 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiff3Dformer: Leveraging Slice Sequence Diffusion for Enhanced 3D CT Classification with Transformer Networks
Jun 24, 2024

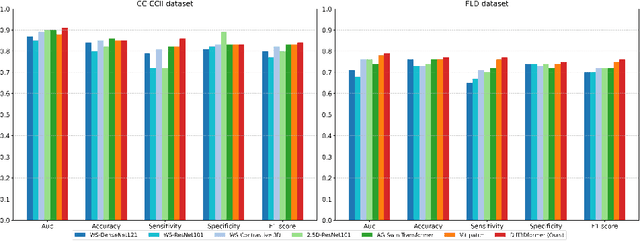

The manifestation of symptoms associated with lung diseases can vary in different depths for individual patients, highlighting the significance of 3D information in CT scans for medical image classification. While Vision Transformer has shown superior performance over convolutional neural networks in image classification tasks, their effectiveness is often demonstrated on sufficiently large 2D datasets and they easily encounter overfitting issues on small medical image datasets. To address this limitation, we propose a Diffusion-based 3D Vision Transformer (Diff3Dformer), which utilizes the latent space of the Diffusion model to form the slice sequence for 3D analysis and incorporates clustering attention into ViT to aggregate repetitive information within 3D CT scans, thereby harnessing the power of the advanced transformer in 3D classification tasks on small datasets. Our method exhibits improved performance on two different scales of small datasets of 3D lung CT scans, surpassing the state of the art 3D methods and other transformer-based approaches that emerged during the COVID-19 pandemic, demonstrating its robust and superior performance across different scales of data. Experimental results underscore the superiority of our proposed method, indicating its potential for enhancing medical image classification tasks in real-world scenarios.
DiffExplainer: Unveiling Black Box Models Via Counterfactual Generation
Jun 21, 2024



In the field of medical imaging, particularly in tasks related to early disease detection and prognosis, understanding the reasoning behind AI model predictions is imperative for assessing their reliability. Conventional explanation methods encounter challenges in identifying decisive features in medical image classifications, especially when discriminative features are subtle or not immediately evident. To address this limitation, we propose an agent model capable of generating counterfactual images that prompt different decisions when plugged into a black box model. By employing this agent model, we can uncover influential image patterns that impact the black model's final predictions. Through our methodology, we efficiently identify features that influence decisions of the deep black box. We validated our approach in the rigorous domain of medical prognosis tasks, showcasing its efficacy and potential to enhance the reliability of deep learning models in medical image classification compared to existing interpretation methods. The code will be publicly available at https://github.com/ayanglab/DiffExplainer.
Dynamic Multimodal Information Bottleneck for Multimodality Classification
