 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePaper2Rebuttal: A Multi-Agent Framework for Transparent Author Response Assistance
Jan 20, 2026Writing effective rebuttals is a high-stakes task that demands more than linguistic fluency, as it requires precise alignment between reviewer intent and manuscript details. Current solutions typically treat this as a direct-to-text generation problem, suffering from hallucination, overlooked critiques, and a lack of verifiable grounding. To address these limitations, we introduce $\textbf{RebuttalAgent}$, the first multi-agents framework that reframes rebuttal generation as an evidence-centric planning task. Our system decomposes complex feedback into atomic concerns and dynamically constructs hybrid contexts by synthesizing compressed summaries with high-fidelity text while integrating an autonomous and on-demand external search module to resolve concerns requiring outside literature. By generating an inspectable response plan before drafting, $\textbf{RebuttalAgent}$ ensures that every argument is explicitly anchored in internal or external evidence. We validate our approach on the proposed $\textbf{RebuttalBench}$ and demonstrate that our pipeline outperforms strong baselines in coverage, faithfulness, and strategic coherence, offering a transparent and controllable assistant for the peer review process. Code will be released.
EasyDistill: A Comprehensive Toolkit for Effective Knowledge Distillation of Large Language Models
May 27, 2025In this paper, we present EasyDistill, a comprehensive toolkit designed for effective black-box and white-box knowledge distillation (KD) of large language models (LLMs). Our framework offers versatile functionalities, including data synthesis, supervised fine-tuning, ranking optimization, and reinforcement learning techniques specifically tailored for KD scenarios. The toolkit accommodates KD functionalities for both System 1 (fast, intuitive) and System 2 (slow, analytical) models. With its modular design and user-friendly interface, EasyDistill empowers researchers and industry practitioners to seamlessly experiment with and implement state-of-the-art KD strategies for LLMs. In addition, EasyDistill provides a series of robust distilled models and KD-based industrial solutions developed by us, along with the corresponding open-sourced datasets, catering to a variety of use cases. Furthermore, we describe the seamless integration of EasyDistill into Alibaba Cloud's Platform for AI (PAI). Overall, the EasyDistill toolkit makes advanced KD techniques for LLMs more accessible and impactful within the NLP community.
DistilQwen2.5: Industrial Practices of Training Distilled Open Lightweight Language Models
Apr 21, 2025Enhancing computational efficiency and reducing deployment costs for large language models (LLMs) have become critical challenges in various resource-constrained scenarios. In this work, we present DistilQwen2.5, a family of distilled, lightweight LLMs derived from the public Qwen2.5 models. These distilled models exhibit enhanced instruction-following capabilities compared to the original models based on a series of distillation techniques that incorporate knowledge from much larger LLMs. In our industrial practice, we first leverage powerful proprietary LLMs with varying capacities as multi-agent teachers to select, rewrite, and refine instruction-response pairs that are more suitable for student LLMs to learn. After standard fine-tuning, we further leverage a computationally efficient model fusion approach that enables student models to progressively integrate fine-grained hidden knowledge from their teachers. Experimental evaluations demonstrate that the distilled models possess significantly stronger capabilities than their original checkpoints. Additionally, we present use cases to illustrate the applications of our framework in real-world scenarios. To facilitate practical use, we have released all the DistilQwen2.5 models to the open-source community.
SuperGPQA: Scaling LLM Evaluation across 285 Graduate Disciplines
Feb 20, 2025Large language models (LLMs) have demonstrated remarkable proficiency in mainstream academic disciplines such as mathematics, physics, and computer science. However, human knowledge encompasses over 200 specialized disciplines, far exceeding the scope of existing benchmarks. The capabilities of LLMs in many of these specialized fields-particularly in light industry, agriculture, and service-oriented disciplines-remain inadequately evaluated. To address this gap, we present SuperGPQA, a comprehensive benchmark that evaluates graduate-level knowledge and reasoning capabilities across 285 disciplines. Our benchmark employs a novel Human-LLM collaborative filtering mechanism to eliminate trivial or ambiguous questions through iterative refinement based on both LLM responses and expert feedback. Our experimental results reveal significant room for improvement in the performance of current state-of-the-art LLMs across diverse knowledge domains (e.g., the reasoning-focused model DeepSeek-R1 achieved the highest accuracy of 61.82% on SuperGPQA), highlighting the considerable gap between current model capabilities and artificial general intelligence. Additionally, we present comprehensive insights from our management of a large-scale annotation process, involving over 80 expert annotators and an interactive Human-LLM collaborative system, offering valuable methodological guidance for future research initiatives of comparable scope.
Building a Family of Data Augmentation Models for Low-cost LLM Fine-tuning on the Cloud
Dec 06, 2024



