 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlashMemory-DeepSeek-V4: Lightning Index Ultra-Long Context via Lookahead Sparse Attention
Jun 09, 2026Conventional LLMs keep the full KV cache loaded during decoding, causing a severe GPU memory bottleneck for ultra-long context serving. In this report, we propose Lookahead Sparse Attention (LSA), a novel inference paradigm powered by a Neural Memory Indexer built upon the DeepSeek-V4 architecture. Rather than passively attending to all historical tokens, LSA proactively predicts future context demands and preserves only the query-critical KV chunks in the GPU memory. Crucially, we instantiate this architecture via a backbone-free decoupled training strategy. By formulating the indexer as a standard dual-encoder architecture, we train it independently using standard retrieval training frameworks without ever loading the massive backbone model into GPU memory. We demonstrate that this "less is more" paradigm significantly maximizes serving efficiency while acting as an effective attention denoiser in tasks that rely on long-term global memory. Across primary long-context evaluation suites (e.g., LongBench-v2, LongMemEval, and RULER), FM-DS-V4 compresses the average physical KV cache footprint down to merely 13.5% of the full-context baseline, while consistently preserving or slightly elevating downstream accuracy (+0.6% absolute margin on average). Crucially, at extreme 500K scales, FlashMemory suppresses the physical KV cache overhead by over 90% without destabilizing the backbone's core reasoning capacities.
DMS-Net:Dual-Modal Multi-Scale Siamese Network for Binocular Fundus Image Classification
Apr 25, 2025
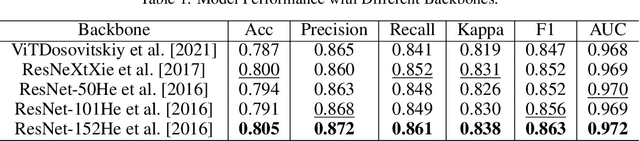
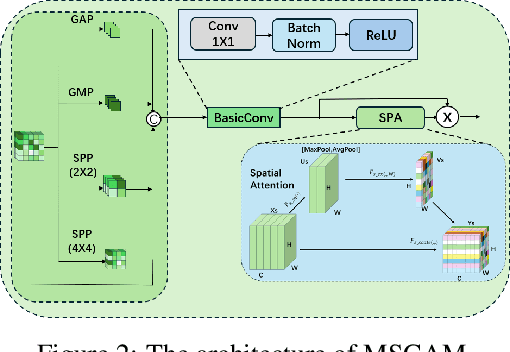
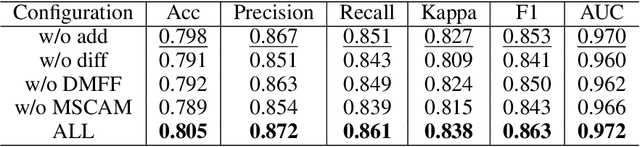
Ophthalmic diseases pose a significant global health challenge, yet traditional diagnosis methods and existing single-eye deep learning approaches often fail to account for binocular pathological correlations. To address this, we propose DMS-Net, a dual-modal multi-scale Siamese network for binocular fundus image classification. Our framework leverages weight-shared Siamese ResNet-152 backbones to extract deep semantic features from paired fundus images. To tackle challenges such as lesion boundary ambiguity and scattered pathological distributions, we introduce a Multi-Scale Context-Aware Module (MSCAM) that integrates adaptive pooling and attention mechanisms for multi-resolution feature aggregation. Additionally, a Dual-Modal Feature Fusion (DMFF) module enhances cross-modal interaction through spatial-semantic recalibration and bidirectional attention, effectively combining global context and local edge features. Evaluated on the ODIR-5K dataset, DMS-Net achieves state-of-the-art performance with 80.5% accuracy, 86.1% recall, and 83.8% Cohen's kappa, demonstrating superior capability in detecting symmetric pathologies and advancing clinical decision-making for ocular diseases.
