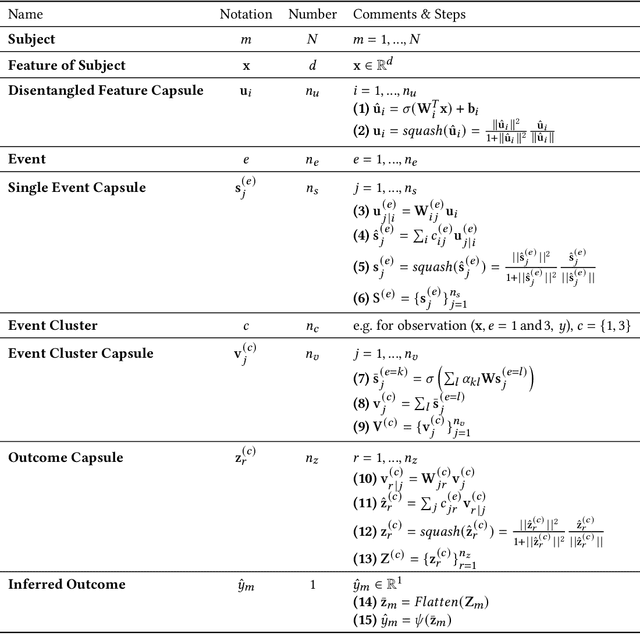
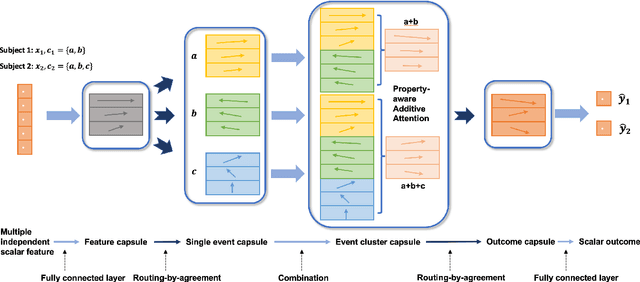
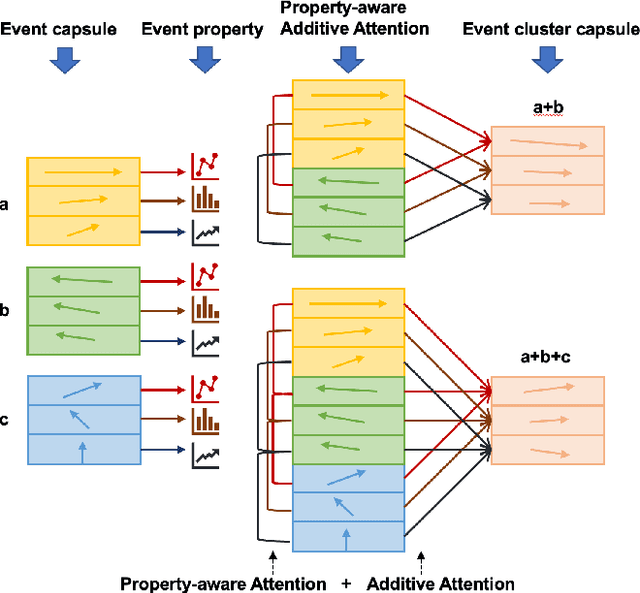
Marketing campaigns are a set of strategic activities that can promote a business's goal. The effect prediction for marketing campaigns in a real industrial scenario is very complex and challenging due to the fact that prior knowledge is often learned from observation data, without any intervention for the marketing campaign. Furthermore, each subject is always under the interference of several marketing campaigns simultaneously. Therefore, we cannot easily parse and evaluate the effect of a single marketing campaign. To the best of our knowledge, there are currently no effective methodologies to solve such a problem, i.e., modeling an individual-level prediction task based on a hierarchical structure with multiple intertwined events. In this paper, we provide an in-depth analysis of the underlying parse tree-like structure involved in the effect prediction task and we further establish a Hierarchical Capsule Prediction Network (HapNet) for predicting the effects of marketing campaigns. Extensive results based on both the synthetic data and real data demonstrate the superiority of our model over the state-of-the-art methods and show remarkable practicability in real industrial applications.
