 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Semantic Variation in Text-to-Image Synthesis: A Causal Perspective
Oct 14, 2024
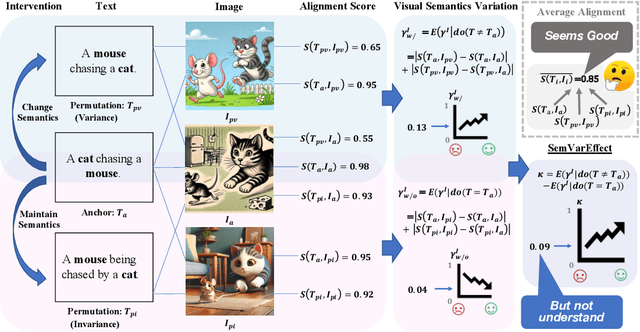
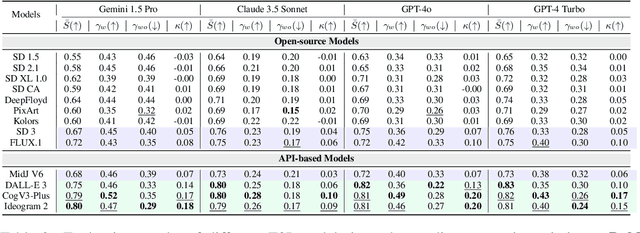
Accurate interpretation and visualization of human instructions are crucial for text-to-image (T2I) synthesis. However, current models struggle to capture semantic variations from word order changes, and existing evaluations, relying on indirect metrics like text-image similarity, fail to reliably assess these challenges. This often obscures poor performance on complex or uncommon linguistic patterns by the focus on frequent word combinations. To address these deficiencies, we propose a novel metric called SemVarEffect and a benchmark named SemVarBench, designed to evaluate the causality between semantic variations in inputs and outputs in T2I synthesis. Semantic variations are achieved through two types of linguistic permutations, while avoiding easily predictable literal variations. Experiments reveal that the CogView-3-Plus and Ideogram 2 performed the best, achieving a score of 0.2/1. Semantic variations in object relations are less understood than attributes, scoring 0.07/1 compared to 0.17-0.19/1. We found that cross-modal alignment in UNet or Transformers plays a crucial role in handling semantic variations, a factor previously overlooked by a focus on textual encoders. Our work establishes an effective evaluation framework that advances the T2I synthesis community's exploration of human instruction understanding.
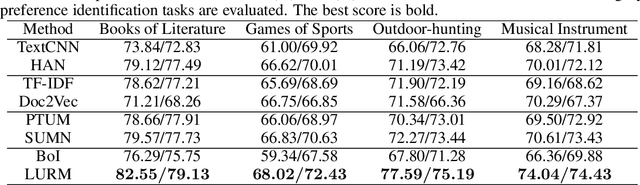
Learning Universal User Representations via Self-Supervised Lifelong Behaviors Modeling
Oct 25, 2021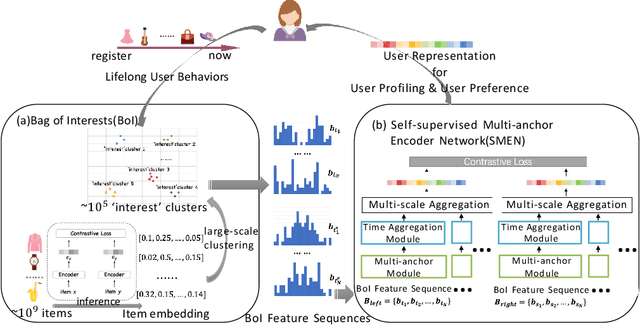

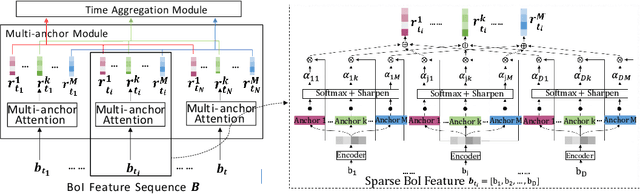
Universal user representation is an important research topic in industry, and is widely used in diverse downstream user analysis tasks, such as user profiling and user preference prediction. With the rapid development of Internet service platforms, extremely long user behavior sequences have been accumulated. However, existing