Nov 06, 2023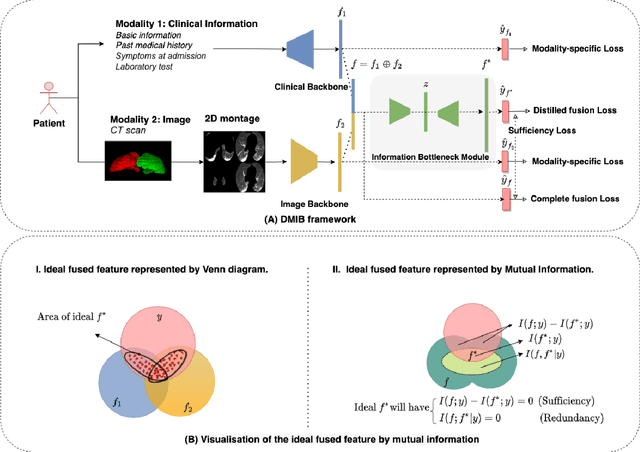

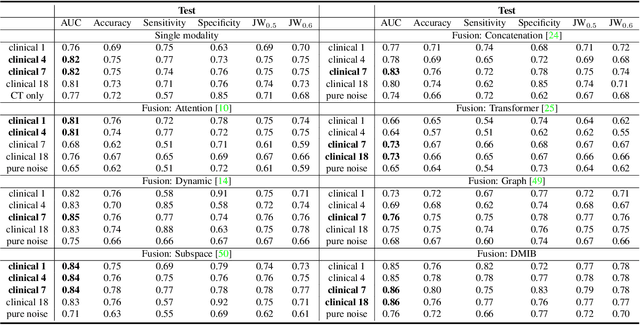
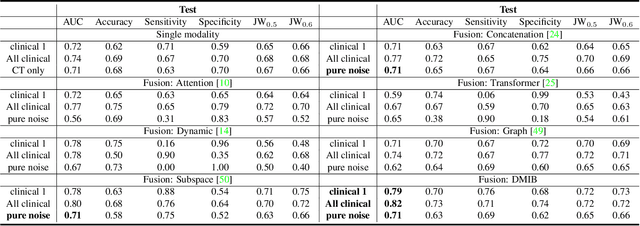
Effectively leveraging multimodal data such as various images, laboratory tests and clinical information is gaining traction in a variety of AI-based medical diagnosis and prognosis tasks. Most existing multi-modal techniques only focus on enhancing their performance by leveraging the differences or shared features from various modalities and fusing feature across different modalities. These approaches are generally not optimal for clinical settings, which pose the additional challenges of limited training data, as well as being rife with redundant data or noisy modality channels, leading to subpar performance. To address this gap, we study the robustness of existing methods to data redundancy and noise and propose a generalized dynamic multimodal information bottleneck framework for attaining a robust fused feature representation. Specifically, our information bottleneck module serves to filter out the task-irrelevant information and noises in the fused feature, and we further introduce a sufficiency loss to prevent dropping of task-relevant information, thus explicitly preserving the sufficiency of prediction information in the distilled feature. We validate our model on an in-house and a public COVID19 dataset for mortality prediction as well as two public biomedical datasets for diagnostic tasks. Extensive experiments show that our method surpasses the state-of-the-art and is significantly more robust, being the only method to remain performance when large-scale noisy channels exist. Our code is publicly available at https://github.com/BII-wushuang/DMIB.
High Accuracy and Cost-Saving Active Learning 3D WD-UNet for Airway Segmentation
Oct 09, 2023We propose a novel Deep Active Learning (DeepAL) model-3D Wasserstein Discriminative UNet (WD-UNet) for reducing the annotation effort of medical 3D Computed Tomography (CT) segmentation. The proposed WD-UNet learns in a semi-supervised way and accelerates learning convergence to meet or exceed the prediction metrics of supervised learning models. Our method can be embedded with different Active Learning (AL) strategies and different network structures. The model is evaluated on 3D lung airway CT scans for medical segmentation and show that the use of uncertainty metric, which is parametrized as an input of query strategy, leads to more accurate prediction results than some state-of-the-art Deep Learning (DL) supervised models, e.g.,3DUNet and 3D CEUNet. Compared to the above supervised DL methods, our WD-UNet not only saves the cost of annotation for radiologists but also saves computational resources. WD-UNet uses a limited amount of annotated data (35% of the total) to achieve better predictive metrics with a more efficient deep learning model algorithm.
