 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDenoiseFlow: Uncertainty-Aware Denoising for Reliable LLM Agentic Workflows
Feb 28, 2026Autonomous agents are increasingly entrusted with complex, long-horizon tasks, ranging from mathematical reasoning to software generation. While agentic workflows facilitate these tasks by decomposing them into multi-step reasoning chains, reliability degrades significantly as the sequence lengthens. Specifically, minor interpretation errors in natural-language instructions tend to compound silently across steps. We term this failure mode accumulated semantic ambiguity. Existing approaches to mitigate this often lack runtime adaptivity, relying instead on static exploration budgets, reactive error recovery, or single-path execution that ignores uncertainty entirely. We formalize the multi-step reasoning process as a Noisy MDP and propose DenoiseFlow, a closed-loop framework that performs progressive denoising through three coordinated stages: (1)Sensing estimates per-step semantic uncertainty; (2)Regulating adaptively allocates computation by routing between fast single-path execution and parallel exploration based on estimated risk; and (3)Correcting performs targeted recovery via influence-based root-cause localization. Online self-calibration continuously aligns decision boundaries with verifier feedback, requiring no ground-truth labels. Experiments on six benchmarks spanning mathematical reasoning, code generation, and multi-hop QA show that DenoiseFlow achieves the highest accuracy on every benchmark (83.3% average, +1.3% over the strongest baseline) while reducing cost by 40--56% through adaptive branching. Detailed ablation studies further confirm framework-level's robustness and generality. Code is available at https://anonymous.4open.science/r/DenoiseFlow-21D3/.
OMG-Agent: Toward Robust Missing Modality Generation with Decoupled Coarse-to-Fine Agentic Workflows
Feb 04, 2026Data incompleteness severely impedes the reliability of multimodal systems. Existing reconstruction methods face distinct bottlenecks: conventional parametric/generative models are prone to hallucinations due to over-reliance on internal memory, while retrieval-augmented frameworks struggle with retrieval rigidity. Critically, these end-to-end architectures are fundamentally constrained by Semantic-Detail Entanglement -- a structural conflict between logical reasoning and signal synthesis that compromises fidelity. In this paper, we present \textbf{\underline{O}}mni-\textbf{\underline{M}}odality \textbf{\underline{G}}eneration Agent (\textbf{OMG-Agent}), a novel framework that shifts the paradigm from static mapping to a dynamic coarse-to-fine Agentic Workflow. By mimicking a \textit{deliberate-then-act} cognitive process, OMG-Agent explicitly decouples the task into three synergistic stages: (1) an MLLM-driven Semantic Planner that resolves input ambiguity via Progressive Contextual Reasoning, creating a deterministic structured semantic plan; (2) a non-parametric Evidence Retriever that grounds abstract semantics in external knowledge; and (3) a Retrieval-Injected Executor that utilizes retrieved evidence as flexible feature prompts to overcome rigidity and synthesize high-fidelity details. Extensive experiments on multiple benchmarks demonstrate that OMG-Agent consistently surpasses state-of-the-art methods, maintaining robustness under extreme missingness, e.g., a $2.6$-point gain on CMU-MOSI at $70$\% missing rates.
