 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRockNER: A Simple Method to Create Adversarial Examples for Evaluating the Robustness of Named Entity Recognition Models
Sep 12, 2021

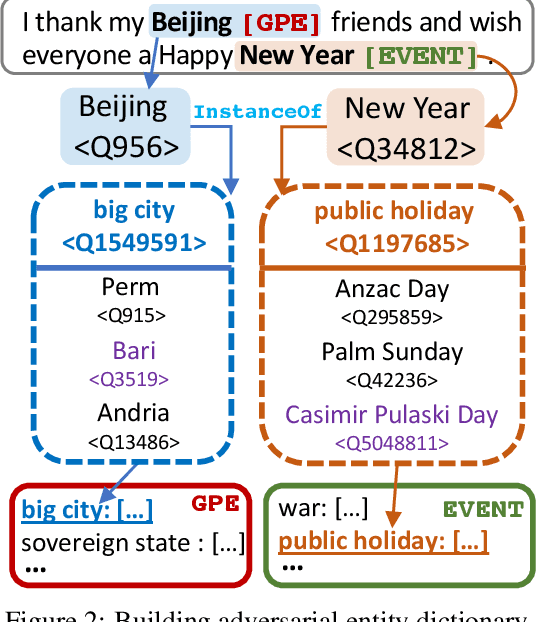
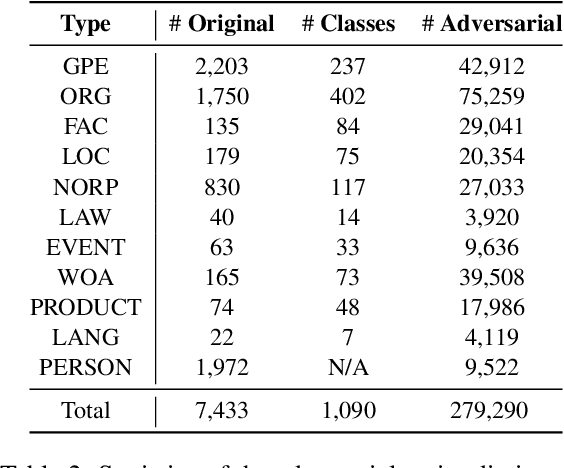
To audit the robustness of named entity recognition (NER) models, we propose RockNER, a simple yet effective method to create natural adversarial examples. Specifically, at the entity level, we replace target entities with other entities of the same semantic class in Wikidata; at the context level, we use pre-trained language models (e.g., BERT) to generate word substitutions. Together, the two levels of attack produce natural adversarial examples that result in a shifted distribution from the training data on which our target models have been trained. We apply the proposed method to the OntoNotes dataset and create a new benchmark named OntoRock for evaluating the robustness of existing NER models via a systematic evaluation protocol. Our experiments and analysis reveal that even the best model has a significant performance drop, and these models seem to memorize in-domain entity patterns instead of reasoning from the context. Our work also studies the effects of a few simple data augmentation methods to improve the robustness of NER models.
TriggerNER: Learning with Entity Triggers as Explanations for Named Entity Recognition
Apr 24, 2020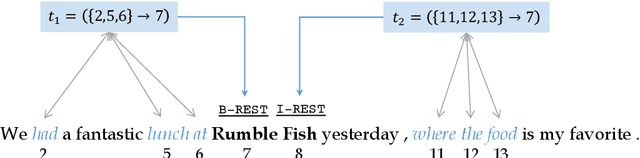
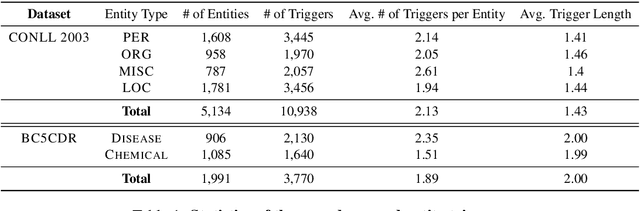
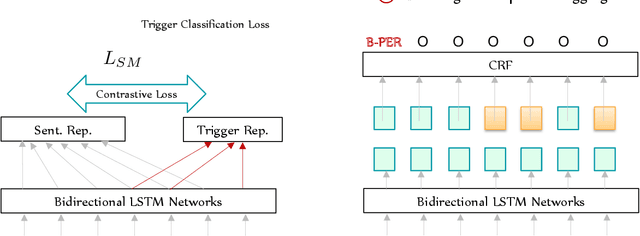
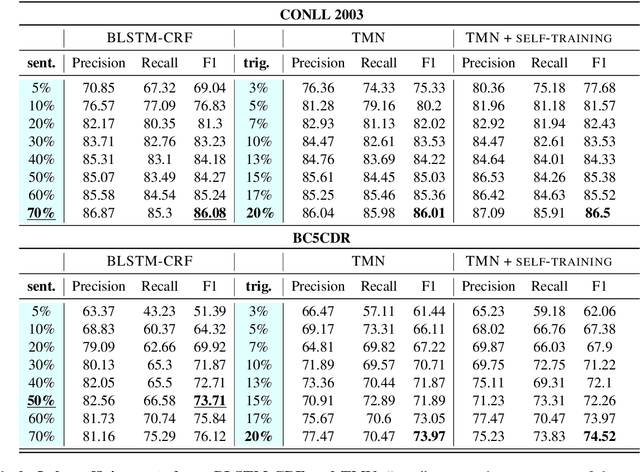
Training neural models for named entity recognition (NER) in a new domain often requires additional human annotations (e.g., tens of thousands of labeled instances) that are usually expensive and time-consuming to collect. Thus, a crucial research question is how to obtain supervision in a cost-effective way. In this paper, we introduce "entity triggers," an effective proxy of human explanations for facilitating label-efficient learning of NER models. An entity trigger is defined as a group of words in a sentence that helps to explain why humans would recognize an entity in the sentence. We crowd-sourced 14k entity triggers for two well-studied NER datasets. Our proposed model, Trigger Matching Network, jointly learns trigger representations and soft matching module with self-attention such that can generalize to unseen sentences easily for tagging. Our framework is significantly more cost-effective than the traditional neural NER frameworks. Experiments show that using only 20% of the trigger-annotated sentences results in a comparable performance as using 70% of conventional annotated sentences.