 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Rule-Based Insights Enhance LLMs for Radiology Report Classification? Introducing the RadPrompt Methodology
Aug 07, 2024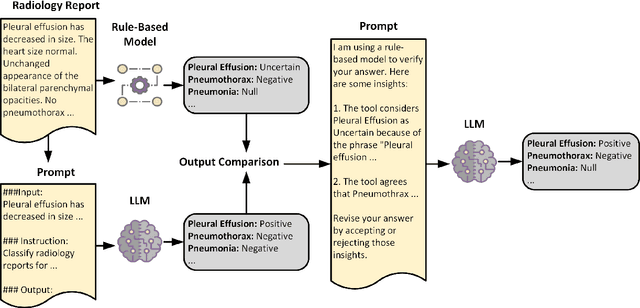
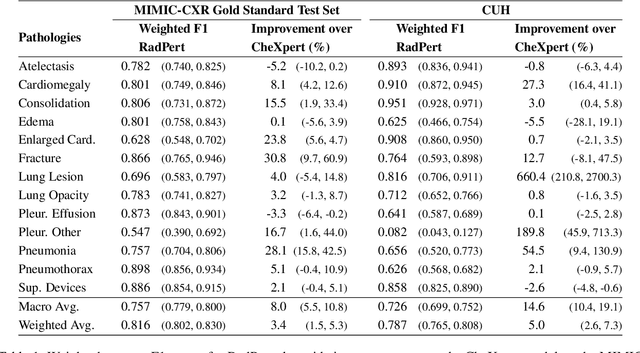
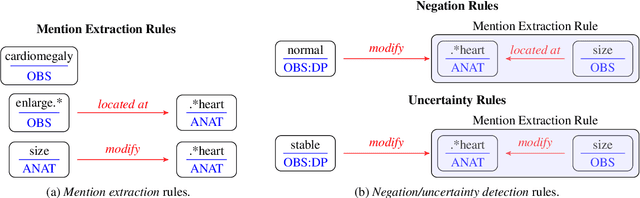
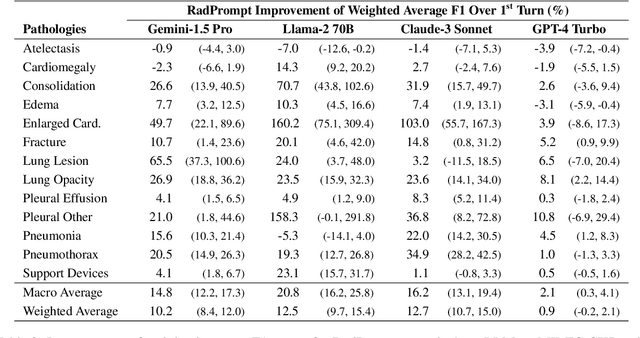
Developing imaging models capable of detecting pathologies from chest X-rays can be cost and time-prohibitive for large datasets as it requires supervision to attain state-of-the-art performance. Instead, labels extracted from radiology reports may serve as distant supervision since these are routinely generated as part of clinical practice. Despite their widespread use, current rule-based methods for label extraction rely on extensive rule sets that are limited in their robustness to syntactic variability. To alleviate these limitations, we introduce RadPert, a rule-based system that integrates an uncertainty-aware information schema with a streamlined set of rules, enhancing performance. Additionally, we have developed RadPrompt, a multi-turn prompting strategy that leverages RadPert to bolster the zero-shot predictive capabilities of large language models, achieving a statistically significant improvement in weighted average F1 score over GPT-4 Turbo. Most notably, RadPrompt surpasses both its underlying models, showcasing the synergistic potential of LLMs with rule-based models. We have evaluated our methods on two English Corpora: the MIMIC-CXR gold-standard test set and a gold-standard dataset collected from the Cambridge University Hospitals.
