 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLong Context Scaling: Divide and Conquer via Multi-Agent Question-driven Collaboration
May 27, 2025Processing long contexts has become a critical capability for modern large language models (LLMs). Existing works leverage agent-based divide-and-conquer methods for processing long contexts. But these methods face crucial limitations, including prohibitive accumulated latency and amplified information loss from excessive agent invocations, and the disruption of inherent textual dependencies by immoderate partitioning. In this paper, we propose a novel multi-agent framework XpandA (Expand-Agent) coupled with question-driven workflow and dynamic partitioning for robust long-context processing. XpandA overcomes these limitations through: 1) dynamic partitioning of long texts, which adaptively modulates the filling rate of context windows for input sequences of vastly varying lengths; 2) question-guided protocol to update flat information ensembles within centralized shared memory, constructing consistent inter-agent knowledge across partitions; and 3) selectively replaying specific partitions based on the state-tracking of question-information couples to promote the resolution of inverted-order structures across partitions (e.g., flashbacks). We perform a comprehensive evaluation of XpandA on multiple long-context benchmarks with length varying from 1k to 1M, demonstrating XpandA's feasibility for processing ultra-long sequences and its significant effectiveness in enhancing the long-context capabilities of various LLMs by achieving 20\% improvements and 1.5x inference speedup over baselines of full-context, RAG and previous agent-based methods.
Survey on Factuality in Large Language Models: Knowledge, Retrieval and Domain-Specificity
Oct 18, 2023



This survey addresses the crucial issue of factuality in Large Language Models (LLMs). As LLMs find applications across diverse domains, the reliability and accuracy of their outputs become vital. We define the Factuality Issue as the probability of LLMs to produce content inconsistent with established facts. We first delve into the implications of these inaccuracies, highlighting the potential consequences and challenges posed by factual errors in LLM outputs. Subsequently, we analyze the mechanisms through which LLMs store and process facts, seeking the primary causes of factual errors. Our discussion then transitions to methodologies for evaluating LLM factuality, emphasizing key metrics, benchmarks, and studies. We further explore strategies for enhancing LLM factuality, including approaches tailored for specific domains. We focus two primary LLM configurations standalone LLMs and Retrieval-Augmented LLMs that utilizes external data, we detail their unique challenges and potential enhancements. Our survey offers a structured guide for researchers aiming to fortify the factual reliability of LLMs.
FactMix: Using a Few Labeled In-domain Examples to Generalize to Cross-domain Named Entity Recognition
Aug 24, 2022


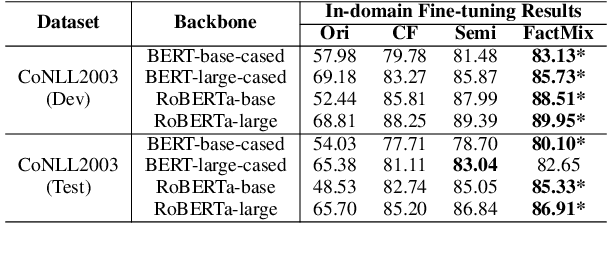
Few-shot Named Entity Recognition (NER) is imperative for entity tagging in limited resource domains and thus received proper attention in recent years. Existing approaches for few-shot NER are evaluated mainly under in-domain settings. In contrast, little is known about how these inherently faithful models perform in cross-domain NER using a few labeled in-domain examples. This paper proposes a two-step rationale-centric data augmentation method to improve the model's generalization ability. Results on several datasets show that our model-agnostic method significantly improves the performance of cross-domain NER tasks compared to previous state-of-the-art methods, including the counterfactual data augmentation and prompt-tuning methods. Our codes are available at \url{https://github.com/lifan-yuan/FactMix}.
Open Information Extraction from 2007 to 2022 -- A Survey
Aug 18, 2022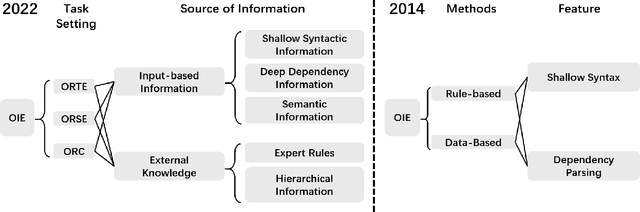
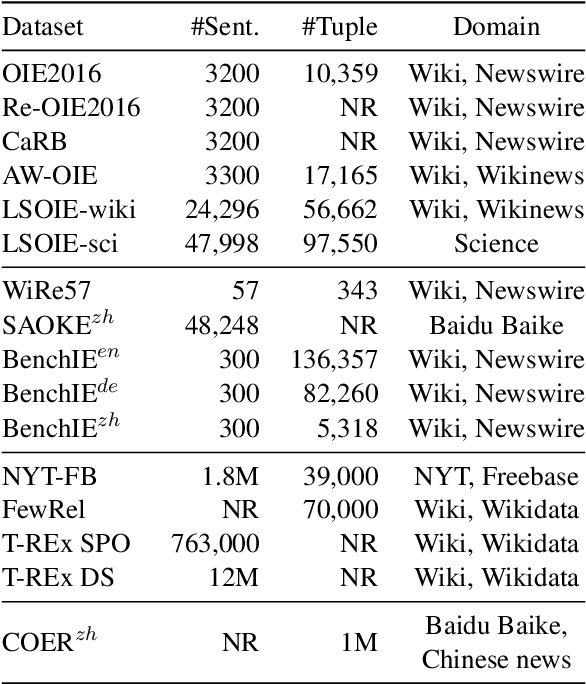
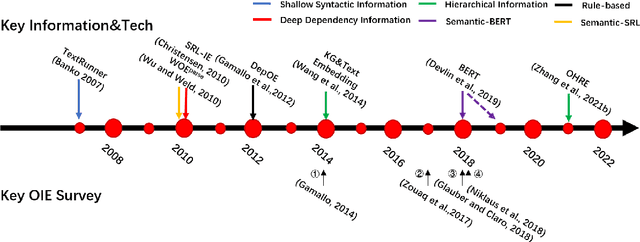
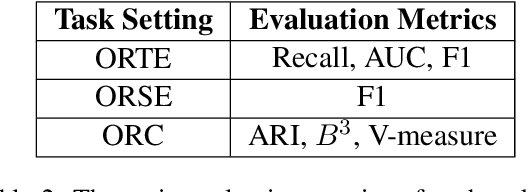
Open information extraction is an important NLP task that targets extracting structured information from unstructured text without limitations on the relation type or the domain of the text. This survey paper covers open information extraction technologies from 2007 to 2022 with a focus on new models not covered by previous surveys. We propose a new categorization method from the source of information perspective to accommodate the development of recent OIE technologies. In addition, we summarize three major approaches based on task settings as well as current popular datasets and model evaluation metrics. Given the comprehensive review, several future directions are shown from datasets, source of information, output form, method, and evaluation metric aspects.
RockNER: A Simple Method to Create Adversarial Examples for Evaluating the Robustness of Named Entity Recognition Models
Sep 12, 2021