SAMba-UNet: Synergizing SAM2 and Mamba in UNet with Heterogeneous Aggregation for Cardiac MRI Segmentation
May 22, 2025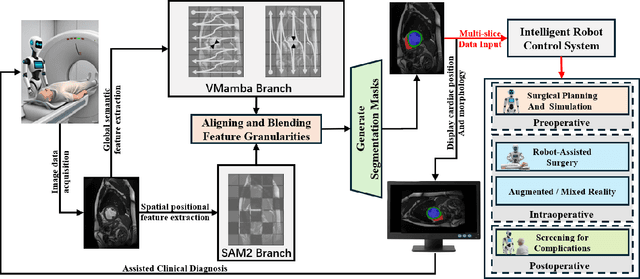



To address the challenge of complex pathological feature extraction in automated cardiac MRI segmentation, this study proposes an innovative dual-encoder architecture named SAMba-UNet. The framework achieves cross-modal feature collaborative learning by integrating the vision foundation model SAM2, the state-space model Mamba, and the classical UNet. To mitigate domain discrepancies between medical and natural images, a Dynamic Feature Fusion Refiner is designed, which enhances small lesion feature extraction through multi-scale pooling and a dual-path calibration mechanism across channel and spatial dimensions. Furthermore, a Heterogeneous Omni-Attention Convergence Module (HOACM) is introduced, combining global contextual attention with branch-selective emphasis mechanisms to effectively fuse SAM2's local positional semantics and Mamba's long-range dependency modeling capabilities. Experiments on the ACDC cardiac MRI dataset demonstrate that the proposed model achieves a Dice coefficient of 0.9103 and an HD95 boundary error of 1.0859 mm, significantly outperforming existing methods, particularly in boundary localization for complex pathological structures such as right ventricular anomalies. This work provides an efficient and reliable solution for automated cardiac disease diagnosis, and the code will be open-sourced.
DMS-Net:Dual-Modal Multi-Scale Siamese Network for Binocular Fundus Image Classification
Apr 25, 2025
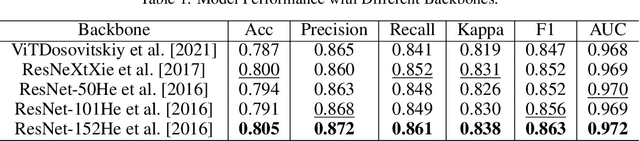
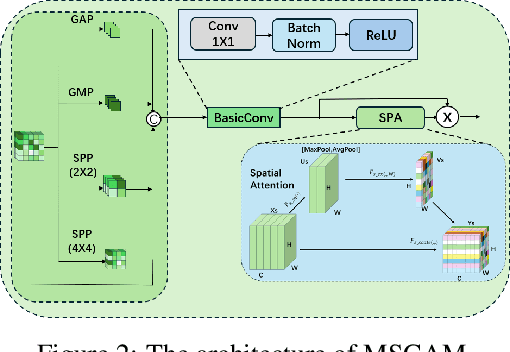
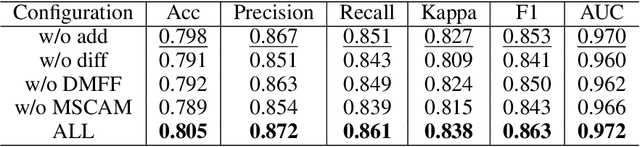
Ophthalmic diseases pose a significant global health challenge, yet traditional diagnosis methods and existing single-eye deep learning approaches often fail to account for binocular pathological correlations. To address this, we propose DMS-Net, a dual-modal multi-scale Siamese network for binocular fundus image classification. Our framework leverages weight-shared Siamese ResNet-152 backbones to extract deep semantic features from paired fundus images. To tackle challenges such as lesion boundary ambiguity and scattered pathological distributions, we introduce a Multi-Scale Context-Aware Module (MSCAM) that integrates adaptive pooling and attention mechanisms for multi-resolution feature aggregation. Additionally, a Dual-Modal Feature Fusion (DMFF) module enhances cross-modal interaction through spatial-semantic recalibration and bidirectional attention, effectively combining global context and local edge features. Evaluated on the ODIR-5K dataset, DMS-Net achieves state-of-the-art performance with 80.5% accuracy, 86.1% recall, and 83.8% Cohen's kappa, demonstrating superior capability in detecting symmetric pathologies and advancing clinical decision-making for ocular diseases.