Specializing LLMs in various domain-specific tasks has emerged as a critical step towards achieving high performance. However, the construction and annotation of datasets in specific domains are always very costly. Apart from using superior and expensive closed-source LLM APIs to construct datasets, some open-source models have become strong enough to handle dataset construction in many scenarios. Thus, we present a family of data augmentation models designed to significantly improve the efficiency for model fine-tuning. These models, trained based on sufficiently small LLMs, support key functionalities with low inference costs: instruction expansion, instruction refinement, and instruction-response pair expansion. To fulfill this goal, we first construct an automatic data collection system with seed datasets generated from both public repositories and our in-house datasets. This system leverages powerful LLMs to expand, refine and re-write the instructions and responses, incorporating quality assessment techniques. Following this, we introduce the training process of our models, which effectively distills task-solving and text synthesis abilities from teacher LLMs. Finally, we demonstrate how we integrate these functionalities into a machine learning platform to support low-cost LLM fine-tuning from both dataset preparation and training perspectives for users. Experiments and an application study prove the effectiveness of our approach.
Distilling Instruction-following Abilities of Large Language Models with Task-aware Curriculum Planning
May 22, 2024



The process of instruction tuning aligns pre-trained large language models (LLMs) with open-domain instructions and human-preferred responses. While several studies have explored autonomous approaches to distilling and annotating instructions from more powerful proprietary LLMs, such as ChatGPT, they often neglect the impact of task distributions and the varying difficulty of instructions of the training sets. This oversight can lead to imbalanced knowledge capabilities and poor generalization powers of small student LLMs. To address this challenge, we introduce Task-Aware Curriculum Planning for Instruction Refinement (TAPIR), a multi-round distillation framework with balanced task distributions and dynamic difficulty adjustment. This approach utilizes an oracle LLM to select instructions that are difficult for a student LLM to follow and distill instructions with balanced task distributions. By incorporating curriculum planning, our approach systematically escalates the difficulty levels, progressively enhancing the student LLM's capabilities. We rigorously evaluate TAPIR using two widely recognized benchmarks, including AlpacaEval 2.0 and MT-Bench. The empirical results demonstrate that the student LLMs, trained with our method and less training data, outperform larger instruction-tuned models and strong distillation baselines. The improvement is particularly notable in complex tasks, such as logical reasoning and code generation.
Survey on Factuality in Large Language Models: Knowledge, Retrieval and Domain-Specificity
Oct 18, 2023



This survey addresses the crucial issue of factuality in Large Language Models (LLMs). As LLMs find applications across diverse domains, the reliability and accuracy of their outputs become vital. We define the Factuality Issue as the probability of LLMs to produce content inconsistent with established facts. We first delve into the implications of these inaccuracies, highlighting the potential consequences and challenges posed by factual errors in LLM outputs. Subsequently, we analyze the mechanisms through which LLMs store and process facts, seeking the primary causes of factual errors. Our discussion then transitions to methodologies for evaluating LLM factuality, emphasizing key metrics, benchmarks, and studies. We further explore strategies for enhancing LLM factuality, including approaches tailored for specific domains. We focus two primary LLM configurations standalone LLMs and Retrieval-Augmented LLMs that utilizes external data, we detail their unique challenges and potential enhancements. Our survey offers a structured guide for researchers aiming to fortify the factual reliability of LLMs.
An End-to-End Network for Co-Saliency Detection in One Single Image
Oct 25, 2019



As a common visual problem, co-saliency detection within a single image does not attract enough attention and yet has not been well addressed. Existing methods often follow a bottom-up strategy to infer co-saliency in an image, where salient regions are firstly detected using visual primitives such as color and shape, and then grouped and merged into a co-saliency map. However, co-saliency is intrinsically perceived in a complex manner with bottom-up and top-down strategies combined in human vision. To deal with this problem, a novel end-to-end trainable network is proposed in this paper, which includes a backbone net and two branch nets. The backbone net uses ground-truth masks as top-down guidance for saliency prediction, while the two branch nets construct triplet proposals for feature organization and clustering, which drives the network to be sensitive to co-salient regions in a bottom-up way. To evaluate the proposed method, we construct a new dataset of 2,019 nature images with co-saliency in each image. Experimental results show that the proposed method achieves a state-of-the-art accuracy with a running speed of 28fps.
Robust Lane Detection from Continuous Driving Scenes Using Deep Neural Networks
Mar 06, 2019
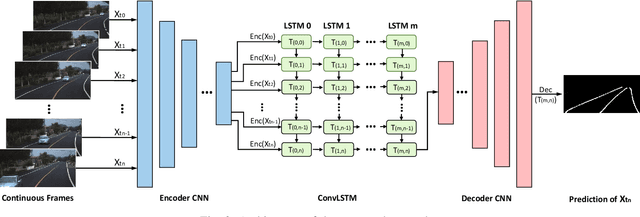


Lane detection in driving scenes is an important module for autonomous vehicles and advanced driver assistance systems. In recent years, many sophisticated lane detection methods have been proposed. However, most methods focus on detecting the lane from one single image, and often lead to unsatisfactory performance in handling some extremely-bad situations such as heavy shadow, severe mark degradation, serious vehicle occlusion, and so on. In fact, lanes are continuous line structures on the road. Consequently, the lane that cannot be accurately detected in one current frame may potentially be inferred out by incorporating information of previous frames. To this end, we investigate lane detection by using multiple frames of a continuous driving scene, and propose a hybrid deep architecture by combining the convolutional neural network (CNN) and the recurrent neural network (RNN). Specifically, information of each frame is abstracted by a CNN block, and the CNN features of multiple continuous frames, holding the property of time-series, are then fed into the RNN block for feature learning and lane prediction. Extensive experiments on two large-scale datasets demonstrate that, the proposed method outperforms the competing methods in lane detection, especially in handling difficult situations.