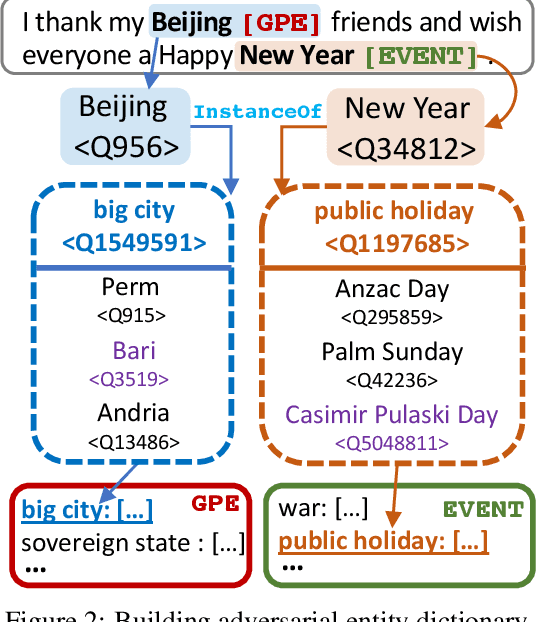
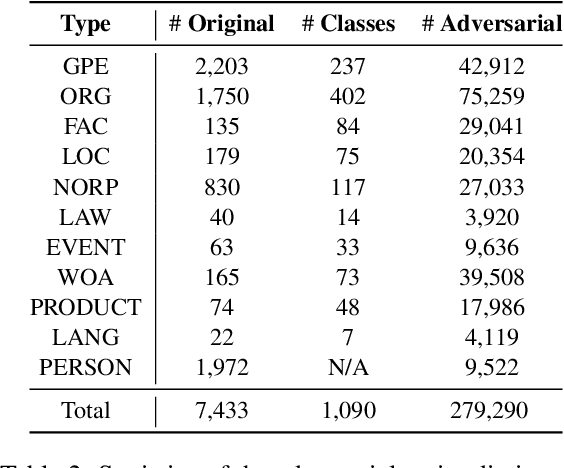
To audit the robustness of named entity recognition (NER) models, we propose RockNER, a simple yet effective method to create natural adversarial examples. Specifically, at the entity level, we replace target entities with other entities of the same semantic class in Wikidata; at the context level, we use pre-trained language models (e.g., BERT) to generate word substitutions. Together, the two levels of attack produce natural adversarial examples that result in a shifted distribution from the training data on which our target models have been trained. We apply the proposed method to the OntoNotes dataset and create a new benchmark named OntoRock for evaluating the robustness of existing NER models via a systematic evaluation protocol. Our experiments and analysis reveal that even the best model has a significant performance drop, and these models seem to memorize in-domain entity patterns instead of reasoning from the context. Our work also studies the effects of a few simple data augmentation methods to improve the robustness of NER models.