Few-Shot Table-to-Text Generation with Prototype Memory
Aug 31, 2021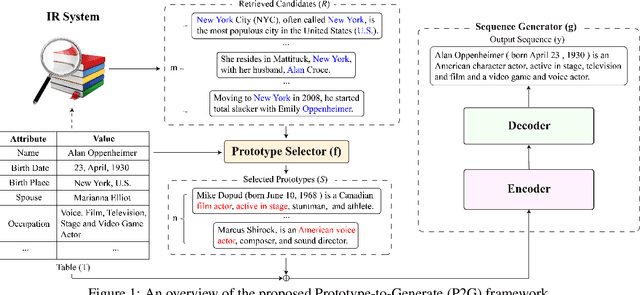
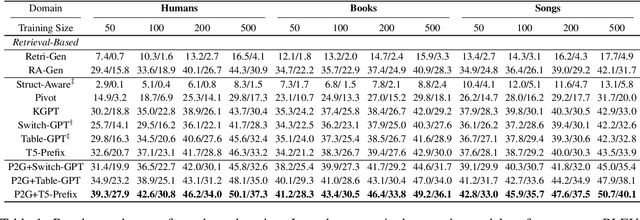
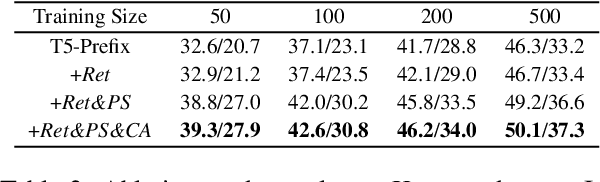
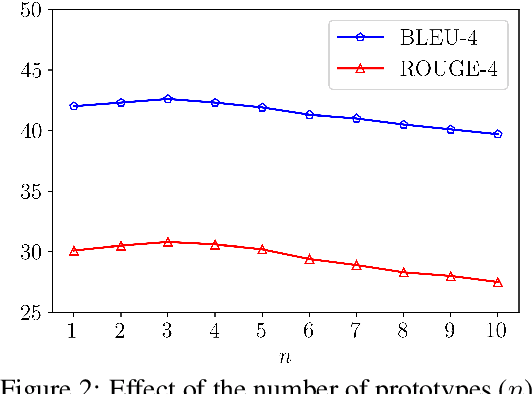
Neural table-to-text generation models have achieved remarkable progress on an array of tasks. However, due to the data-hungry nature of neural models, their performances strongly rely on large-scale training examples, limiting their applicability in real-world applications. To address this, we propose a new framework: Prototype-to-Generate (P2G), for table-to-text generation under the few-shot scenario. The proposed framework utilizes the retrieved prototypes, which are jointly selected by an IR system and a novel prototype selector to help the model bridging the structural gap between tables and texts. Experimental results on three benchmark datasets with three state-of-the-art models demonstrate that the proposed framework significantly improves the model performance across various evaluation metrics.