Less is More: Unsupervised Mask-guided Annotated CT Image Synthesis with Minimum Manual Segmentations
Mar 19, 2023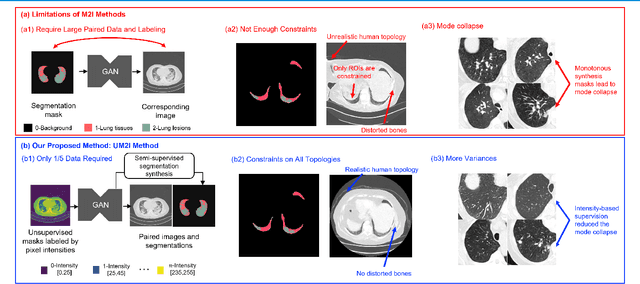
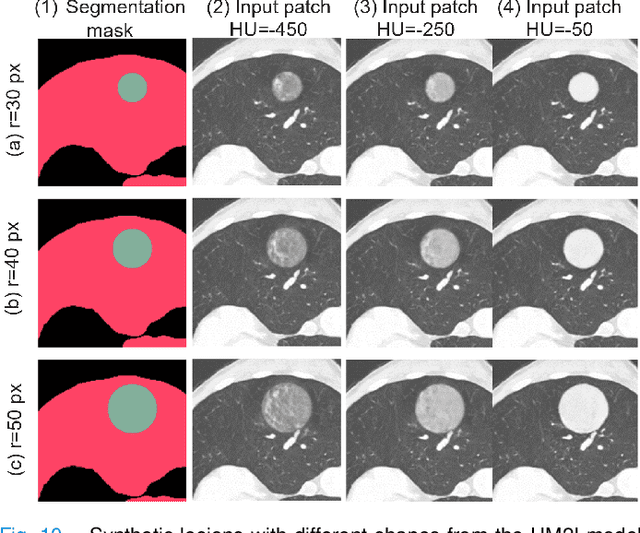
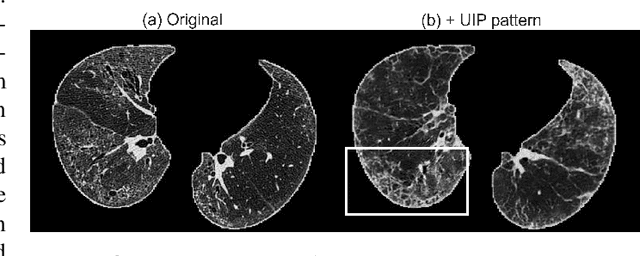
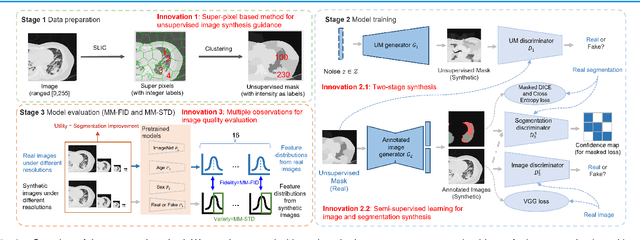
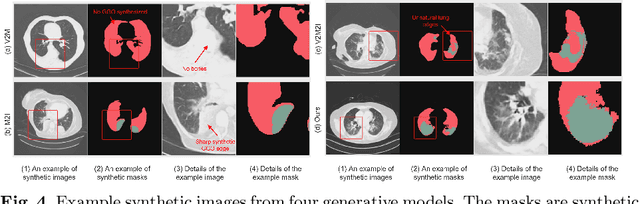
As a pragmatic data augmentation tool, data synthesis has generally returned dividends in performance for deep learning based medical image analysis. However, generating corresponding segmentation masks for synthetic medical images is laborious and subjective. To obtain paired synthetic medical images and segmentations, conditional generative models that use segmentation masks as synthesis conditions were proposed. However, these segmentation mask-conditioned generative models still relied on large, varied, and labeled training datasets, and they could only provide limited constraints on human anatomical structures, leading to unrealistic image features. Moreover, the invariant pixel-level conditions could reduce the variety of synthetic lesions and thus reduce the efficacy of data augmentation. To address these issues, in this work, we propose a novel strategy for medical image synthesis, namely Unsupervised Mask (UM)-guided synthesis, to obtain both synthetic images and segmentations using limited manual segmentation labels. We first develop a superpixel based algorithm to generate unsupervised structural guidance and then design a conditional generative model to synthesize images and annotations simultaneously from those unsupervised masks in a semi-supervised multi-task setting. In addition, we devise a multi-scale multi-task Fr\'echet Inception Distance (MM-FID) and multi-scale multi-task standard deviation (MM-STD) to harness both fidelity and variety evaluations of synthetic CT images. With multiple analyses on different scales, we could produce stable image quality measurements with high reproducibility. Compared with the segmentation mask guided synthesis, our UM-guided synthesis provided high-quality synthetic images with significantly higher fidelity, variety, and utility ($p<0.05$ by Wilcoxon Signed Ranked test).
