 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLabeled TrustSet Guided: Batch Active Learning with Reinforcement Learning
Apr 14, 2026Batch active learning (BAL) is a crucial technique for reducing labeling costs and improving data efficiency in training large-scale deep learning models. Traditional BAL methods often rely on metrics like Mahalanobis Distance to balance uncertainty and diversity when selecting data for annotation. However, these methods predominantly focus on the distribution of unlabeled data and fail to leverage feedback from labeled data or the model's performance. To address these limitations, we introduce TrustSet, a novel approach that selects the most informative data from the labeled dataset, ensuring a balanced class distribution to mitigate the long-tail problem. Unlike CoreSet, which focuses on maintaining the overall data distribution, TrustSet optimizes the model's performance by pruning redundant data and using label information to refine the selection process. To extend the benefits of TrustSet to the unlabeled pool, we propose a reinforcement learning (RL)-based sampling policy that approximates the selection of high-quality TrustSet candidates from the unlabeled data. Combining TrustSet and RL, we introduce the Batch Reinforcement Active Learning with TrustSet (BRAL-T) framework. BRAL-T achieves state-of-the-art results across 10 image classification benchmarks and 2 active fine-tuning tasks, demonstrating its effectiveness and efficiency in various domains.
VoiceCraft-X: Unifying Multilingual, Voice-Cloning Speech Synthesis and Speech Editing
Nov 15, 2025We introduce VoiceCraft-X, an autoregressive neural codec language model which unifies multilingual speech editing and zero-shot Text-to-Speech (TTS) synthesis across 11 languages: English, Mandarin, Korean, Japanese, Spanish, French, German, Dutch, Italian, Portuguese, and Polish. VoiceCraft-X utilizes the Qwen3 large language model for phoneme-free cross-lingual text processing and a novel token reordering mechanism with time-aligned text and speech tokens to handle both tasks as a single sequence generation problem. The model generates high-quality, natural-sounding speech, seamlessly creating new audio or editing existing recordings within one framework. VoiceCraft-X shows robust performance in diverse linguistic settings, even with limited per-language data, underscoring the power of unified autoregressive approaches for advancing complex, real-world multilingual speech applications. Audio samples are available at https://zhishengzheng.com/voicecraft-x/.
RefTok: Reference-Based Tokenization for Video Generation
Jul 03, 2025Effectively handling temporal redundancy remains a key challenge in learning video models. Prevailing approaches often treat each set of frames independently, failing to effectively capture the temporal dependencies and redundancies inherent in videos. To address this limitation, we introduce RefTok, a novel reference-based tokenization method capable of capturing complex temporal dynamics and contextual information. Our method encodes and decodes sets of frames conditioned on an unquantized reference frame. When decoded, RefTok preserves the continuity of motion and the appearance of objects across frames. For example, RefTok retains facial details despite head motion, reconstructs text correctly, preserves small patterns, and maintains the legibility of handwriting from the context. Across 4 video datasets (K600, UCF-101, BAIR Robot Pushing, and DAVIS), RefTok significantly outperforms current state-of-the-art tokenizers (Cosmos and MAGVIT) and improves all evaluated metrics (PSNR, SSIM, LPIPS) by an average of 36.7% at the same or higher compression ratios. When a video generation model is trained using RefTok's latents on the BAIR Robot Pushing task, the generations not only outperform MAGVIT-B but the larger MAGVIT-L, which has 4x more parameters, across all generation metrics by an average of 27.9%.
Audio-Enhanced Text-to-Video Retrieval using Text-Conditioned Feature Alignment
Jul 24, 2023



Text-to-video retrieval systems have recently made significant progress by utilizing pre-trained models trained on large-scale image-text pairs. However, most of the latest methods primarily focus on the video modality while disregarding the audio signal for this task. Nevertheless, a recent advancement by ECLIPSE has improved long-range text-to-video retrieval by developing an audiovisual video representation. Nonetheless, the objective of the text-to-video retrieval task is to capture the complementary audio and video information that is pertinent to the text query rather than simply achieving better audio and video alignment. To address this issue, we introduce TEFAL, a TExt-conditioned Feature ALignment method that produces both audio and video representations conditioned on the text query. Instead of using only an audiovisual attention block, which could suppress the audio information relevant to the text query, our approach employs two independent cross-modal attention blocks that enable the text to attend to the audio and video representations separately. Our proposed method's efficacy is demonstrated on four benchmark datasets that include audio: MSR-VTT, LSMDC, VATEX, and Charades, and achieves better than state-of-the-art performance consistently across the four datasets. This is attributed to the additional text-query-conditioned audio representation and the complementary information it adds to the text-query-conditioned video representation.
When deep denoising meets iterative phase retrieval
Mar 03, 2020
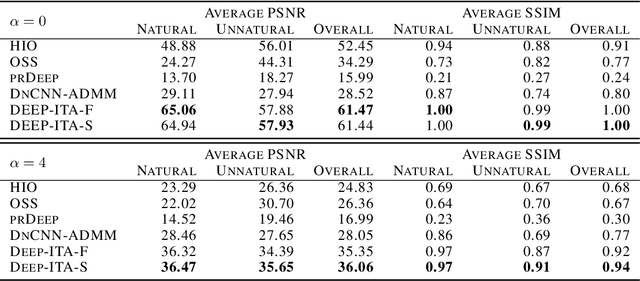

