 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRefracGS: Novel View Synthesis Through Refractive Water Surfaces with 3D Gaussian Ray Tracing
Mar 23, 2026Novel view synthesis (NVS) through non-planar refractive surfaces presents fundamental challenges due to severe, spatially varying optical distortions. While recent representations like NeRF and 3D Gaussian Splatting (3DGS) excel at NVS, their assumption of straight-line ray propagation fails under these conditions, leading to significant artifacts. To overcome this limitation, we introduce RefracGS, a framework that jointly reconstructs the refractive water surface and the scene beneath the interface. Our key insight is to explicitly decouple the refractive boundary from the target objects: the refractive surface is modeled via a neural height field, capturing wave geometry, while the underlying scene is represented as a 3D Gaussian field. We formulate a refraction-aware Gaussian ray tracing approach that accurately computes non-linear ray trajectories using Snell's law and efficiently renders the underlying Gaussian field while backpropagating the loss gradients to the parameterized refractive surface. Through end-to-end joint optimization of both representations, our method ensures high-fidelity NVS and view-consistent surface recovery. Experiments on both synthetic and real-world scenes with complex waves demonstrate that RefracGS outperforms prior refractive methods in visual quality, while achieving 15x faster training and real-time rendering at 200 FPS. The project page for RefracGS is available at https://yimgshao.github.io/refracgs/.
Robust Single-shot Structured Light 3D Imaging via Neural Feature Decoding
Dec 16, 2025We consider the problem of active 3D imaging using single-shot structured light systems, which are widely employed in commercial 3D sensing devices such as Apple Face ID and Intel RealSense. Traditional structured light methods typically decode depth correspondences through pixel-domain matching algorithms, resulting in limited robustness under challenging scenarios like occlusions, fine-structured details, and non-Lambertian surfaces. Inspired by recent advances in neural feature matching, we propose a learning-based structured light decoding framework that performs robust correspondence matching within feature space rather than the fragile pixel domain. Our method extracts neural features from the projected patterns and captured infrared (IR) images, explicitly incorporating their geometric priors by building cost volumes in feature space, achieving substantial performance improvements over pixel-domain decoding approaches. To further enhance depth quality, we introduce a depth refinement module that leverages strong priors from large-scale monocular depth estimation models, improving fine detail recovery and global structural coherence. To facilitate effective learning, we develop a physically-based structured light rendering pipeline, generating nearly one million synthetic pattern-image pairs with diverse objects and materials for indoor settings. Experiments demonstrate that our method, trained exclusively on synthetic data with multiple structured light patterns, generalizes well to real-world indoor environments, effectively processes various pattern types without retraining, and consistently outperforms both commercial structured light systems and passive stereo RGB-based depth estimation methods. Project page: https://namisntimpot.github.io/NSLweb/.
RainyGS: Efficient Rain Synthesis with Physically-Based Gaussian Splatting