Non-Autoregressive Text Generation with Pre-trained Language Models
Feb 16, 2021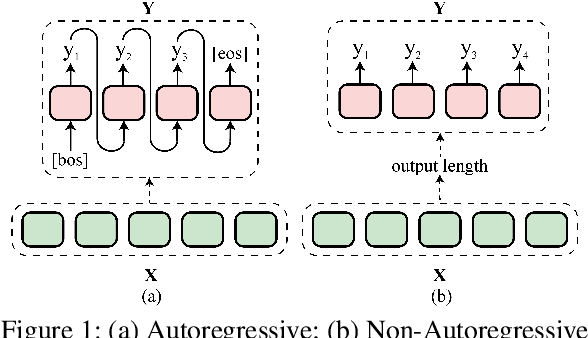
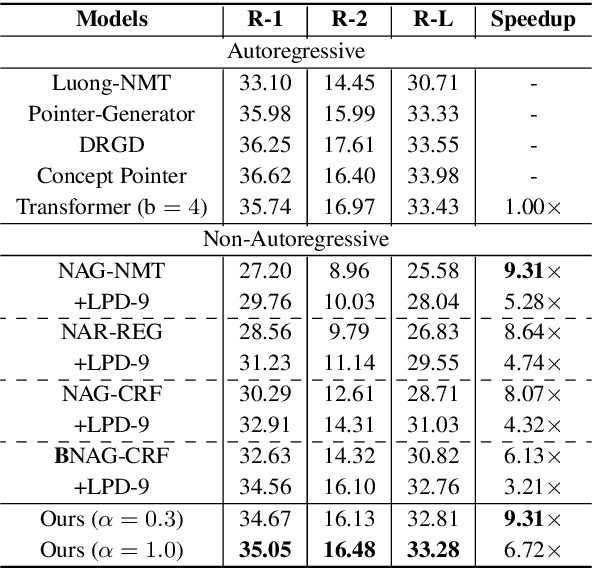
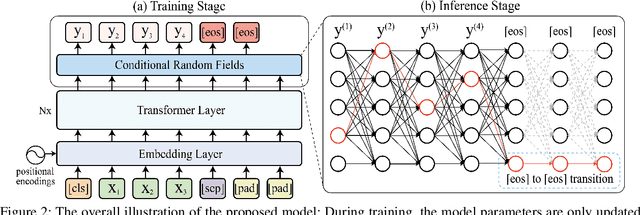
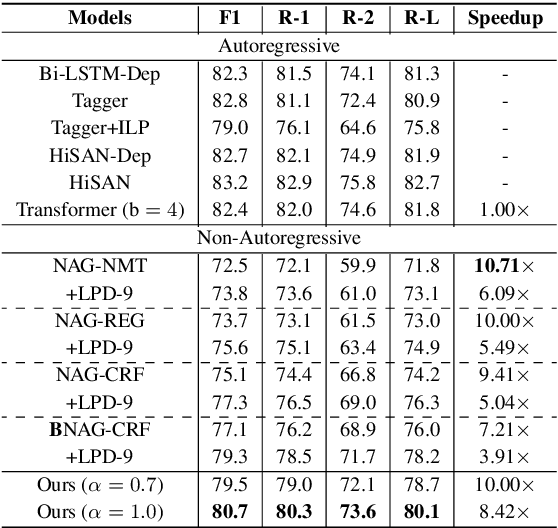
Non-autoregressive generation (NAG) has recently attracted great attention due to its fast inference speed. However, the generation quality of existing NAG models still lags behind their autoregressive counterparts. In this work, we show that BERT can be employed as the backbone of a NAG model to greatly improve performance. Additionally, we devise mechanisms to alleviate the two common problems of vanilla NAG models: the inflexibility of prefixed output length and the conditional independence of individual token predictions. Lastly, to further increase the speed advantage of the proposed model, we propose a new decoding strategy, ratio-first, for applications where the output lengths can be approximately estimated beforehand. For a comprehensive evaluation, we test the proposed model on three text generation tasks, including text summarization, sentence compression and machine translation. Experimental results show that our model significantly outperforms existing non-autoregressive baselines and achieves competitive performance with many strong autoregressive models. In addition, we also conduct extensive analysis experiments to reveal the effect of each proposed component.
