 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgenticQwen: Training Small Agentic Language Models with Dual Data Flywheels for Industrial-Scale Tool Use
Apr 23, 2026Modern industrial applications increasingly demand language models that act as agents, capable of multi-step reasoning and tool use in real-world settings. These tasks are typically performed under strict cost and latency constraints, making small agentic models highly desirable. In this paper, we introduce the AgenticQwen family of models, trained via multi-round reinforcement learning (RL) on synthetic data and a limited amount of open-source data. Our training framework combines reasoning RL and agentic RL with dual data flywheels that automatically generate increasingly challenging tasks. The reasoning flywheel increases task difficulty by learning from errors, while the agentic flywheel expands linear workflows into multi-branch behavior trees that better reflect the decision complexity of real-world applications. We validate AgenticQwen on public benchmarks and in an industrial agent system. The models achieve strong performance on multiple agentic benchmarks, and in our industrial agent system, close the gap with much larger models on search and data analysis tasks. Model checkpoints and part of the synthetic data: https://huggingface.co/collections/alibaba-pai/agenticqwen. Data synthesis and RL training code: https://github.com/haruhi-sudo/data_synth_and_rl. The data synthesis pipeline is also integrated into EasyDistill: https://github.com/modelscope/easydistill.
EasyDistill: A Comprehensive Toolkit for Effective Knowledge Distillation of Large Language Models
May 27, 2025In this paper, we present EasyDistill, a comprehensive toolkit designed for effective black-box and white-box knowledge distillation (KD) of large language models (LLMs). Our framework offers versatile functionalities, including data synthesis, supervised fine-tuning, ranking optimization, and reinforcement learning techniques specifically tailored for KD scenarios. The toolkit accommodates KD functionalities for both System 1 (fast, intuitive) and System 2 (slow, analytical) models. With its modular design and user-friendly interface, EasyDistill empowers researchers and industry practitioners to seamlessly experiment with and implement state-of-the-art KD strategies for LLMs. In addition, EasyDistill provides a series of robust distilled models and KD-based industrial solutions developed by us, along with the corresponding open-sourced datasets, catering to a variety of use cases. Furthermore, we describe the seamless integration of EasyDistill into Alibaba Cloud's Platform for AI (PAI). Overall, the EasyDistill toolkit makes advanced KD techniques for LLMs more accessible and impactful within the NLP community.
Reasoning with OmniThought: A Large CoT Dataset with Verbosity and Cognitive Difficulty Annotations
May 16, 2025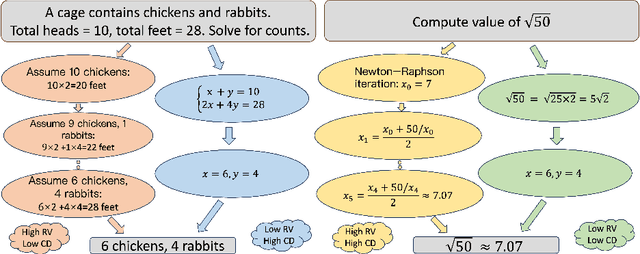



The emergence of large reasoning models (LRMs) has transformed Natural Language Processing by excelling in complex tasks such as mathematical problem-solving and code generation. These models leverage chain-of-thought (CoT) processes, enabling them to emulate human-like reasoning strategies. However, the advancement of LRMs is hindered by the lack of comprehensive CoT datasets. Current resources often fail to provide extensive reasoning problems with coherent CoT processes distilled from multiple teacher models and do not account for multifaceted properties describing the internal characteristics of CoTs. To address these challenges, we introduce OmniThought, a large-scale dataset featuring 2 million CoT processes generated and validated by two powerful LRMs as teacher models. Each CoT process in OmniThought is annotated with novel Reasoning Verbosity (RV) and Cognitive Difficulty (CD) scores, which describe the appropriateness of CoT verbosity and cognitive difficulty level for models to comprehend these reasoning processes. We further establish a self-reliant pipeline to curate this dataset. Extensive experiments using Qwen2.5 models of various sizes demonstrate the positive impact of our proposed scores on LRM training effectiveness. Based on the proposed OmniThought dataset, we further train and release a series of high-performing LRMs, specifically equipped with stronger reasoning abilities and optimal CoT output length and difficulty level. Our contributions significantly enhance the development and training of LRMs for solving complex tasks.