Mar 27, 2025We consider the problem of adding dynamic rain effects to in-the-wild scenes in a physically-correct manner. Recent advances in scene modeling have made significant progress, with NeRF and 3DGS techniques emerging as powerful tools for reconstructing complex scenes. However, while effective for novel view synthesis, these methods typically struggle with challenging scene editing tasks, such as physics-based rain simulation. In contrast, traditional physics-based simulations can generate realistic rain effects, such as raindrops and splashes, but they often rely on skilled artists to carefully set up high-fidelity scenes. This process lacks flexibility and scalability, limiting its applicability to broader, open-world environments. In this work, we introduce RainyGS, a novel approach that leverages the strengths of both physics-based modeling and 3DGS to generate photorealistic, dynamic rain effects in open-world scenes with physical accuracy. At the core of our method is the integration of physically-based raindrop and shallow water simulation techniques within the fast 3DGS rendering framework, enabling realistic and efficient simulations of raindrop behavior, splashes, and reflections. Our method supports synthesizing rain effects at over 30 fps, offering users flexible control over rain intensity -- from light drizzles to heavy downpours. We demonstrate that RainyGS performs effectively for both real-world outdoor scenes and large-scale driving scenarios, delivering more photorealistic and physically-accurate rain effects compared to state-of-the-art methods. Project page can be found at https://pku-vcl-geometry.github.io/RainyGS/
4D Gaussian Splatting: Towards Efficient Novel View Synthesis for Dynamic Scenes
Feb 07, 2024We consider the problem of novel view synthesis (NVS) for dynamic scenes. Recent neural approaches have accomplished exceptional NVS results for static 3D scenes, but extensions to 4D time-varying scenes remain non-trivial. Prior efforts often encode dynamics by learning a canonical space plus implicit or explicit deformation fields, which struggle in challenging scenarios like sudden movements or capturing high-fidelity renderings. In this paper, we introduce 4D Gaussian Splatting (4DGS), a novel method that represents dynamic scenes with anisotropic 4D XYZT Gaussians, inspired by the success of 3D Gaussian Splatting in static scenes. We model dynamics at each timestamp by temporally slicing the 4D Gaussians, which naturally compose dynamic 3D Gaussians and can be seamlessly projected into images. As an explicit spatial-temporal representation, 4DGS demonstrates powerful capabilities for modeling complicated dynamics and fine details, especially for scenes with abrupt motions. We further implement our temporal slicing and splatting techniques in a highly optimized CUDA acceleration framework, achieving real-time inference rendering speeds of up to 277 FPS on an RTX 3090 GPU and 583 FPS on an RTX 4090 GPU. Rigorous evaluations on scenes with diverse motions showcase the superior efficiency and effectiveness of 4DGS, which consistently outperforms existing methods both quantitatively and qualitatively.
STOPNet: Multiview-based 6-DoF Suction Detection for Transparent Objects on Production Lines
Oct 09, 2023



In this work, we present STOPNet, a framework for 6-DoF object suction detection on production lines, with a focus on but not limited to transparent objects, which is an important and challenging problem in robotic systems and modern industry. Current methods requiring depth input fail on transparent objects due to depth cameras' deficiency in sensing their geometry, while we proposed a novel framework to reconstruct the scene on the production line depending only on RGB input, based on multiview stereo. Compared to existing works, our method not only reconstructs the whole 3D scene in order to obtain high-quality 6-DoF suction poses in real time but also generalizes to novel environments, novel arrangements and novel objects, including challenging transparent objects, both in simulation and the real world. Extensive experiments in simulation and the real world show that our method significantly surpasses the baselines and has better generalizability, which caters to practical industrial needs.
GraspNeRF: Multiview-based 6-DoF Grasp Detection for Transparent and Specular Objects Using Generalizable NeRF
Oct 12, 2022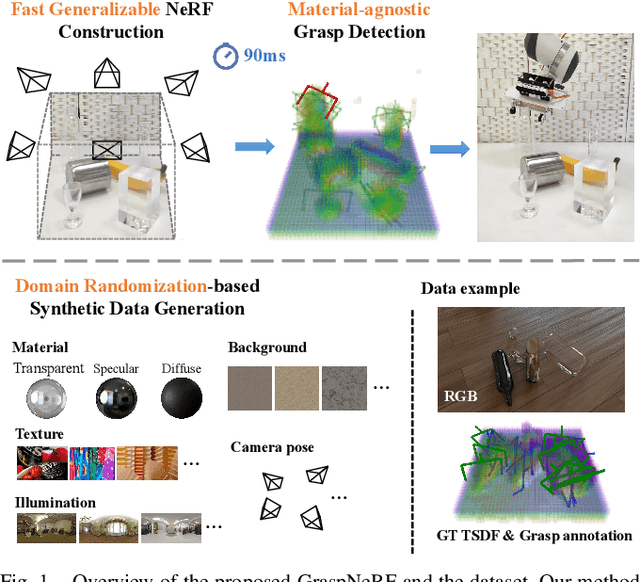
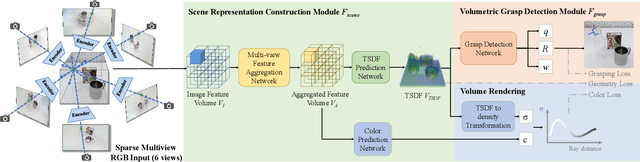
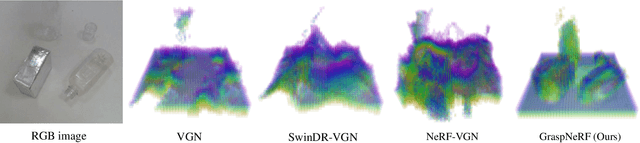
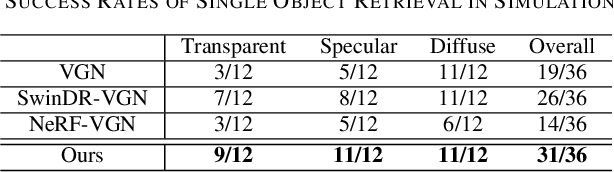