Multi-site, Multi-domain Airway Tree Modeling : A Public Benchmark for Pulmonary Airway Segmentation
Mar 10, 2023



Open international challenges are becoming the de facto standard for assessing computer vision and image analysis algorithms. In recent years, new methods have extended the reach of pulmonary airway segmentation that is closer to the limit of image resolution. Since EXACT'09 pulmonary airway segmentation, limited effort has been directed to quantitative comparison of newly emerged algorithms driven by the maturity of deep learning based approaches and clinical drive for resolving finer details of distal airways for early intervention of pulmonary diseases. Thus far, public annotated datasets are extremely limited, hindering the development of data-driven methods and detailed performance evaluation of new algorithms. To provide a benchmark for the medical imaging community, we organized the Multi-site, Multi-domain Airway Tree Modeling (ATM'22), which was held as an official challenge event during the MICCAI 2022 conference. ATM'22 provides large-scale CT scans with detailed pulmonary airway annotation, including 500 CT scans (300 for training, 50 for validation, and 150 for testing). The dataset was collected from different sites and it further included a portion of noisy COVID-19 CTs with ground-glass opacity and consolidation. Twenty-three teams participated in the entire phase of the challenge and the algorithms for the top ten teams are reviewed in this paper. Quantitative and qualitative results revealed that deep learning models embedded with the topological continuity enhancement achieved superior performance in general. ATM'22 challenge holds as an open-call design, the training data and the gold standard evaluation are available upon successful registration via its homepage.
