 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDialogue Response Selection with Hierarchical Curriculum Learning
Paper and Code

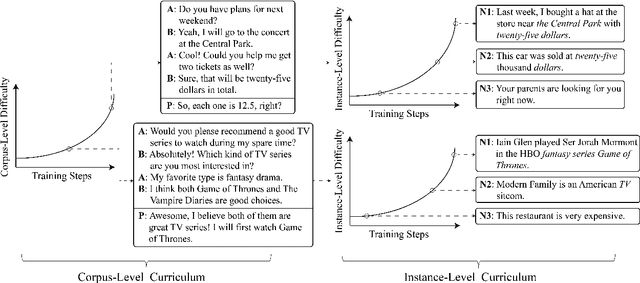
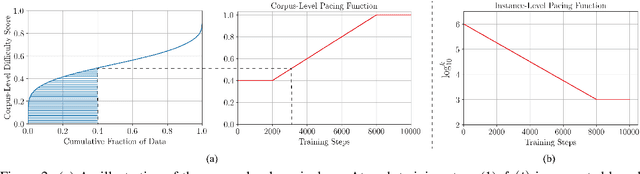
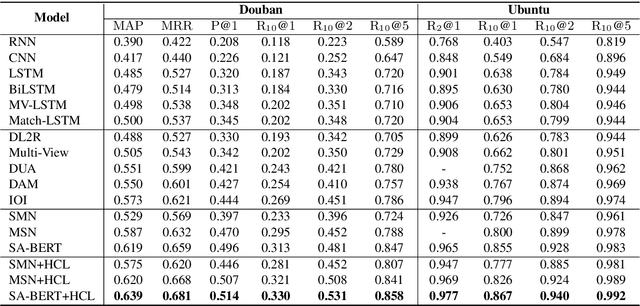
We study the learning of a matching model for dialogue response selection. Motivated by the recent finding that random negatives are often too trivial to train a reliable model, we propose a hierarchical curriculum learning (HCL) framework that consists of two complementary curricula: (1) corpus-level curriculum (CC); and (2) instance-level curriculum (IC). In CC, the model gradually increases its ability in finding the matching clues between the dialogue context and response. On the other hand, IC progressively strengthens the model's ability in identifying the mismatched information between the dialogue context and response. Empirical studies on two benchmark datasets with three state-of-the-art matching models demonstrate that the proposed HCL significantly improves the model performance across various evaluation metrics.