In this work, we tackle 6-DoF grasp detection for transparent and specular objects, which is an important yet challenging problem in vision-based robotic systems, due to the failure of depth cameras in sensing their geometry. We, for the first time, propose a multiview RGB-based 6-DoF grasp detection network, GraspNeRF, that leverages the generalizable neural radiance field (NeRF) to achieve material-agnostic object grasping in clutter. Compared to the existing NeRF-based 3-DoF grasp detection methods that rely on densely captured input images and time-consuming per-scene optimization, our system can perform zero-shot NeRF construction with sparse RGB inputs and reliably detect 6-DoF grasps, both in real-time. The proposed framework jointly learns generalizable NeRF and grasp detection in an end-to-end manner, optimizing the scene representation construction for the grasping. For training data, we generate a large-scale photorealistic domain-randomized synthetic dataset of grasping in cluttered tabletop scenes that enables direct transfer to the real world. Our extensive experiments in synthetic and real-world environments demonstrate that our method significantly outperforms all the baselines in all the experiments while remaining in real-time.
Domain Randomization-Enhanced Depth Simulation and Restoration for Perceiving and Grasping Specular and Transparent Objects
Aug 07, 2022Commercial depth sensors usually generate noisy and missing depths, especially on specular and transparent objects, which poses critical issues to downstream depth or point cloud-based tasks. To mitigate this problem, we propose a powerful RGBD fusion network, SwinDRNet, for depth restoration. We further propose Domain Randomization-Enhanced Depth Simulation (DREDS) approach to simulate an active stereo depth system using physically based rendering and generate a large-scale synthetic dataset that contains 130K photorealistic RGB images along with their simulated depths carrying realistic sensor noises. To evaluate depth restoration methods, we also curate a real-world dataset, namely STD, that captures 30 cluttered scenes composed of 50 objects with different materials from specular, transparent, to diffuse. Experiments demonstrate that the proposed DREDS dataset bridges the sim-to-real domain gap such that, trained on DREDS, our SwinDRNet can seamlessly generalize to other real depth datasets, e.g. ClearGrasp, and outperform the competing methods on depth restoration with a real-time speed. We further show that our depth restoration effectively boosts the performance of downstream tasks, including category-level pose estimation and grasping tasks. Our data and code are available at https://github.com/PKU-EPIC/DREDS
Robust Lane Detection from Continuous Driving Scenes Using Deep Neural Networks
Mar 06, 2019
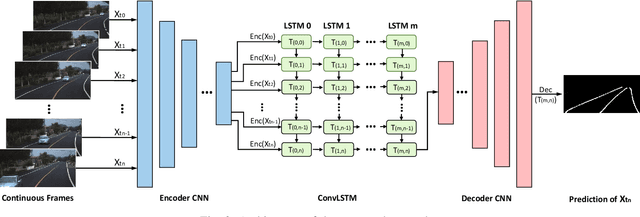


Lane detection in driving scenes is an important module for autonomous vehicles and advanced driver assistance systems. In recent years, many sophisticated lane detection methods have been proposed. However, most methods focus on detecting the lane from one single image, and often lead to unsatisfactory performance in handling some extremely-bad situations such as heavy shadow, severe mark degradation, serious vehicle occlusion, and so on. In fact, lanes are continuous line structures on the road. Consequently, the lane that cannot be accurately detected in one current frame may potentially be inferred out by incorporating information of previous frames. To this end, we investigate lane detection by using multiple frames of a continuous driving scene, and propose a hybrid deep architecture by combining the convolutional neural network (CNN) and the recurrent neural network (RNN). Specifically, information of each frame is abstracted by a CNN block, and the CNN features of multiple continuous frames, holding the property of time-series, are then fed into the RNN block for feature learning and lane prediction. Extensive experiments on two large-scale datasets demonstrate that, the proposed method outperforms the competing methods in lane detection, especially in handling difficult situations.