Non-Imaging Medical Data Synthesis for Trustworthy AI: A Comprehensive Survey
Sep 17, 2022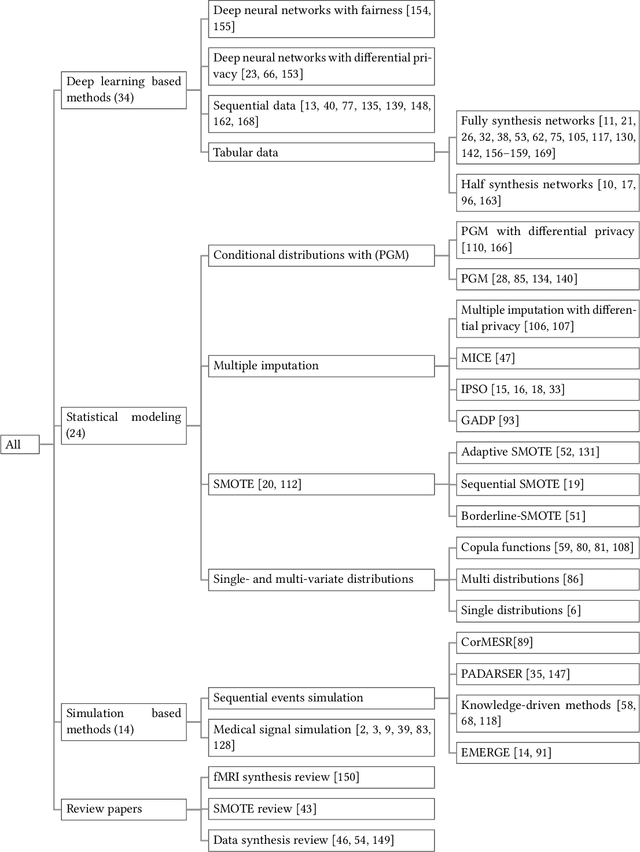

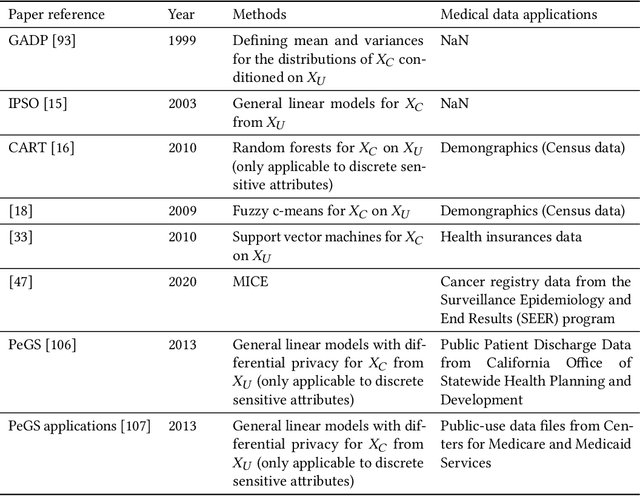
Data quality is the key factor for the development of trustworthy AI in healthcare. A large volume of curated datasets with controlled confounding factors can help improve the accuracy, robustness and privacy of downstream AI algorithms. However, access to good quality datasets is limited by the technical difficulty of data acquisition and large-scale sharing of healthcare data is hindered by strict ethical restrictions. Data synthesis algorithms, which generate data with a similar distribution as real clinical data, can serve as a potential solution to address the scarcity of good quality data during the development of trustworthy AI. However, state-of-the-art data synthesis algorithms, especially deep learning algorithms, focus more on imaging data while neglecting the synthesis of non-imaging healthcare data, including clinical measurements, medical signals and waveforms, and electronic healthcare records (EHRs). Thus, in this paper, we will review the synthesis algorithms, particularly for non-imaging medical data, with the aim of providing trustworthy AI in this domain. This tutorial-styled review paper will provide comprehensive descriptions of non-imaging medical data synthesis on aspects including algorithms, evaluations, limitations and future research directions.
Fuzzy Attention Neural Network to Tackle Discontinuity in Airway Segmentation
Sep 09, 2022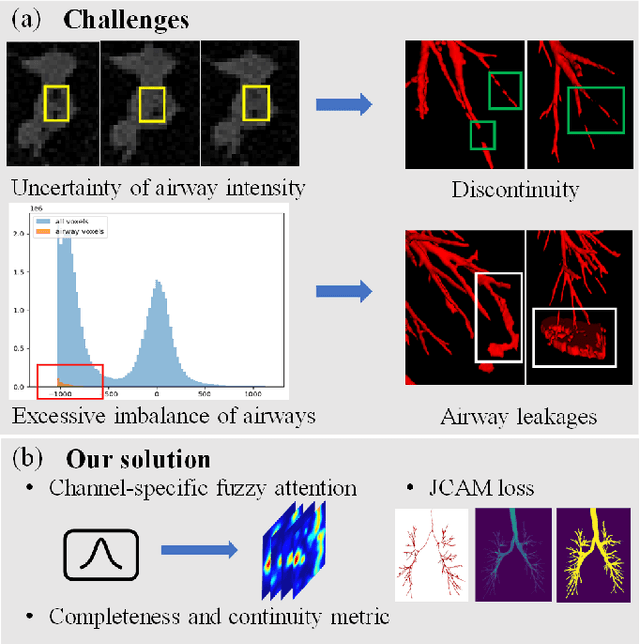
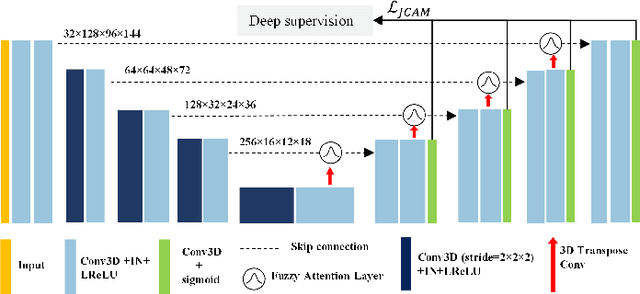
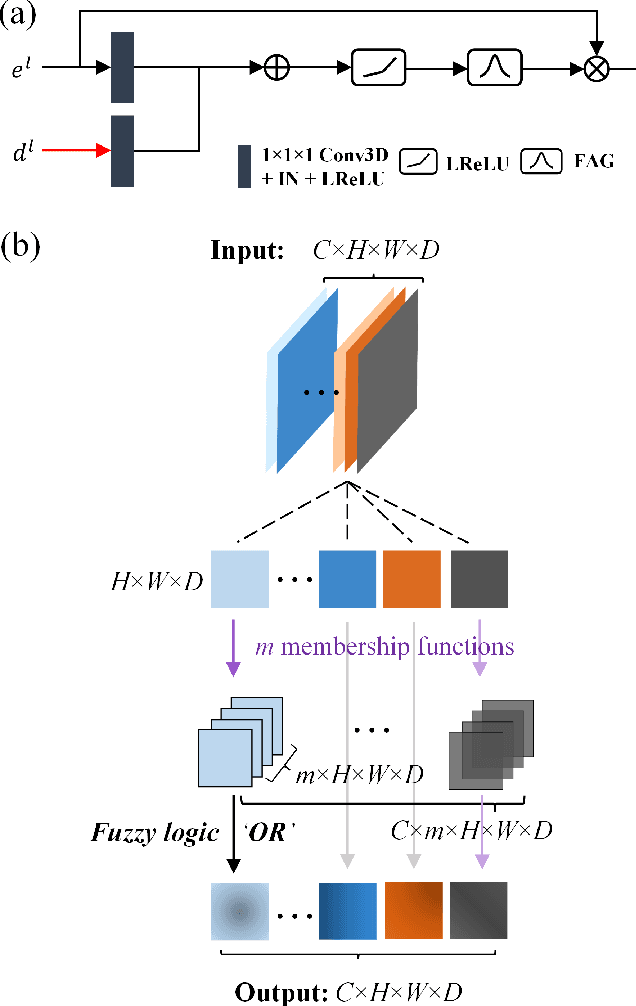
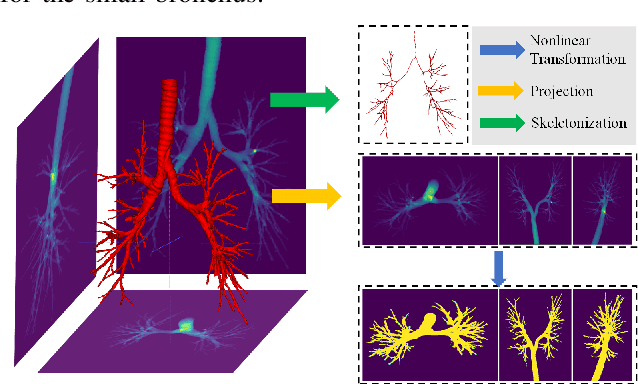
