 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParameter choices in HaarPSI for IQA with medical images
Oct 31, 2024When developing machine learning models, image quality assessment (IQA) measures are a crucial component for evaluation. However, commonly used IQA measures have been primarily developed and optimized for natural images. In many specialized settings, such as medical images, this poses an often-overlooked problem regarding suitability. In previous studies, the IQA measure HaarPSI showed promising behavior for natural and medical images. HaarPSI is based on Haar wavelet representations and the framework allows optimization of two parameters. So far, these parameters have been aligned for natural images. Here, we optimize these parameters for two annotated medical data sets, a photoacoustic and a chest X-Ray data set. We observe that they are more sensitive to the parameter choices than the employed natural images, and on the other hand both medical data sets lead to similar parameter values when optimized. We denote the optimized setting, which improves the performance for the medical images notably, by HaarPSI$_{MED}$. The results suggest that adapting common IQA measures within their frameworks for medical images can provide a valuable, generalizable addition to the employment of more specific task-based measures.
Can Rule-Based Insights Enhance LLMs for Radiology Report Classification? Introducing the RadPrompt Methodology
Aug 07, 2024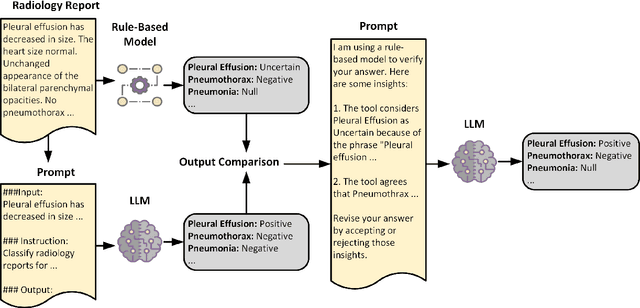
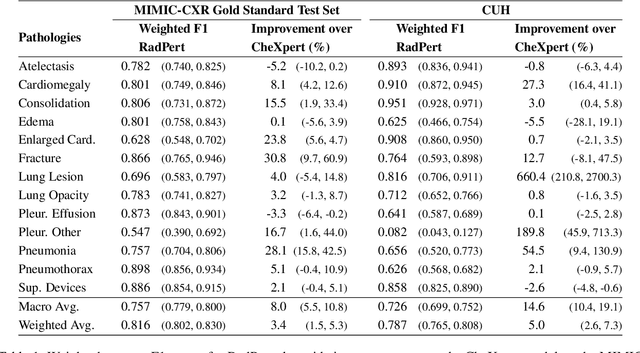
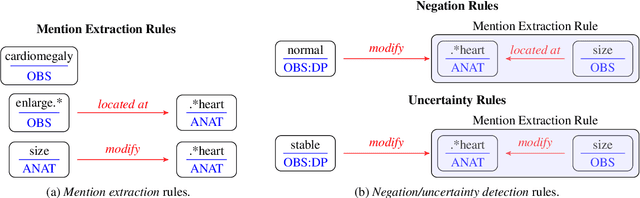
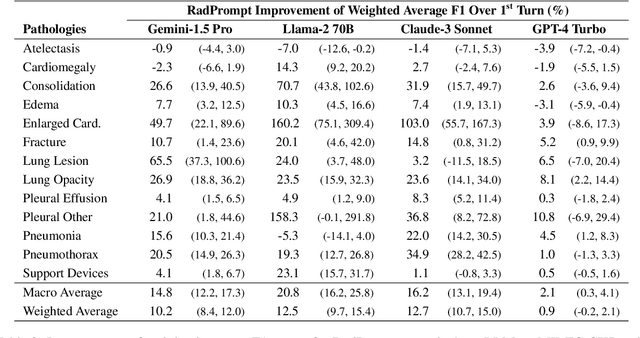
Developing imaging models capable of detecting pathologies from chest X-rays can be cost and time-prohibitive for large datasets as it requires supervision to attain state-of-the-art performance. Instead, labels extracted from radiology reports may serve as distant supervision since these are routinely generated as part of clinical practice. Despite their widespread use, current rule-based methods for label extraction rely on extensive rule sets that are limited in their robustness to syntactic variability. To alleviate these limitations, we introduce RadPert, a rule-based system that integrates an uncertainty-aware information schema with a streamlined set of rules, enhancing performance. Additionally, we have developed RadPrompt, a multi-turn prompting strategy that leverages RadPert to bolster the zero-shot predictive capabilities of large language models, achieving a statistically significant improvement in weighted average F1 score over GPT-4 Turbo. Most notably, RadPrompt surpasses both its underlying models, showcasing the synergistic potential of LLMs with rule-based models. We have evaluated our methods on two English Corpora: the MIMIC-CXR gold-standard test set and a gold-standard dataset collected from the Cambridge University Hospitals.