Beyond Existance: Fulfill 3D Reconstructed Scenes with Pseudo Details
Mar 06, 2025The emergence of 3D Gaussian Splatting (3D-GS) has significantly advanced 3D reconstruction by providing high fidelity and fast training speeds across various scenarios. While recent efforts have mainly focused on improving model structures to compress data volume or reduce artifacts during zoom-in and zoom-out operations, they often overlook an underlying issue: training sampling deficiency. In zoomed-in views, Gaussian primitives can appear unregulated and distorted due to their dilation limitations and the insufficient availability of scale-specific training samples. Consequently, incorporating pseudo-details that ensure the completeness and alignment of the scene becomes essential. In this paper, we introduce a new training method that integrates diffusion models and multi-scale training using pseudo-ground-truth data. This approach not only notably mitigates the dilation and zoomed-in artifacts but also enriches reconstructed scenes with precise details out of existing scenarios. Our method achieves state-of-the-art performance across various benchmarks and extends the capabilities of 3D reconstruction beyond training datasets.
FE-UNet: Frequency Domain Enhanced U-Net with Segment Anything Capability for Versatile Image Segmentation
Feb 06, 2025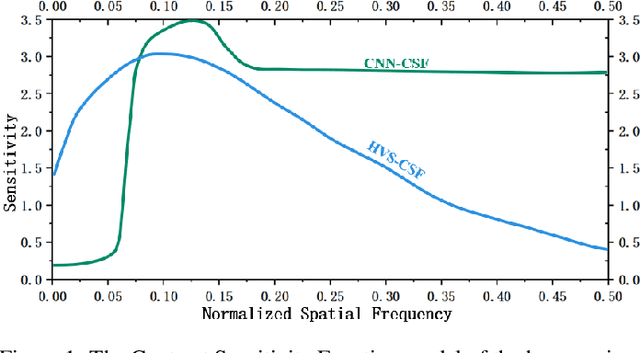

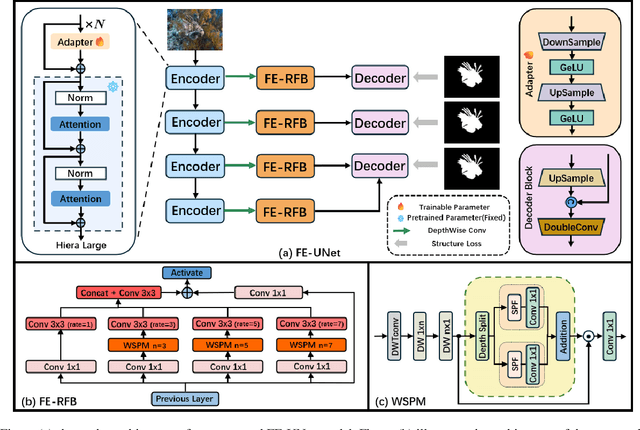

Image segmentation is a critical task in visual understanding. Convolutional Neural Networks (CNNs) are predisposed to capture high-frequency features in images, while Transformers exhibit a contrasting focus on low-frequency features. In this paper, we experimentally quantify the contrast sensitivity function of CNNs and compare it with that of the human visual system, informed by the seminal experiments of Mannos and Sakrison. Leveraging these insights, we propose the Wavelet-Guided Spectral Pooling Module (WSPM) to enhance and balance image features across the frequency domain. To further emulate the human visual system, we introduce the Frequency Domain Enhanced Receptive Field Block (FE-RFB), which integrates WSPM to extract enriched features from the frequency domain. Building on these innovations, we develop FE-UNet, a model that utilizes SAM2 as its backbone and incorporates Hiera-Large as a pre-trained block, designed to enhance generalization capabilities while ensuring high segmentation accuracy. Experimental results demonstrate that FE-UNet achieves state-of-the-art performance in diverse tasks, including marine animal and polyp segmentation, underscoring its versatility and effectiveness.