Airway segmentation is crucial for the examination, diagnosis, and prognosis of lung diseases, while its manual delineation is unduly burdensome. To alleviate this time-consuming and potentially subjective manual procedure, researchers have proposed methods to automatically segment airways from computerized tomography (CT) images. However, some small-sized airway branches (e.g., bronchus and terminal bronchioles) significantly aggravate the difficulty of automatic segmentation by machine learning models. In particular, the variance of voxel values and the severe data imbalance in airway branches make the computational module prone to discontinuous and false-negative predictions. especially for cohorts with different lung diseases. Attention mechanism has shown the capacity to segment complex structures, while fuzzy logic can reduce the uncertainty in feature representations. Therefore, the integration of deep attention networks and fuzzy theory, given by the fuzzy attention layer, should be an escalated solution for better generalization and robustness. This paper presents an efficient method for airway segmentation, comprising a novel fuzzy attention neural network and a comprehensive loss function to enhance the spatial continuity of airway segmentation. The deep fuzzy set is formulated by a set of voxels in the feature map and a learnable Gaussian membership function. Different from the existing attention mechanism, the proposed channel-specific fuzzy attention addresses the issue of heterogeneous features in different channels. Furthermore, a novel evaluation metric is proposed to assess both the continuity and completeness of airway structures. The efficiency, generalization and robustness of the proposed method have been proved by training on normal lung disease while testing on datasets of lung cancer, COVID-19 and pulmonary fibrosis.