A study of why we need to reassess full reference image quality assessment with medical images
May 29, 2024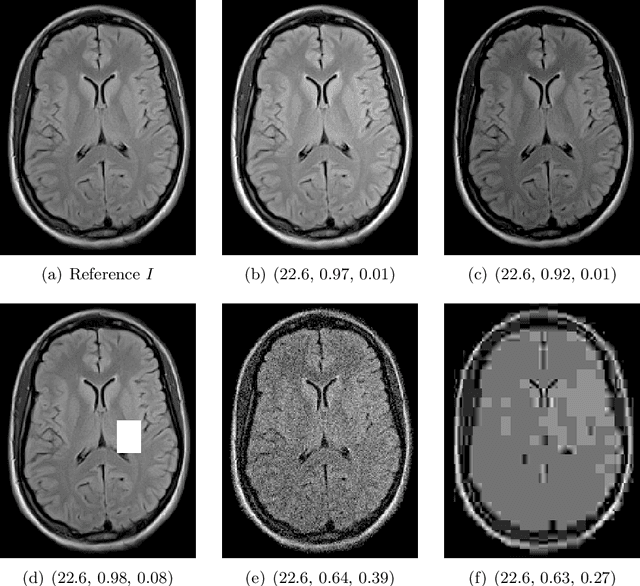
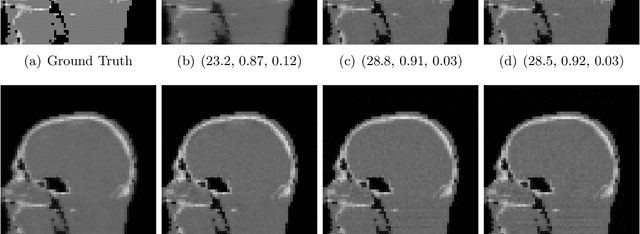
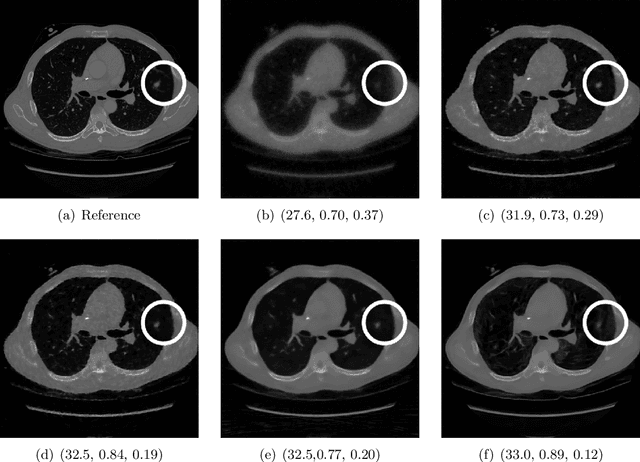

Image quality assessment (IQA) is not just indispensable in clinical practice to ensure high standards, but also in the development stage of novel algorithms that operate on medical images with reference data. This paper provides a structured and comprehensive collection of examples where the two most common full reference (FR) image quality measures prove to be unsuitable for the assessment of novel algorithms using different kinds of medical images, including real-world MRI, CT, OCT, X-Ray, digital pathology and photoacoustic imaging data. In particular, the FR-IQA measures PSNR and SSIM are known and tested for working successfully in many natural imaging tasks, but discrepancies in medical scenarios have been noted in the literature. Inconsistencies arising in medical images are not surprising, as they have very different properties than natural images which have not been targeted nor tested in the development of the mentioned measures, and therefore might imply wrong judgement of novel methods for medical images. Therefore, improvement is urgently needed in particular in this era of AI to increase explainability, reproducibility and generalizability in machine learning for medical imaging and beyond. On top of the pitfalls we will provide ideas for future research as well as suggesting guidelines for the usage of FR-IQA measures applied to medical images.