When Video Classification Meets Incremental Classes
Jun 30, 2021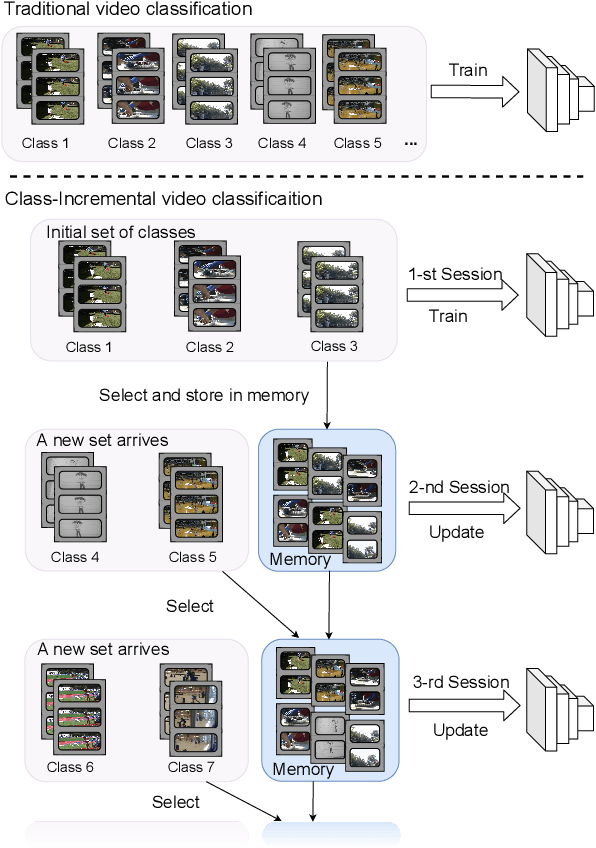

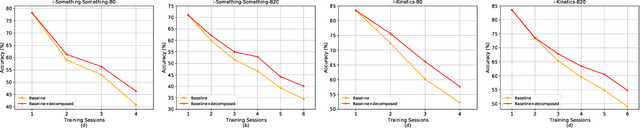
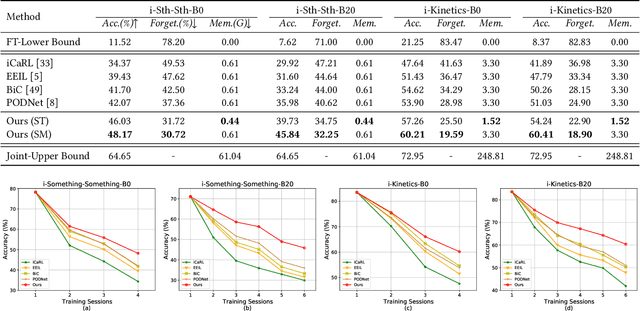
With the rapid development of social media, tremendous videos with new classes are generated daily, which raise an urgent demand for video classification methods that can continuously update new classes while maintaining the knowledge of old videos with limited storage and computing resources. In this paper, we summarize this task as \textit{Class-Incremental Video Classification (CIVC)} and propose a novel framework to address it. As a subarea of incremental learning tasks, the challenge of \textit{catastrophic forgetting} is unavoidable in CIVC. To better alleviate it, we utilize some characteristics of videos. First, we decompose the spatio-temporal knowledge before distillation rather than treating it as a whole in the knowledge transfer process; trajectory is also used to refine the decomposition. Second, we propose a dual granularity exemplar selection method to select and store representative video instances of old classes and key-frames inside videos under a tight storage budget. We benchmark our method and previous SOTA class-incremental learning methods on Something-Something V2 and Kinetics datasets, and our method outperforms previous methods significantly.
Dialogue Response Selection with Hierarchical Curriculum Learning
Dec 29, 2020
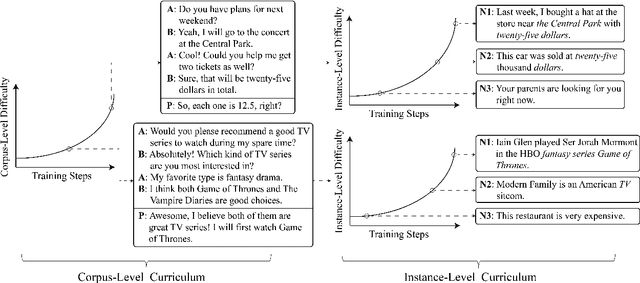
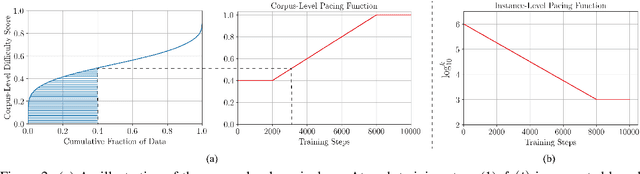
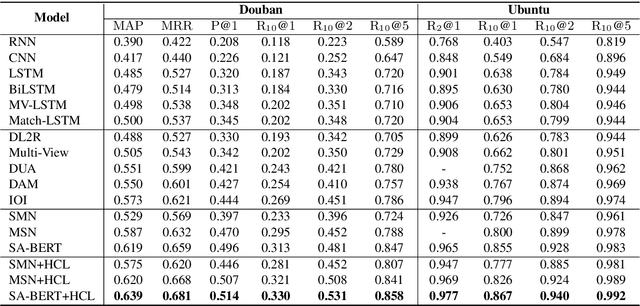
We study the learning of a matching model for dialogue response selection. Motivated by the recent finding that random negatives are often too trivial to train a reliable model, we propose a hierarchical curriculum learning (HCL) framework that consists of two complementary curricula: (1) corpus-level curriculum (CC); and (2) instance-level curriculum (IC). In CC, the model gradually increases its ability in finding the matching clues between the dialogue context and response. On the other hand, IC progressively strengthens the model's ability in identifying the mismatched information between the dialogue context and response. Empirical studies on two benchmark datasets with three state-of-the-art matching models demonstrate that the proposed HCL significantly improves the model performance across various evaluation metrics.