CS$^2$: A Controllable and Simultaneous Synthesizer of Images and Annotations with Minimal Human Intervention
Jun 20, 2022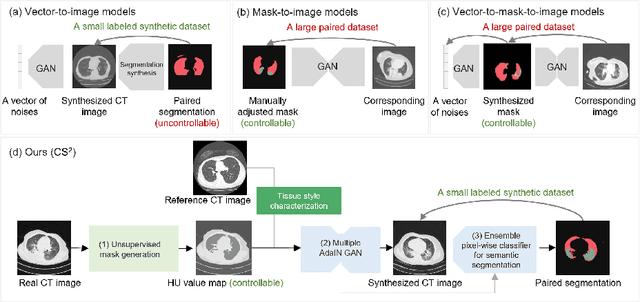
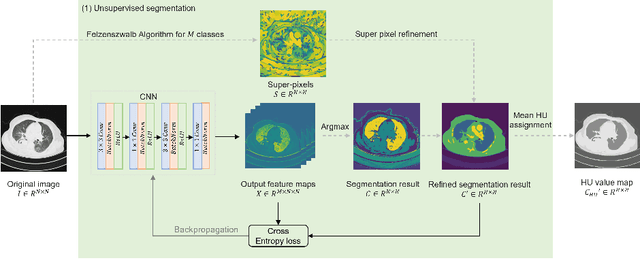

The destitution of image data and corresponding expert annotations limit the training capacities of AI diagnostic models and potentially inhibit their performance. To address such a problem of data and label scarcity, generative models have been developed to augment the training datasets. Previously proposed generative models usually require manually adjusted annotations (e.g., segmentation masks) or need pre-labeling. However, studies have found that these pre-labeling based methods can induce hallucinating artifacts, which might mislead the downstream clinical tasks, while manual adjustment could be onerous and subjective. To avoid manual adjustment and pre-labeling, we propose a novel controllable and simultaneous synthesizer (dubbed CS$^2$) in this study to generate both realistic images and corresponding annotations at the same time. Our CS$^2$ model is trained and validated using high resolution CT (HRCT) data collected from COVID-19 patients to realize an efficient infections segmentation with minimal human intervention. Our contributions include 1) a conditional image synthesis network that receives both style information from reference CT images and structural information from unsupervised segmentation masks, and 2) a corresponding segmentation mask synthesis network to automatically segment these synthesized images simultaneously. Our experimental studies on HRCT scans collected from COVID-19 patients demonstrate that our CS$^2$ model can lead to realistic synthesized datasets and promising segmentation results of COVID infections compared to the state-of-the-art nnUNet trained and fine-tuned in a fully supervised manner.