Dialogue Response Selection with Hierarchical Curriculum Learning
Dec 29, 2020
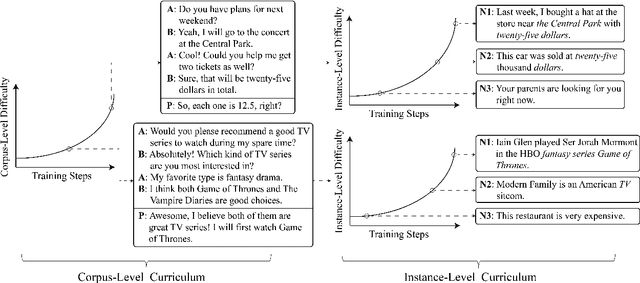
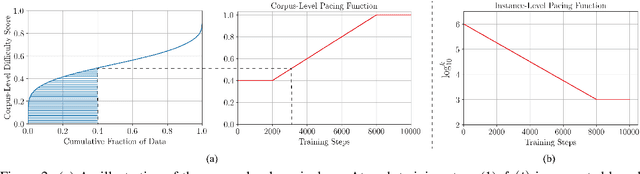
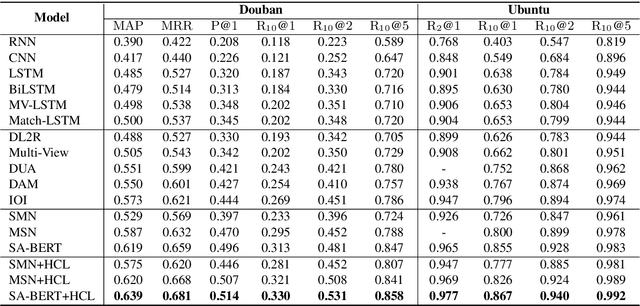
We study the learning of a matching model for dialogue response selection. Motivated by the recent finding that random negatives are often too trivial to train a reliable model, we propose a hierarchical curriculum learning (HCL) framework that consists of two complementary curricula: (1) corpus-level curriculum (CC); and (2) instance-level curriculum (IC). In CC, the model gradually increases its ability in finding the matching clues between the dialogue context and response. On the other hand, IC progressively strengthens the model's ability in identifying the mismatched information between the dialogue context and response. Empirical studies on two benchmark datasets with three state-of-the-art matching models demonstrate that the proposed HCL significantly improves the model performance across various evaluation metrics.
Prototype-to-Style: Dialogue Generation with Style-Aware Editing on Retrieval Memory
Apr 05, 2020
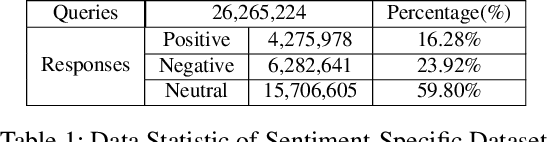

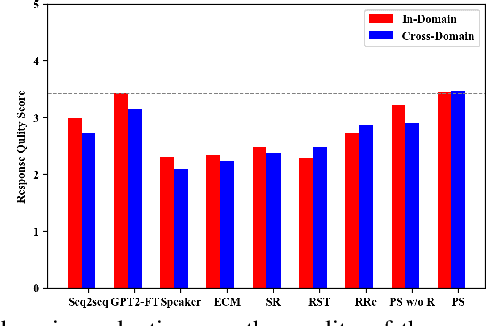
The ability of a dialog system to express prespecified language style during conversations has a direct, positive impact on its usability and on user satisfaction. We introduce a new prototype-to-style (PS) framework to tackle the challenge of stylistic dialogue generation. The framework uses an Information Retrieval (IR) system and extracts a response prototype from the retrieved response. A stylistic response generator then takes the prototype and the desired language style as model input to obtain a high-quality and stylistic response. To effectively train the proposed model, we propose a new style-aware learning objective as well as a de-noising learning strategy. Results on three benchmark datasets from two languages demonstrate that the proposed approach significantly outperforms existing baselines in both in-domain and cross-domain evaluations
Stylistic Dialogue Generation via Information-Guided Reinforcement Learning Strategy
Apr 05, 2020
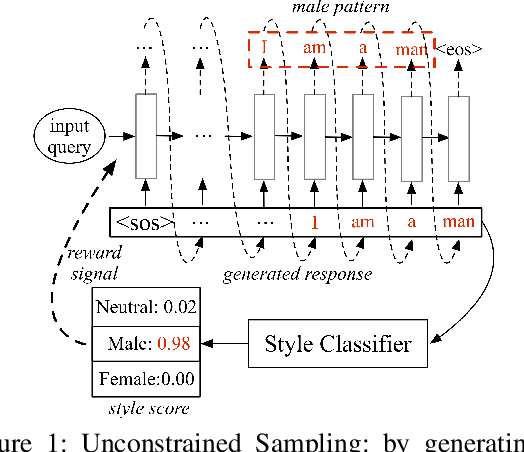
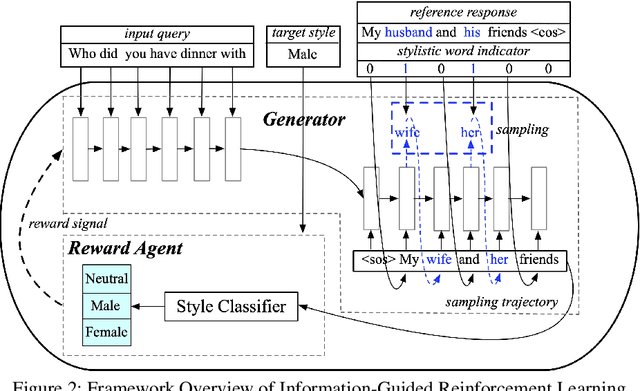
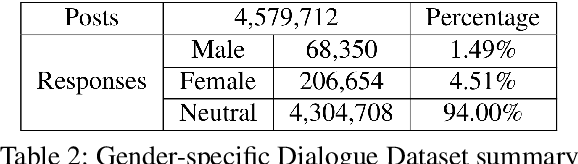
