 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProtLLM: An Interleaved Protein-Language LLM with Protein-as-Word Pre-Training
Feb 28, 2024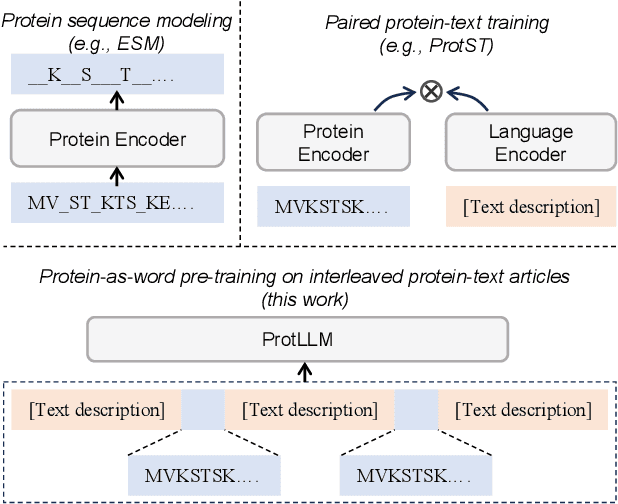

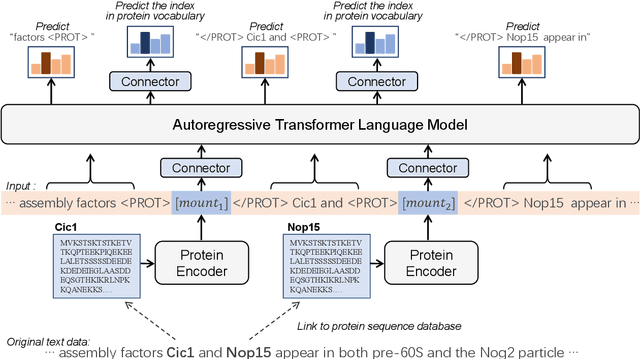

We propose ProtLLM, a versatile cross-modal large language model (LLM) for both protein-centric and protein-language tasks. ProtLLM features a unique dynamic protein mounting mechanism, enabling it to handle complex inputs where the natural language text is interspersed with an arbitrary number of proteins. Besides, we propose the protein-as-word language modeling approach to train ProtLLM. By developing a specialized protein vocabulary, we equip the model with the capability to predict not just natural language but also proteins from a vast pool of candidates. Additionally, we construct a large-scale interleaved protein-text dataset, named InterPT, for pre-training. This dataset comprehensively encompasses both (1) structured data sources like protein annotations and (2) unstructured data sources like biological research papers, thereby endowing ProtLLM with crucial knowledge for understanding proteins. We evaluate ProtLLM on classic supervised protein-centric tasks and explore its novel protein-language applications. Experimental results demonstrate that ProtLLM not only achieves superior performance against protein-specialized baselines on protein-centric tasks but also induces zero-shot and in-context learning capabilities on protein-language tasks.
SciMRC: Multi-perspective Scientific Machine Reading Comprehension
Jun 25, 2023



Scientific machine reading comprehension (SMRC) aims to understand scientific texts through interactions with humans by given questions. As far as we know, there is only one dataset focused on exploring full-text scientific machine reading comprehension. However, the dataset has ignored the fact that different readers may have different levels of understanding of the text, and only includes single-perspective question-answer pairs, leading to a lack of consideration of different perspectives. To tackle the above problem, we propose a novel multi-perspective SMRC dataset, called SciMRC, which includes perspectives from beginners, students and experts. Our proposed SciMRC is constructed from 741 scientific papers and 6,057 question-answer pairs. Each perspective of beginners, students and experts contains 3,306, 1,800 and 951 QA pairs, respectively. The extensive experiments on SciMRC by utilizing pre-trained models suggest the importance of considering perspectives of SMRC, and demonstrate its challenging nature for machine comprehension.
Cross-Lingual Phrase Retrieval
Apr 19, 2022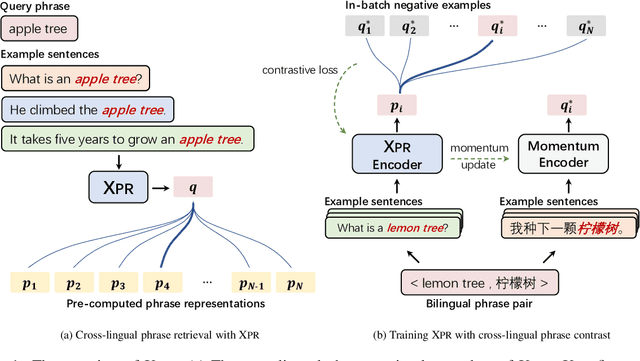


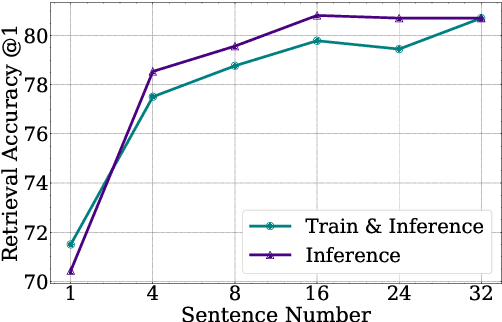
Cross-lingual retrieval aims to retrieve relevant text across languages. Current methods typically achieve cross-lingual retrieval by learning language-agnostic text representations in word or sentence level. However, how to learn phrase representations for cross-lingual phrase retrieval is still an open problem. In this paper, we propose XPR, a cross-lingual phrase retriever that extracts phrase representations from unlabeled example sentences. Moreover, we create a large-scale cross-lingual phrase retrieval dataset, which contains 65K bilingual phrase pairs and 4.2M example sentences in 8 English-centric language pairs. Experimental results show that XPR outperforms state-of-the-art baselines which utilize word-level or sentence-level representations. XPR also shows impressive zero-shot transferability that enables the model to perform retrieval in an unseen language pair during training. Our dataset, code, and trained models are publicly available at www.github.com/cwszz/XPR/.