Explainable COVID-19 Infections Identification and Delineation Using Calibrated Pseudo Labels
Feb 11, 2022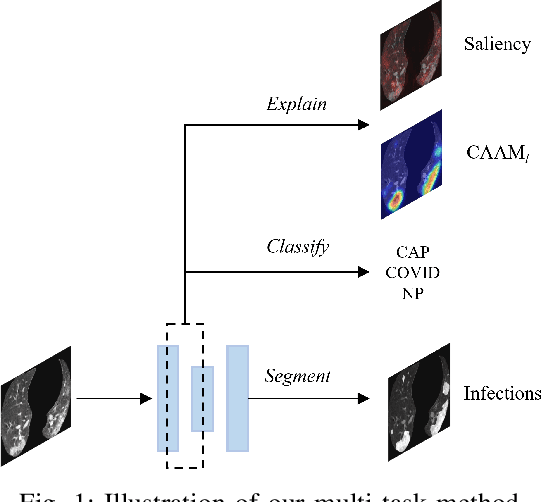
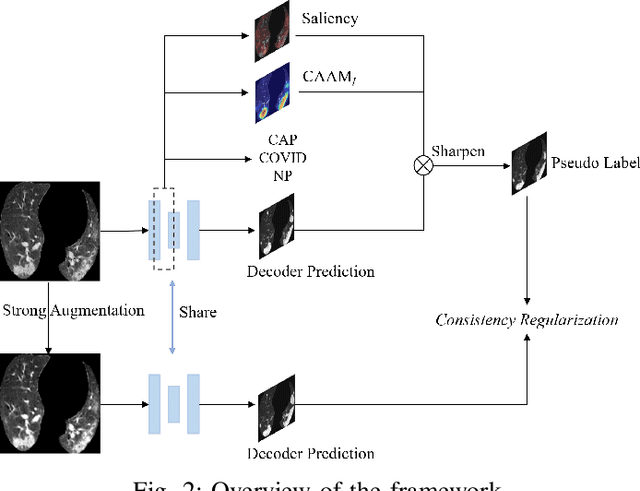
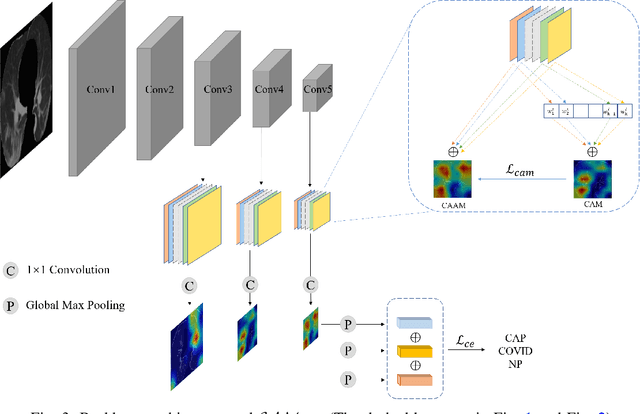
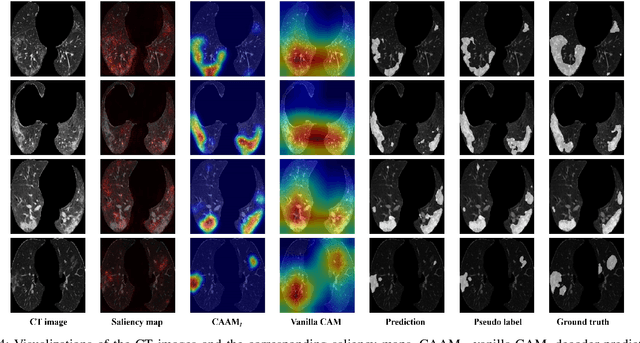
The upheaval brought by the arrival of the COVID-19 pandemic has continued to bring fresh challenges over the past two years. During this COVID-19 pandemic, there has been a need for rapid identification of infected patients and specific delineation of infection areas in computed tomography (CT) images. Although deep supervised learning methods have been established quickly, the scarcity of both image-level and pixellevel labels as well as the lack of explainable transparency still hinder the applicability of AI. Can we identify infected patients and delineate the infections with extreme minimal supervision? Semi-supervised learning (SSL) has demonstrated promising performance under limited labelled data and sufficient unlabelled data. Inspired by SSL, we propose a model-agnostic calibrated pseudo-labelling strategy and apply it under a consistency regularization framework to generate explainable identification and delineation results. We demonstrate the effectiveness of our model with the combination of limited labelled data and sufficient unlabelled data or weakly-labelled data. Extensive experiments have shown that our model can efficiently utilize limited labelled data and provide explainable classification and segmentation results for decision-making in clinical routine.