A study on the adequacy of common IQA measures for medical images
May 29, 2024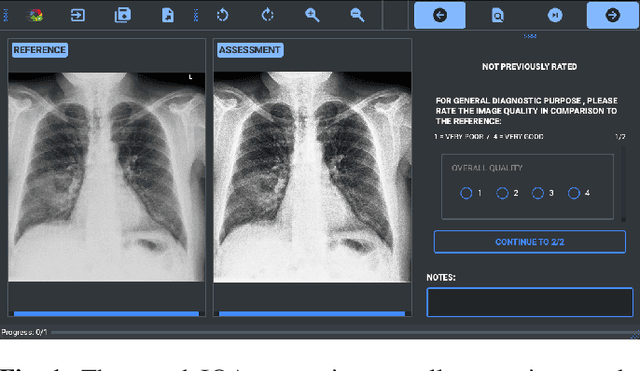
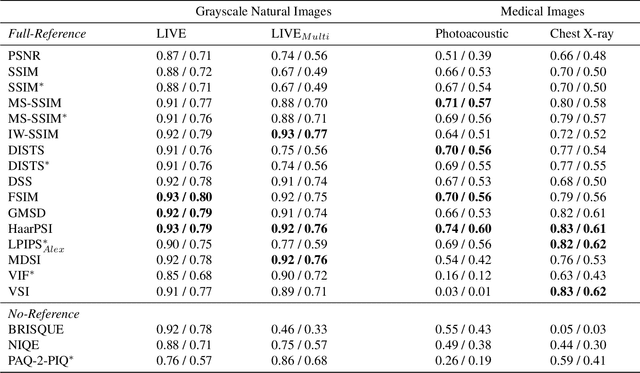
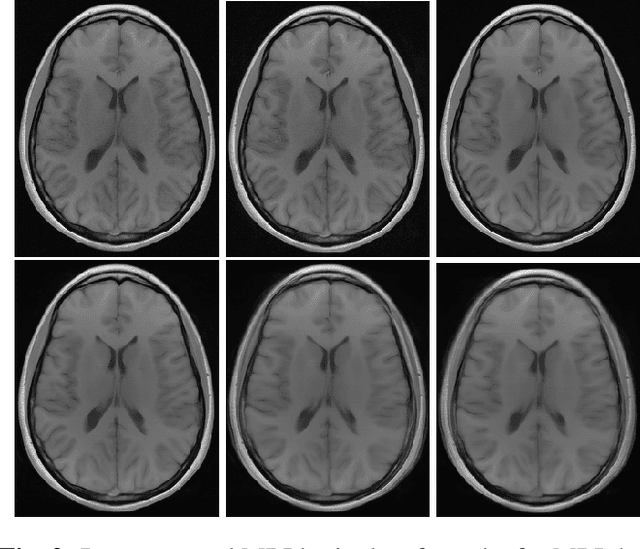
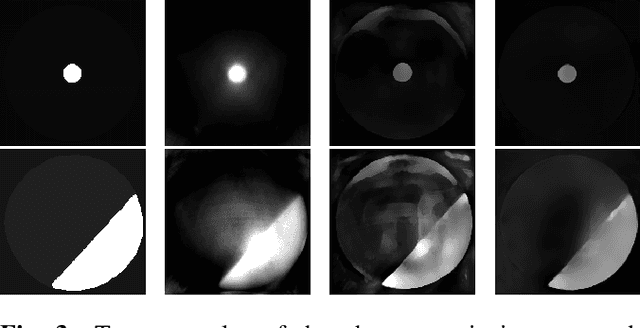
Image quality assessment (IQA) is standard practice in the development stage of novel machine learning algorithms that operate on images. The most commonly used IQA measures have been developed and tested for natural images, but not in the medical setting. Reported inconsistencies arising in medical images are not surprising, as they have different properties than natural images. In this study, we test the applicability of common IQA measures for medical image data by comparing their assessment to manually rated chest X-ray (5 experts) and photoacoustic image data (1 expert). Moreover, we include supplementary studies on grayscale natural images and accelerated brain MRI data. The results of all experiments show a similar outcome in line with previous findings for medical imaging: PSNR and SSIM in the default setting are in the lower range of the result list and HaarPSI outperforms the other tested measures in the overall performance. Also among the top performers in our medical experiments are the full reference measures DISTS, FSIM, LPIPS and MS-SSIM. Generally, the results on natural images yield considerably higher correlations, suggesting that the additional employment of tailored IQA measures for medical imaging algorithms is needed.
Data Harmonisation for Information Fusion in Digital Healthcare: A State-of-the-Art Systematic Review, Meta-Analysis and Future Research Directions
Jan 17, 2022

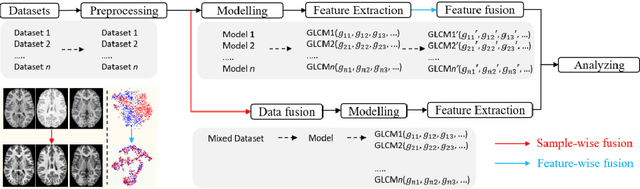
Removing the bias and variance of multicentre data has always been a challenge in large scale digital healthcare studies, which requires the ability to integrate clinical features extracted from data acquired by different scanners and protocols to improve stability and robustness. Previous studies have described various computational approaches to fuse single modality multicentre datasets. However, these surveys rarely focused on evaluation metrics and lacked a checklist for computational data harmonisation studies. In this systematic review, we summarise the computational data harmonisation approaches for multi-modality data in the digital healthcare field, including harmonisation strategies and evaluation metrics based on different theories. In addition, a comprehensive checklist that summarises common practices for data harmonisation studies is proposed to guide researchers to report their research findings more effectively. Last but not least, flowcharts presenting possible ways for methodology and metric selection are proposed and the limitations of different methods have been surveyed for future research.