DistilQwen2.5: Industrial Practices of Training Distilled Open Lightweight Language Models
Apr 21, 2025Enhancing computational efficiency and reducing deployment costs for large language models (LLMs) have become critical challenges in various resource-constrained scenarios. In this work, we present DistilQwen2.5, a family of distilled, lightweight LLMs derived from the public Qwen2.5 models. These distilled models exhibit enhanced instruction-following capabilities compared to the original models based on a series of distillation techniques that incorporate knowledge from much larger LLMs. In our industrial practice, we first leverage powerful proprietary LLMs with varying capacities as multi-agent teachers to select, rewrite, and refine instruction-response pairs that are more suitable for student LLMs to learn. After standard fine-tuning, we further leverage a computationally efficient model fusion approach that enables student models to progressively integrate fine-grained hidden knowledge from their teachers. Experimental evaluations demonstrate that the distilled models possess significantly stronger capabilities than their original checkpoints. Additionally, we present use cases to illustrate the applications of our framework in real-world scenarios. To facilitate practical use, we have released all the DistilQwen2.5 models to the open-source community.
Training Small Reasoning LLMs with Cognitive Preference Alignment
Apr 14, 2025The reasoning capabilities of large language models (LLMs), such as OpenAI's o1 and DeepSeek-R1, have seen substantial advancements through deep thinking. However, these enhancements come with significant resource demands, underscoring the need to explore strategies to train effective reasoning LLMs with far fewer parameters. A critical challenge is that smaller models have different capacities and cognitive trajectories than their larger counterparts. Hence, direct distillation of chain-of-thought (CoT) results from large LLMs to smaller ones can be sometimes ineffective and requires a huge amount of annotated data. In this paper, we introduce a novel framework called Critique-Rethink-Verify (CRV), designed for training smaller yet powerful reasoning LLMs. Our CRV framework consists of multiple LLM agents, each specializing in unique abilities: (i) critiquing the CoTs according to the cognitive capabilities of smaller models, (ii) rethinking and refining these CoTs based on the critiques, and (iii) verifying the correctness of the refined results. We further propose the cognitive preference optimization (CogPO) algorithm to enhance the reasoning abilities of smaller models by aligning thoughts of these models with their cognitive capacities. Comprehensive evaluations on challenging reasoning benchmarks demonstrate the efficacy of CRV and CogPO, which outperforms other training methods by a large margin.
On the Role of Long-tail Knowledge in Retrieval Augmented Large Language Models
Jun 24, 2024
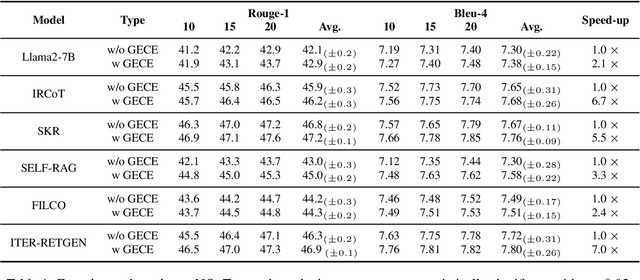
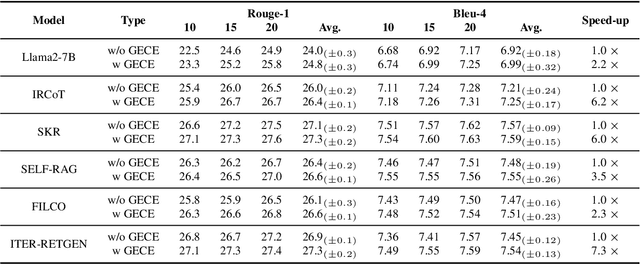
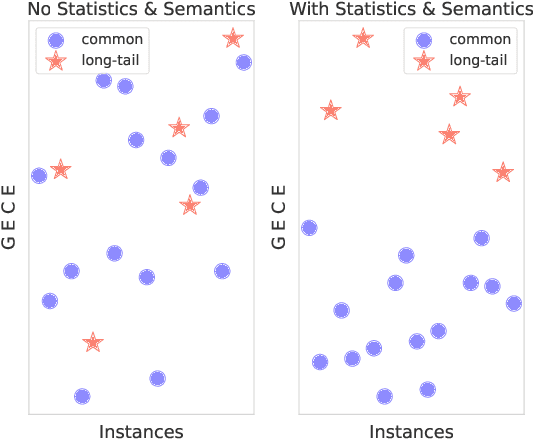
Retrieval augmented generation (RAG) exhibits outstanding performance in promoting the knowledge capabilities of large language models (LLMs) with retrieved documents related to user queries. However, RAG only focuses on improving the response quality of LLMs via enhancing queries indiscriminately with retrieved information, paying little attention to what type of knowledge LLMs really need to answer original queries more accurately. In this paper, we suggest that long-tail knowledge is crucial for RAG as LLMs have already remembered common world knowledge during large-scale pre-training. Based on our observation, we propose a simple but effective long-tail knowledge detection method for LLMs. Specifically, the novel Generative Expected Calibration Error (GECE) metric is derived to measure the ``long-tailness'' of knowledge based on both statistics and semantics. Hence, we retrieve relevant documents and infuse them into the model for patching knowledge loopholes only when the input query relates to long-tail knowledge. Experiments show that, compared to existing RAG pipelines, our method achieves over 4x speedup in average inference time and consistent performance improvement in downstream tasks.