AADNet: Exploring EEG Spatiotemporal Information for Fast and Accurate Orientation and Timbre Detection of Auditory Attention Based on A Cue-Masked Paradigm
Jan 07, 2025Auditory attention decoding from electroencephalogram (EEG) could infer to which source the user is attending in noisy environments. Decoding algorithms and experimental paradigm designs are crucial for the development of technology in practical applications. To simulate real-world scenarios, this study proposed a cue-masked auditory attention paradigm to avoid information leakage before the experiment. To obtain high decoding accuracy with low latency, an end-to-end deep learning model, AADNet, was proposed to exploit the spatiotemporal information from the short time window of EEG signals. The results showed that with a 0.5-second EEG window, AADNet achieved an average accuracy of 93.46% and 91.09% in decoding auditory orientation attention (OA) and timbre attention (TA), respectively. It significantly outperformed five previous methods and did not need the knowledge of the original audio source. This work demonstrated that it was possible to detect the orientation and timbre of auditory attention from EEG signals fast and accurately. The results are promising for the real-time multi-property auditory attention decoding, facilitating the application of the neuro-steered hearing aids and other assistive listening devices.
MuAP: Multi-step Adaptive Prompt Learning for Vision-Language Model with Missing Modality
Sep 07, 2024



Recently, prompt learning has garnered considerable attention for its success in various Vision-Language (VL) tasks. However, existing prompt-based models are primarily focused on studying prompt generation and prompt strategies with complete modality settings, which does not accurately reflect real-world scenarios where partial modality information may be missing. In this paper, we present the first comprehensive investigation into prompt learning behavior when modalities are incomplete, revealing the high sensitivity of prompt-based models to missing modalities. To this end, we propose a novel Multi-step Adaptive Prompt Learning (MuAP) framework, aiming to generate multimodal prompts and perform multi-step prompt tuning, which adaptively learns knowledge by iteratively aligning modalities. Specifically, we generate multimodal prompts for each modality and devise prompt strategies to integrate them into the Transformer model. Subsequently, we sequentially perform prompt tuning from single-stage and alignment-stage, allowing each modality-prompt to be autonomously and adaptively learned, thereby mitigating the imbalance issue caused by only textual prompts that are learnable in previous works. Extensive experiments demonstrate the effectiveness of our MuAP and this model achieves significant improvements compared to the state-of-the-art on all benchmark datasets
Compensate Quantization Errors: Make Weights Hierarchical to Compensate Each Other
Jun 24, 2024Emergent Large Language Models (LLMs) use their extraordinary performance and powerful deduction capacity to discern from traditional language models. However, the expenses of computational resources and storage for these LLMs are stunning, quantization then arises as a trending conversation. To address accuracy decay caused by quantization, two streams of works in post-training quantization methods stand out. One uses other weights to compensate existing quantization error, while the other transfers the quantization difficulty to other parts in the model. Combining both merits, we introduce Learnable Singular value Increment (LSI) as an advanced solution. LSI uses Singular Value Decomposition to extract singular values of the weights and make them learnable to help weights compensate each other conditioned on activation. Incorporating LSI with existing techniques, we achieve state-of-the-art performance in diverse quantization settings, no matter in weight-only, weight-activation or extremely low bit scenarios. By unleashing the potential of LSI, efficient finetuning on quantized model is no longer a prohibitive problem.