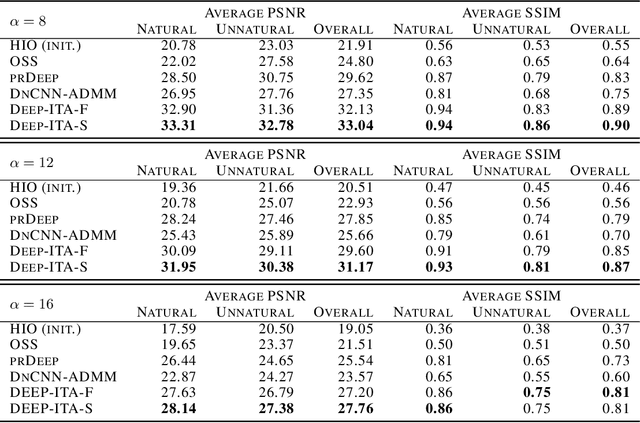
Recovering a signal from its Fourier intensity underlies many important applications, including lensless imaging and imaging through scattering media. Conventional algorithms for retrieving the phase suffer when noise is present but display global convergence when given clean data. Neural networks have been used to improve algorithm robustness, but efforts to date are sensitive to initial conditions and give inconsistent performance. Here, we combine iterative methods from phase retrieval with image statistics from deep denoisers, via regularization-by-denoising. The resulting methods inherit the advantages of each approach and outperform other noise-robust phase retrieval algorithms. Our work paves the way for hybrid imaging methods that integrate machine-learned constraints in conventional algorithms.
DuDoNet: Dual Domain Network for CT Metal Artifact Reduction
Jun 29, 2019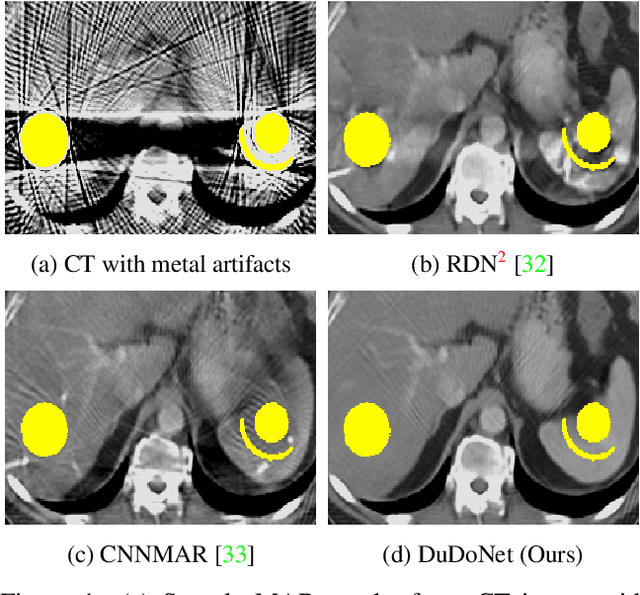


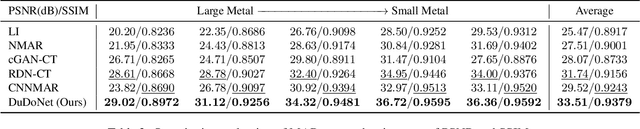
Computed tomography (CT) is an imaging modality widely used for medical diagnosis and treatment. CT images are often corrupted by undesirable artifacts when metallic implants are carried by patients, which creates the problem of metal artifact reduction (MAR). Existing methods for reducing the artifacts due to metallic implants are inadequate for two main reasons. First, metal artifacts are structured and non-local so that simple image domain enhancement approaches would not suffice. Second, the MAR approaches which attempt to reduce metal artifacts in the X-ray projection (sinogram) domain inevitably lead to severe secondary artifact due to sinogram inconsistency. To overcome these difficulties, we propose an end-to-end trainable Dual Domain Network (DuDoNet) to simultaneously restore sinogram consistency and enhance CT images. The linkage between the sigogram and image domains is a novel Radon inversion layer that allows the gradients to back-propagate from the image domain to the sinogram domain during training. Extensive experiments show that our method achieves significant improvements over other single domain MAR approaches. To the best of our knowledge, it is the first end-to-end dual-domain network for MAR.