 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMock Worlds, Real Skills: Building Small Agentic Language Models with Synthetic Tasks, Simulated Environments, and Rubric-Based Rewards
Jan 30, 2026Small LLMs often struggle to match the agentic capabilities of large, costly models. While reinforcement learning can help, progress has been limited by two structural bottlenecks: existing open-source agentic training data are narrow in task variety and easily solved; real-world APIs lack diversity and are unstable for large-scale reinforcement learning rollout processes. We address these challenges with SYNTHAGENT, a framework that jointly synthesizes diverse tool-use training data and simulates complete environments. Specifically, a strong teacher model creates novel tasks and tool ecosystems, then rewrites them into intentionally underspecified instructions. This compels agents to actively query users for missing details. When handling synthetic tasks, an LLM-based user simulator provides user-private information, while a mock tool system delivers stable tool responses. For rewards, task-level rubrics are constructed based on required subgoals, user-agent interactions, and forbidden behaviors. Across 14 challenging datasets in math, search, and tool use, models trained on our synthetic data achieve substantial gains, with small models outperforming larger baselines.
VTC-R1: Vision-Text Compression for Efficient Long-Context Reasoning
Jan 29, 2026Long-context reasoning has significantly empowered large language models (LLMs) to tackle complex tasks, yet it introduces severe efficiency bottlenecks due to the computational complexity. Existing efficient approaches often rely on complex additional training or external models for compression, which limits scalability and discards critical fine-grained information. In this paper, we propose VTC-R1, a new efficient reasoning paradigm that integrates vision-text compression into the reasoning process. Instead of processing lengthy textual traces, VTC-R1 renders intermediate reasoning segments into compact images, which are iteratively fed back into vision-language models as "optical memory." We construct a training dataset based on OpenR1-Math-220K achieving 3.4x token compression and fine-tune representative VLMs-Glyph and Qwen3-VL. Extensive experiments on benchmarks such as MATH500, AIME25, AMC23 and GPQA-D demonstrate that VTC-R1 consistently outperforms standard long-context reasoning. Furthermore, our approach significantly improves inference efficiency, achieving 2.7x speedup in end-to-end latency, highlighting its potential as a scalable solution for reasoning-intensive applications. Our code is available at https://github.com/w-yibo/VTC-R1.
Reinforcement Learning-Based Energy-Aware Coverage Path Planning for Precision Agriculture
Jan 23, 2026Coverage Path Planning (CPP) is a fundamental capability for agricultural robots; however, existing solutions often overlook energy constraints, resulting in incomplete operations in large-scale or resource-limited environments. This paper proposes an energy-aware CPP framework grounded in Soft Actor-Critic (SAC) reinforcement learning, designed for grid-based environments with obstacles and charging stations. To enable robust and adaptive decision-making under energy limitations, the framework integrates Convolutional Neural Networks (CNNs) for spatial feature extraction and Long Short-Term Memory (LSTM) networks for temporal dynamics. A dedicated reward function is designed to jointly optimize coverage efficiency, energy consumption, and return-to-base constraints. Experimental results demonstrate that the proposed approach consistently achieves over 90% coverage while ensuring energy safety, outperforming traditional heuristic algorithms such as Rapidly-exploring Random Tree (RRT), Particle Swarm Optimization (PSO), and Ant Colony Optimization (ACO) baselines by 13.4-19.5% in coverage and reducing constraint violations by 59.9-88.3%. These findings validate the proposed SAC-based framework as an effective and scalable solution for energy-constrained CPP in agricultural robotics.
* Accepted by RACS '25: International Conference on Research in Adaptive and Convergent Systems, November 16-19, 2025, Ho Chi Minh, Vietnam. 10 pages, 5 figures
Natural Language-Driven Global Mapping of Martian Landforms
Jan 22, 2026Planetary surfaces are typically analyzed using high-level semantic concepts in natural language, yet vast orbital image archives remain organized at the pixel level. This mismatch limits scalable, open-ended exploration of planetary surfaces. Here we present MarScope, a planetary-scale vision-language framework enabling natural language-driven, label-free mapping of Martian landforms. MarScope aligns planetary images and text in a shared semantic space, trained on over 200,000 curated image-text pairs. This framework transforms global geomorphic mapping on Mars by replacing pre-defined classifications with flexible semantic retrieval, enabling arbitrary user queries across the entire planet in 5 seconds with F1 scores up to 0.978. Applications further show that it extends beyond morphological classification to facilitate process-oriented analysis and similarity-based geomorphological mapping at a planetary scale. MarScope establishes a new paradigm where natural language serves as a direct interface for scientific discovery over massive geospatial datasets.