Cross-Lingual Phrase Retrieval
Apr 19, 2022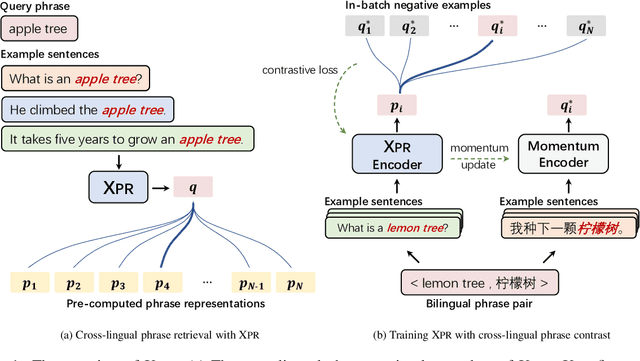


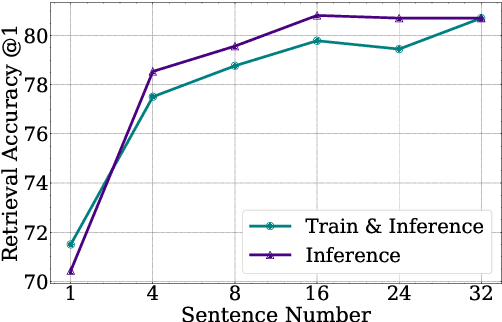
Cross-lingual retrieval aims to retrieve relevant text across languages. Current methods typically achieve cross-lingual retrieval by learning language-agnostic text representations in word or sentence level. However, how to learn phrase representations for cross-lingual phrase retrieval is still an open problem. In this paper, we propose XPR, a cross-lingual phrase retriever that extracts phrase representations from unlabeled example sentences. Moreover, we create a large-scale cross-lingual phrase retrieval dataset, which contains 65K bilingual phrase pairs and 4.2M example sentences in 8 English-centric language pairs. Experimental results show that XPR outperforms state-of-the-art baselines which utilize word-level or sentence-level representations. XPR also shows impressive zero-shot transferability that enables the model to perform retrieval in an unseen language pair during training. Our dataset, code, and trained models are publicly available at www.github.com/cwszz/XPR/.
SEPT: Improving Scientific Named Entity Recognition with Span Representation
Nov 08, 2019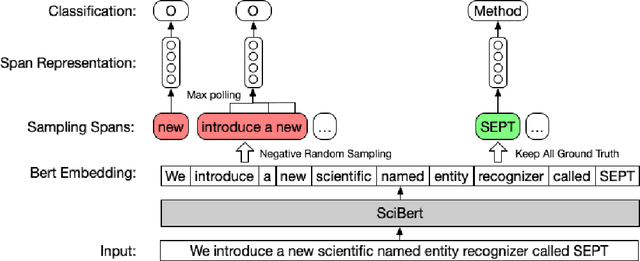
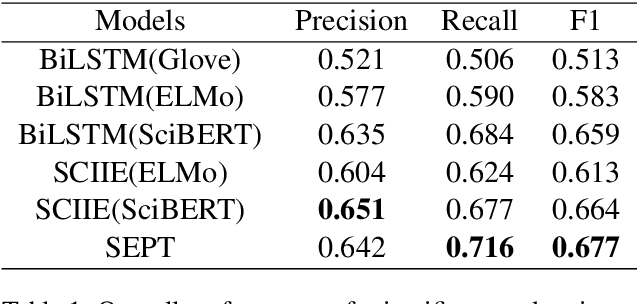
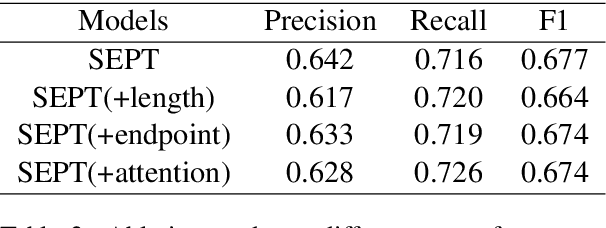
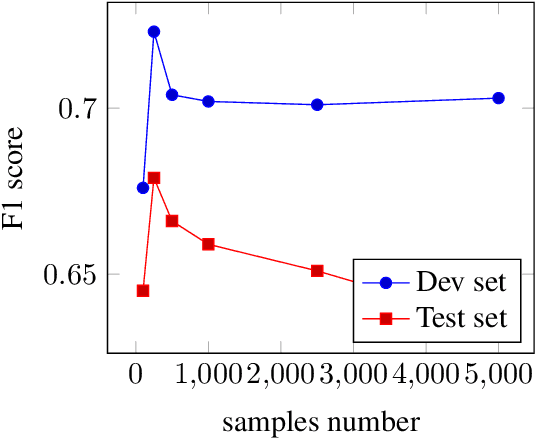
We introduce a new scientific named entity recognizer called SEPT, which stands for Span Extractor with Pre-trained Transformers. In recent papers, span extractors have been demonstrated to be a powerful model compared with sequence labeling models. However, we discover that with the development of pre-trained language models, the performance of span extractors appears to become similar to sequence labeling models. To keep the advantages of span representation, we modified the model by under-sampling to balance the positive and negative samples and reduce the search space. Furthermore, we simplify the origin network architecture to combine the span extractor with BERT. Experiments demonstrate that even simplified architecture achieves the same performance and SEPT achieves a new state of the art result in scientific named entity recognition even without relation information involved.