Stylistic response generation is crucial for building an engaging dialogue system for industrial use. While it has attracted much research interest, existing methods often generate stylistic responses at the cost of the content quality (relevance and fluency). To enable better balance between the content quality and the style, we introduce a new training strategy, know as Information-Guided Reinforcement Learning (IG-RL). In IG-RL, a training model is encouraged to explore stylistic expressions while being constrained to maintain its content quality. This is achieved by adopting reinforcement learning strategy with statistical style information guidance for quality-preserving explorations. Experiments on two datasets show that the proposed approach outperforms several strong baselines in terms of the overall response performance.
Multi-SimLex: A Large-Scale Evaluation of Multilingual and Cross-Lingual Lexical Semantic Similarity
Mar 10, 2020



We introduce Multi-SimLex, a large-scale lexical resource and evaluation benchmark covering datasets for 12 typologically diverse languages, including major languages (e.g., Mandarin Chinese, Spanish, Russian) as well as less-resourced ones (e.g., Welsh, Kiswahili). Each language dataset is annotated for the lexical relation of semantic similarity and contains 1,888 semantically aligned concept pairs, providing a representative coverage of word classes (nouns, verbs, adjectives, adverbs), frequency ranks, similarity intervals, lexical fields, and concreteness levels. Additionally, owing to the alignment of concepts across languages, we provide a suite of 66 cross-lingual semantic similarity datasets. Due to its extensive size and language coverage, Multi-SimLex provides entirely novel opportunities for experimental evaluation and analysis. On its monolingual and cross-lingual benchmarks, we evaluate and analyze a wide array of recent state-of-the-art monolingual and cross-lingual representation models, including static and contextualized word embeddings (such as fastText, M-BERT and XLM), externally informed lexical representations, as well as fully unsupervised and (weakly) supervised cross-lingual word embeddings. We also present a step-by-step dataset creation protocol for creating consistent, Multi-Simlex-style resources for additional languages. We make these contributions -- the public release of Multi-SimLex datasets, their creation protocol, strong baseline results, and in-depth analyses which can be be helpful in guiding future developments in multilingual lexical semantics and representation learning -- available via a website which will encourage community effort in further expansion of Multi-Simlex to many more languages. Such a large-scale semantic resource could inspire significant further advances in NLP across languages.