researches have little ability to model universal user representation based on lifelong sequences of user behavior since registration. In this study, we propose a novel framework called Lifelong User Representation Model (LURM) to tackle this challenge. Specifically, LURM consists of two cascaded sub-models: (i) Bag of Interests (BoI) encodes user behaviors in any time period into a sparse vector with super-high dimension (e.g.,105); (ii) Self-supervised Multi-anchor EncoderNetwork (SMEN) maps sequences of BoI features to multiple low-dimensional user representations by contrastive learning. SMEN achieves almost lossless dimensionality reduction, benefiting from a novel multi-anchor module which can learn different aspects of user preferences. Experiments on several benchmark datasets show that our approach outperforms state-of-the-art unsupervised representation methods in downstream tasks
Interest-oriented Universal User Representation via Contrastive Learning
Sep 18, 2021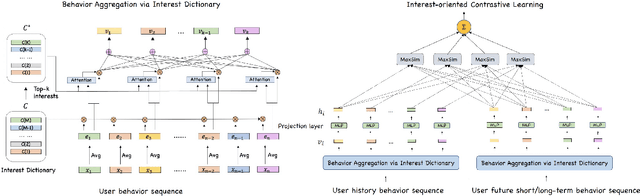
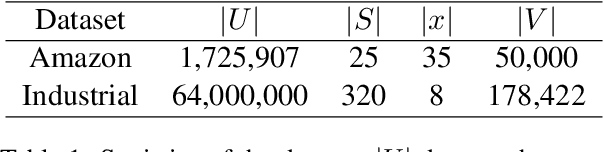
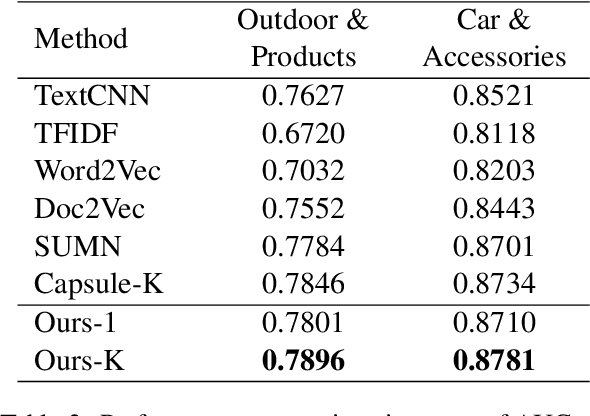
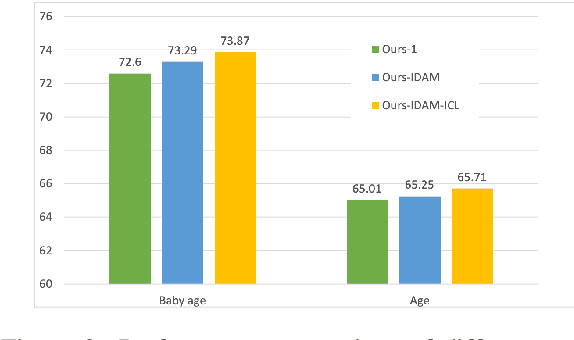
User representation is essential for providing high-quality commercial services in industry. Universal user representation has received many interests recently, with which we can be free from the cumbersome work of training a specific model for each downstream application. In this paper, we attempt to improve universal user representation from two points of views. First, a contrastive self-supervised learning paradigm is presented to guide the representation model training. It provides a unified framework that allows for long-term or short-term interest representation learning in a data-driven manner. Moreover, a novel multi-interest extraction module is presented. The module introduces an interest dictionary to capture principal interests of the given user, and then generate his/her interest-oriented representations via behavior aggregation. Experimental results demonstrate the effectiveness and applicability of the learned user representations.