On Exact Editing of Flow-Based Diffusion Models
Dec 30, 2025Recent methods in flow-based diffusion editing have enabled direct transformations between source and target image distribution without explicit inversion. However, the latent trajectories in these methods often exhibit accumulated velocity errors, leading to semantic inconsistency and loss of structural fidelity. We propose Conditioned Velocity Correction (CVC), a principled framework that reformulates flow-based editing as a distribution transformation problem driven by a known source prior. CVC rethinks the role of velocity in inter-distribution transformation by introducing a dual-perspective velocity conversion mechanism. This mechanism explicitly decomposes the latent evolution into two components: a structure-preserving branch that remains consistent with the source trajectory, and a semantically-guided branch that drives a controlled deviation toward the target distribution. The conditional velocity field exhibits an absolute velocity error relative to the true underlying distribution trajectory, which inherently introduces potential instability and trajectory drift in the latent space. To address this quantifiable deviation and maintain fidelity to the true flow, we apply a posterior-consistent update to the resulting conditional velocity field. This update is derived from Empirical Bayes Inference and Tweedie correction, which ensures a mathematically grounded error compensation over time. Our method yields stable and interpretable latent dynamics, achieving faithful reconstruction alongside smooth local semantic conversion. Comprehensive experiments demonstrate that CVC consistently achieves superior fidelity, better semantic alignment, and more reliable editing behavior across diverse tasks.
Enhancing Credit Risk Prediction: A Meta-Learning Framework Integrating Baseline Models, LASSO, and ECOC for Superior Accuracy
Sep 26, 2025Effective credit risk management is fundamental to financial decision-making, necessitating robust models for default probability prediction and financial entity classification. Traditional machine learning approaches face significant challenges when confronted with high-dimensional data, limited interpretability, rare event detection, and multi-class imbalance problems in risk assessment. This research proposes a comprehensive meta-learning framework that synthesizes multiple complementary models: supervised learning algorithms, including XGBoost, Random Forest, Support Vector Machine, and Decision Tree; unsupervised methods such as K-Nearest Neighbors; deep learning architectures like Multilayer Perceptron; alongside LASSO regularization for feature selection and dimensionality reduction; and Error-Correcting Output Codes as a meta-classifier for handling imbalanced multi-class problems. We implement Permutation Feature Importance analysis for each prediction class across all constituent models to enhance model transparency. Our framework aims to optimize predictive performance while providing a more holistic approach to credit risk assessment. This research contributes to the development of more accurate and reliable computational models for strategic financial decision support by addressing three fundamental challenges in credit risk modeling. The empirical validation of our approach involves an analysis of the Corporate Credit Ratings dataset with credit ratings for 2,029 publicly listed US companies. Results demonstrate that our meta-learning framework significantly enhances the accuracy of financial entity classification regarding credit rating migrations (upgrades and downgrades) and default probability estimation.
