 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiff3Dformer: Leveraging Slice Sequence Diffusion for Enhanced 3D CT Classification with Transformer Networks
Paper and Code
Jun 24, 2024

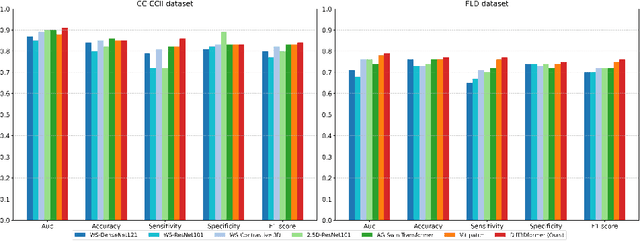

The manifestation of symptoms associated with lung diseases can vary in different depths for individual patients, highlighting the significance of 3D information in CT scans for medical image classification. While Vision Transformer has shown superior performance over convolutional neural networks in image classification tasks, their effectiveness is often demonstrated on sufficiently large 2D datasets and they easily encounter overfitting issues on small medical image datasets. To address this limitation, we propose a Diffusion-based 3D Vision Transformer (Diff3Dformer), which utilizes the latent space of the Diffusion model to form the slice sequence for 3D analysis and incorporates clustering attention into ViT to aggregate repetitive information within 3D CT scans, thereby harnessing the power of the advanced transformer in 3D classification tasks on small datasets. Our method exhibits improved performance on two different scales of small datasets of 3D lung CT scans, surpassing the state of the art 3D methods and other transformer-based approaches that emerged during the COVID-19 pandemic, demonstrating its robust and superior performance across different scales of data. Experimental results underscore the superiority of our proposed method, indicating its potential for enhancing medical image classification tasks in real-world scenarios.