G-SAP: Graph-based Structure-Aware Prompt Learning over Heterogeneous Knowledge for Commonsense Reasoning
May 09, 2024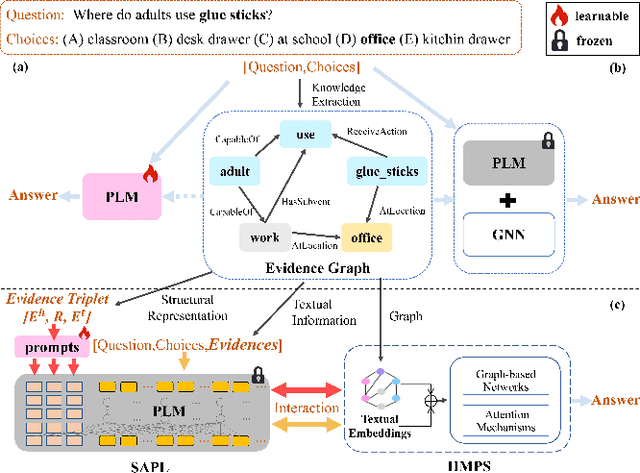
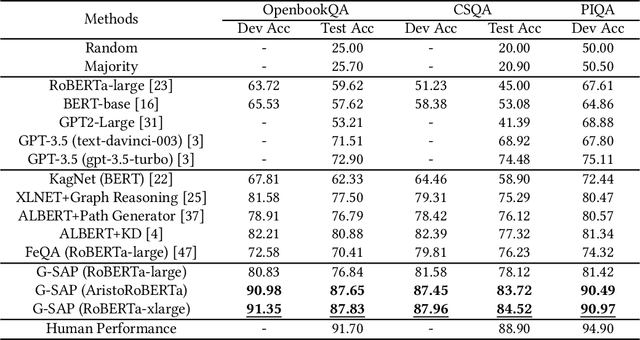
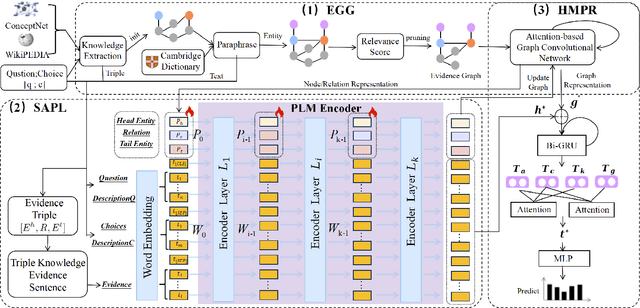
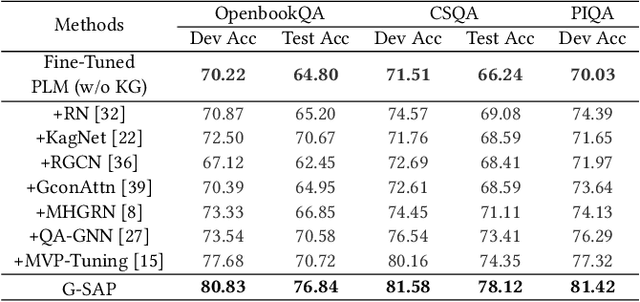
Commonsense question answering has demonstrated considerable potential across various applications like assistants and social robots. Although fully fine-tuned pre-trained Language Models(LM) have achieved remarkable performance in commonsense reasoning, their tendency to excessively prioritize textual information hampers the precise transfer of structural knowledge and undermines interpretability. Some studies have explored combining LMs with Knowledge Graphs(KGs) by coarsely fusing the two modalities to perform Graph Neural Network(GNN)-based reasoning that lacks a profound interaction between heterogeneous modalities. In this paper, we propose a novel Graph-based Structure-Aware Prompt Learning Model for commonsense reasoning, named G-SAP, aiming to maintain a balance between heterogeneous knowledge and enhance the cross-modal interaction within the LM+GNNs model. In particular, an evidence graph is constructed by integrating multiple knowledge sources, i.e. ConceptNet, Wikipedia, and Cambridge Dictionary to boost the performance. Afterward, a structure-aware frozen PLM is employed to fully incorporate the structured and textual information from the evidence graph, where the generation of prompts is driven by graph entities and relations. Finally, a heterogeneous message-passing reasoning module is used to facilitate deep interaction of knowledge between the LM and graph-based networks. Empirical validation, conducted through extensive experiments on three benchmark datasets, demonstrates the notable performance of the proposed model. The results reveal a significant advancement over the existing models, especially, with 6.12% improvement over the SoTA LM+GNNs model on the OpenbookQA dataset.