RealMirror: A Comprehensive, Open-Source Vision-Language-Action Platform for Embodied AI
Sep 18, 2025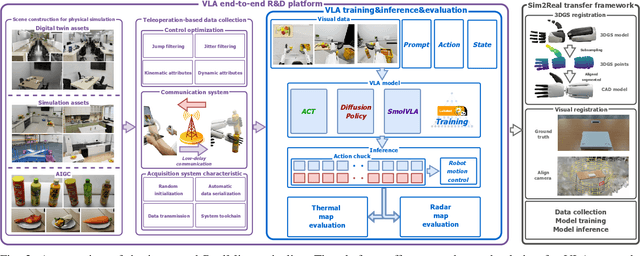
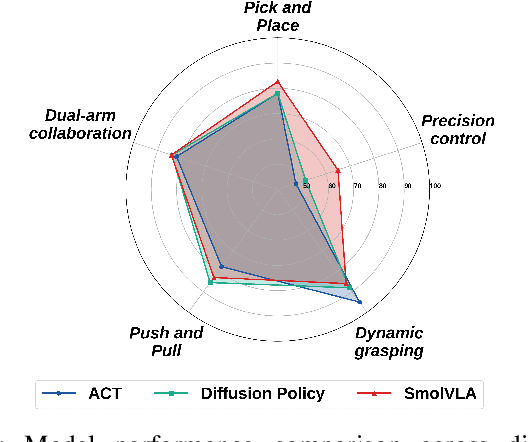
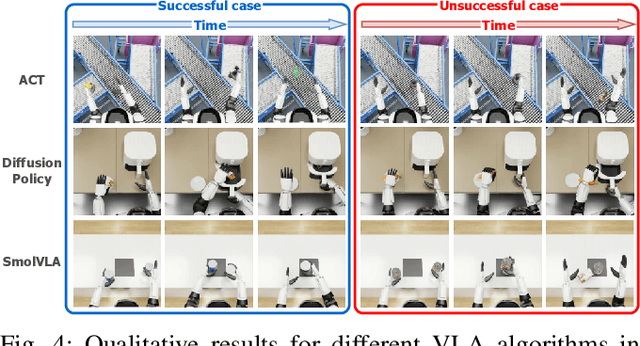

The emerging field of Vision-Language-Action (VLA) for humanoid robots faces several fundamental challenges, including the high cost of data acquisition, the lack of a standardized benchmark, and the significant gap between simulation and the real world. To overcome these obstacles, we propose RealMirror, a comprehensive, open-source embodied AI VLA platform. RealMirror builds an efficient, low-cost data collection, model training, and inference system that enables end-to-end VLA research without requiring a real robot. To facilitate model evolution and fair comparison, we also introduce a dedicated VLA benchmark for humanoid robots, featuring multiple scenarios, extensive trajectories, and various VLA models. Furthermore, by integrating generative models and 3D Gaussian Splatting to reconstruct realistic environments and robot models, we successfully demonstrate zero-shot Sim2Real transfer, where models trained exclusively on simulation data can perform tasks on a real robot seamlessly, without any fine-tuning. In conclusion, with the unification of these critical components, RealMirror provides a robust framework that significantly accelerates the development of VLA models for humanoid robots. Project page: https://terminators2025.github.io/RealMirror.github.io
Enhancing Vehicular Platooning with Wireless Federated Learning: A Resource-Aware Control Framework
Jul 01, 2025This paper aims to enhance the performance of Vehicular Platooning (VP) systems integrated with Wireless Federated Learning (WFL). In highly dynamic environments, vehicular platoons experience frequent communication changes and resource constraints, which significantly affect information exchange and learning model synchronization. To address these challenges, we first formulate WFL in VP as a joint optimization problem that simultaneously considers Age of Information (AoI) and Federated Learning Model Drift (FLMD) to ensure timely and accurate control. Through theoretical analysis, we examine the impact of FLMD on convergence performance and develop a two-stage Resource-Aware Control framework (RACE). The first stage employs a Lagrangian dual decomposition method for resource configuration, while the second stage implements a multi-agent deep reinforcement learning approach for vehicle selection. The approach integrates Multi-Head Self-Attention and Long Short-Term Memory networks to capture spatiotemporal correlations in communication states. Experimental results demonstrate that, compared to baseline methods, the proposed framework improves AoI optimization by up to 45%, accelerates learning convergence, and adapts more effectively to dynamic VP environments on the AI4MARS dataset.