Grayscale Data Construction and Multi-Level Ranking Objective for Dialogue Response Selection
Apr 28, 2020
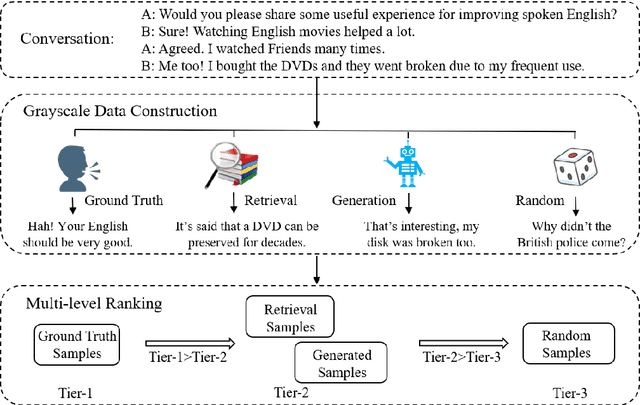
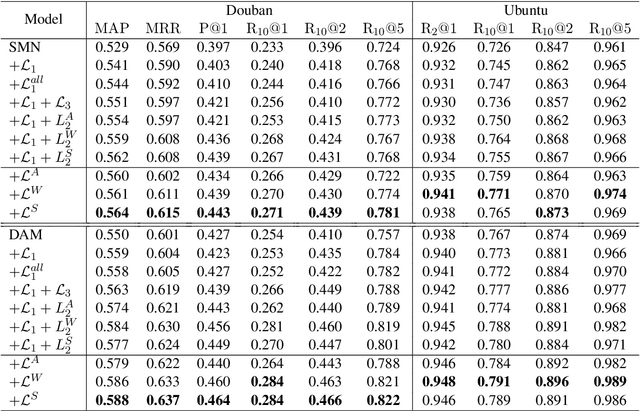
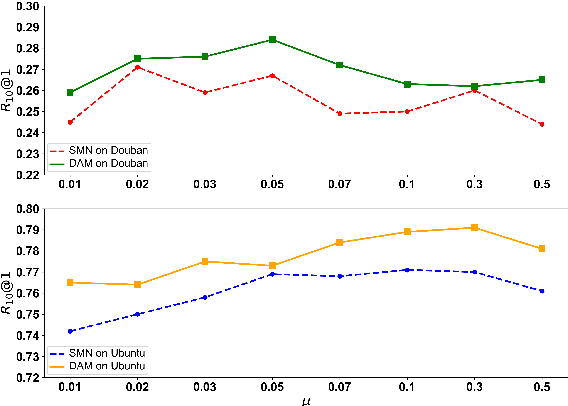
Response selection plays a vital role in building retrieval-based conversation systems. Recent works on enhancing response selection mainly focus on inventing new neural architectures for better modeling the relation between dialogue context and response candidates. In almost all these previous works, binary-labeled training data are assumed: Every response candidate is either positive (relevant) or negative (irrelevant). We propose to automatically build training data with grayscale labels. To make full use of the grayscale training data, we propose a multi-level ranking strategy. Experimental results on two benchmark datasets show that our new training strategy significantly improves performance over existing state-of-the-art matching models in terms of various evaluation metrics.