TRELM: Towards Robust and Efficient Pre-training for Knowledge-Enhanced Language Models
Mar 17, 2024



KEPLMs are pre-trained models that utilize external knowledge to enhance language understanding. Previous language models facilitated knowledge acquisition by incorporating knowledge-related pre-training tasks learned from relation triples in knowledge graphs. However, these models do not prioritize learning embeddings for entity-related tokens. Moreover, updating the entire set of parameters in KEPLMs is computationally demanding. This paper introduces TRELM, a Robust and Efficient Pre-training framework for Knowledge-Enhanced Language Models. We observe that entities in text corpora usually follow the long-tail distribution, where the representations of some entities are suboptimally optimized and hinder the pre-training process for KEPLMs. To tackle this, we employ a robust approach to inject knowledge triples and employ a knowledge-augmented memory bank to capture valuable information. Furthermore, updating a small subset of neurons in the feed-forward networks (FFNs) that store factual knowledge is both sufficient and efficient. Specifically, we utilize dynamic knowledge routing to identify knowledge paths in FFNs and selectively update parameters during pre-training. Experimental results show that TRELM reduces pre-training time by at least 50% and outperforms other KEPLMs in knowledge probing tasks and multiple knowledge-aware language understanding tasks.
Do Large Language Models Understand Logic or Just Mimick Context?
Feb 19, 2024Over the past few years, the abilities of large language models (LLMs) have received extensive attention, which have performed exceptionally well in complicated scenarios such as logical reasoning and symbolic inference. A significant factor contributing to this progress is the benefit of in-context learning and few-shot prompting. However, the reasons behind the success of such models using contextual reasoning have not been fully explored. Do LLMs have understand logical rules to draw inferences, or do they ``guess'' the answers by learning a type of probabilistic mapping through context? This paper investigates the reasoning capabilities of LLMs on two logical reasoning datasets by using counterfactual methods to replace context text and modify logical concepts. Based on our analysis, it is found that LLMs do not truly understand logical rules; rather, in-context learning has simply enhanced the likelihood of these models arriving at the correct answers. If one alters certain words in the context text or changes the concepts of logical terms, the outputs of LLMs can be significantly disrupted, leading to counter-intuitive responses. This work provides critical insights into the limitations of LLMs, underscoring the need for more robust mechanisms to ensure reliable logical reasoning in LLMs.
Towards Better Parameter-Efficient Fine-Tuning for Large Language Models: A Position Paper
Nov 22, 2023This paper delves into the pressing need in Parameter-Efficient Fine-Tuning (PEFT) for Large Language Models (LLMs). While LLMs possess remarkable capabilities, their extensive parameter requirements and associated computational demands hinder their practicality and scalability for real-world applications. Our position paper highlights current states and the necessity of further studying into the topic, and recognizes significant challenges and open issues that must be addressed to fully harness the powerful abilities of LLMs. These challenges encompass novel efficient PEFT architectures, PEFT for different learning settings, PEFT combined with model compression techniques, and the exploration of PEFT for multi-modal LLMs. By presenting this position paper, we aim to stimulate further research and foster discussions surrounding more efficient and accessible PEFT for LLMs.
From Complex to Simple: Unraveling the Cognitive Tree for Reasoning with Small Language Models
Nov 12, 2023



Reasoning is a distinctive human capacity, enabling us to address complex problems by breaking them down into a series of manageable cognitive steps. Yet, complex logical reasoning is still cumbersome for language models. Based on the dual process theory in cognitive science, we are the first to unravel the cognitive reasoning abilities of language models. Our framework employs an iterative methodology to construct a Cognitive Tree (CogTree). The root node of this tree represents the initial query, while the leaf nodes consist of straightforward questions that can be answered directly. This construction involves two main components: the implicit extraction module (referred to as the intuitive system) and the explicit reasoning module (referred to as the reflective system). The intuitive system rapidly generates multiple responses by utilizing in-context examples, while the reflective system scores these responses using comparative learning. The scores guide the intuitive system in its subsequent generation step. Our experimental results on two popular and challenging reasoning tasks indicate that it is possible to achieve a performance level comparable to that of GPT-3.5 (with 175B parameters), using a significantly smaller language model that contains fewer parameters (<=7B) than 5% of GPT-3.5.