Toward Safety-First Human-Like Decision Making for Autonomous Vehicles in Time-Varying Traffic Flow
Jun 17, 2025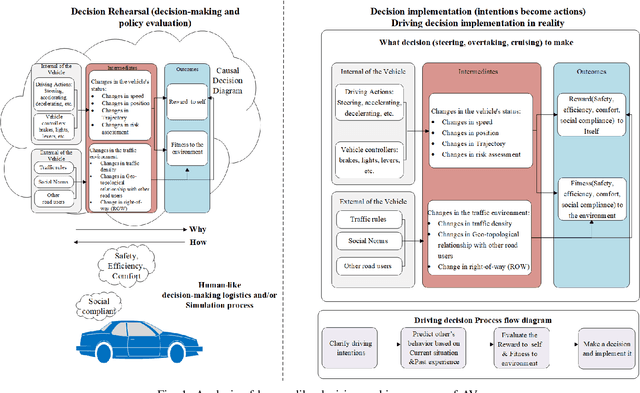

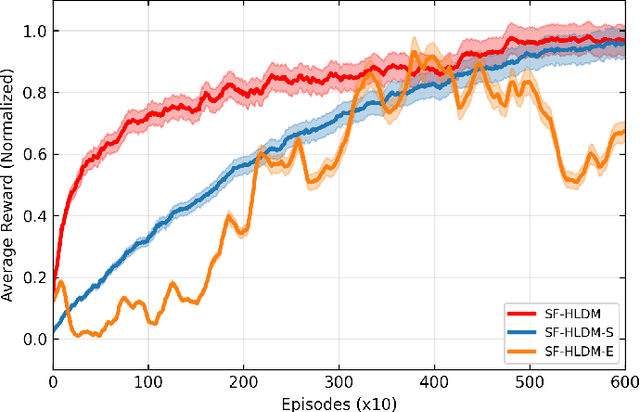
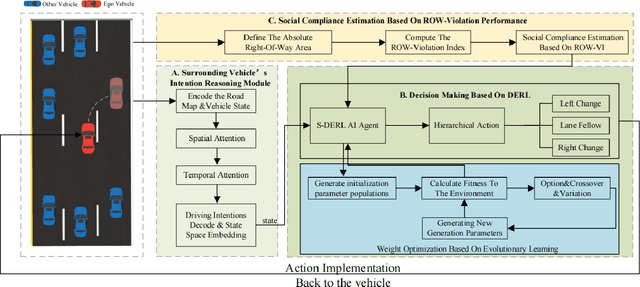
Despite the recent advancements in artificial intelligence technologies have shown great potential in improving transport efficiency and safety, autonomous vehicles(AVs) still face great challenge of driving in time-varying traffic flow, especially in dense and interactive situations. Meanwhile, human have free wills and usually do not make the same decisions even situate in the exactly same scenarios, leading to the data-driven methods suffer from poor migratability and high search cost problems, decreasing the efficiency and effectiveness of the behavior policy. In this research, we propose a safety-first human-like decision-making framework(SF-HLDM) for AVs to drive safely, comfortably, and social compatiblely in effiency. The framework integrates a hierarchical progressive framework, which combines a spatial-temporal attention (S-TA) mechanism for other road users' intention inference, a social compliance estimation module for behavior regulation, and a Deep Evolutionary Reinforcement Learning(DERL) model for expanding the search space efficiently and effectively to make avoidance of falling into the local optimal trap and reduce the risk of overfitting, thus make human-like decisions with interpretability and flexibility. The SF-HLDM framework enables autonomous driving AI agents dynamically adjusts decision parameters to maintain safety margins and adhering to contextually appropriate driving behaviors at the same time.
Zero-to-Hero: Zero-Shot Initialization Empowering Reference-Based Video Appearance Editing
May 29, 2025Appearance editing according to user needs is a pivotal task in video editing. Existing text-guided methods often lead to ambiguities regarding user intentions and restrict fine-grained control over editing specific aspects of objects. To overcome these limitations, this paper introduces a novel approach named {Zero-to-Hero}, which focuses on reference-based video editing that disentangles the editing process into two distinct problems. It achieves this by first editing an anchor frame to satisfy user requirements as a reference image and then consistently propagating its appearance across other frames. We leverage correspondence within the original frames to guide the attention mechanism, which is more robust than previously proposed optical flow or temporal modules in memory-friendly video generative models, especially when dealing with objects exhibiting large motions. It offers a solid ZERO-shot initialization that ensures both accuracy and temporal consistency. However, intervention in the attention mechanism results in compounded imaging degradation with over-saturated colors and unknown blurring issues. Starting from Zero-Stage, our Hero-Stage Holistically learns a conditional generative model for vidEo RestOration. To accurately evaluate the consistency of the appearance, we construct a set of videos with multiple appearances using Blender, enabling a fine-grained and deterministic evaluation. Our method outperforms the best-performing baseline with a PSNR improvement of 2.6 dB. The project page is at https://github.com/Tonniia/Zero2Hero.